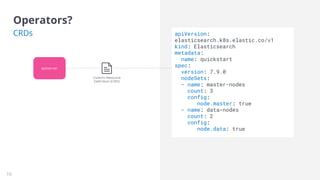
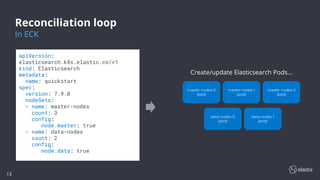
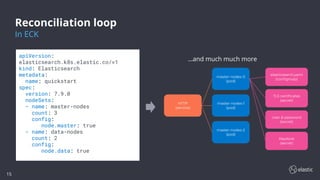
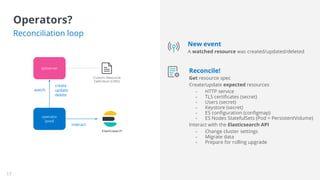
This document discusses the challenges of running the Elastic Stack on Kubernetes and introduces Elastic Cloud on Kubernetes (ECK) as a solution. ECK uses operators to deploy and manage Elasticsearch, Kibana, APM Server, and other Elastic products on Kubernetes. The operator watches custom resources, and its reconciliation loop automatically handles tasks like creating pods, configmaps, secrets, services and managing upgrades/scaling without downtime or data loss. ECK provides simplified configuration, security, high availability, and automation to make running Elastic Stack on Kubernetes easier.













![18
apiVersion: elasticsearch.k8s.elastic.co/v1beta1
kind: Elasticsearch
metadata:
name: elasticsearch-sample
spec:
version: 7.9.0
nodeSets:
- name: default
count: 1
podTemplate:
metadata:
labels: {“foo”: “bar”}
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: environment
operator: In
values: [“e2e”, “production”]
containers:
- name: elasticsearch
env:
- name: ES_JAVA_OPTS
value: “-Xms2g -Xmx4g”
Empower users
But provide good defaults
optional podTemplate](https://image.slidesharecdn.com/runtheelasticstackonkuberneteswitheck-meetupitalysep2020-201007072104/85/Run-the-elastic-stack-on-kubernetes-with-eck-18-320.jpg)


























![[1A7]Ansible의이해와활용](https://cdn.slidesharecdn.com/ss_thumbnails/1a7ansible-140928232208-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























































