Downloaded 42 times

















































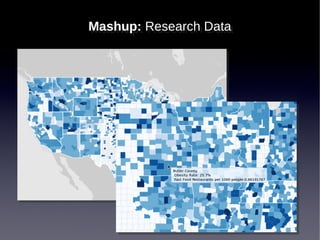



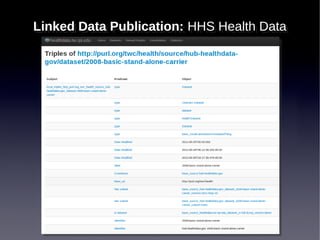
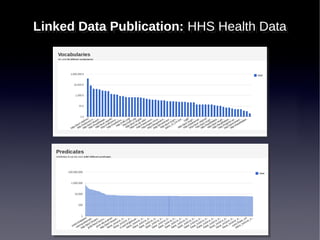




![[data integration/data science]](https://image.slidesharecdn.com/itwscapstonespring2013-130409133303-phpapp02/85/ITWS-Capstone-Lecture-Spring-2013-69-320.jpg)

![[data integration/data science]](https://image.slidesharecdn.com/itwscapstonespring2013-130409133303-phpapp02/85/ITWS-Capstone-Lecture-Spring-2013-71-320.jpg)













The document summarizes a lecture on the Semantic Web. It introduces key concepts like RDF, SPARQL, Linked Data, and how they enable data integration and mashups. It also discusses some advanced ideas like ontology, inference, and reasoning that could be useful for students in graduate school or careers. The purpose is to provide an overview of the Semantic Web and how its technologies work.









































































