Downloaded 43 times







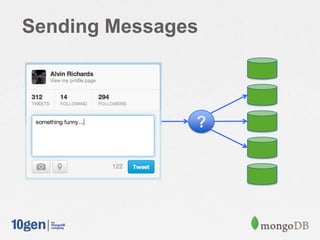


![Fan out on read – Send
Message
Shard 1 Shard 2 Shard 3
Send
Message
db.inbox.save(
{ to: [ "Bob", "Jane" ], … } )](https://image.slidesharecdn.com/schematrickstips-130516192927-phpapp01/85/MongoDB-San-Francisco-2013-Data-Modeling-Examples-From-the-Real-World-presented-by-Alvin-Richards-10Gen-Technical-Director-for-EMEA-10gen-11-320.jpg)
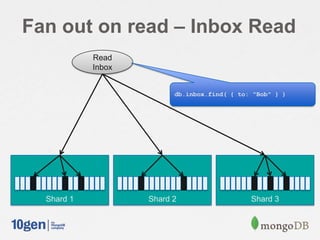
![// Shard on "from"
db.shardCollection( "mongodbdays.inbox", { from: 1 } )
// Make sure we have an index to handle inbox reads
db.inbox.ensureIndex( { to: 1, sent: 1 } )
msg = {
from: "Joe",
to: [ "Bob", "Jane" ],
sent: new Date(),
message: "Hi!",
}
// Send a message
db.inbox.save( msg )
// Read my inbox
db.inbox.find( { to: "Bob" } ).sort( { sent: -1 } )
Fan out on read](https://image.slidesharecdn.com/schematrickstips-130516192927-phpapp01/85/MongoDB-San-Francisco-2013-Data-Modeling-Examples-From-the-Real-World-presented-by-Alvin-Richards-10Gen-Technical-Director-for-EMEA-10gen-13-320.jpg)

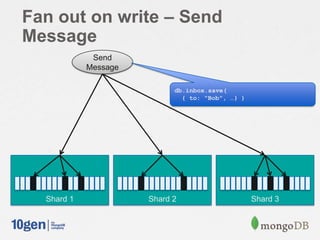
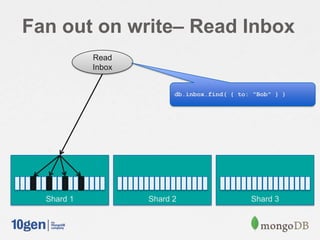
![// Shard on “recipient” and “sent”
db.shardCollection( "mongodbdays.inbox", { ”recipient”: 1, ”sent”: 1 } )
msg = {
from: "Joe”,
recipient: [ "Bob", "Jane" ],
sent: new Date(),
message: "Hi!",
}
// Send a message
for ( recipient in msg.recipient ) {
msg.to = recipient
db.inbox.save( msg );
}
// Read my inbox
db.inbox.find( { to: "Joe" } ).sort( { sent: -1 } )
Fan out on write](https://image.slidesharecdn.com/schematrickstips-130516192927-phpapp01/85/MongoDB-San-Francisco-2013-Data-Modeling-Examples-From-the-Real-World-presented-by-Alvin-Richards-10Gen-Technical-Director-for-EMEA-10gen-17-320.jpg)


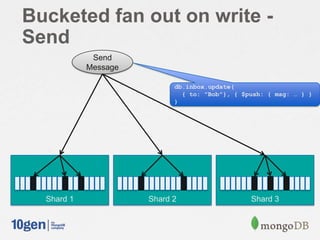
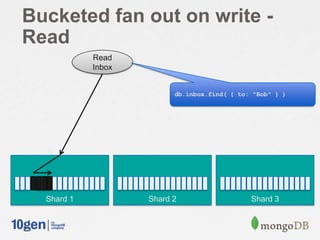
![// Shard on “owner / sequence”
db.shardCollection( "mongodbdays.inbox", { owner: 1, sequence: 1 } )
db.shardCollection( "mongodbdays.users", { user_name: 1 } )
msg = {
from: "Joe",
to: [ "Bob", "Jane" ],
sent: new Date(),
message: "Hi!",
}
// Send a message
for( recipient in msg.to) {
count = db.users.findAndModify({
query: { user_name: msg.to[recipient] },
update: { "$inc": { "msg_count": 1 } },
upsert: true,
new: true }).msg_count;
sequence = Math.floor(count / 50);
db.inbox.update( { to: msg.to[recipient], sequence: sequence },
{ $push: { "messages": msg } },
{ upsert: true } );
}
// Read my inbox
db.inbox.find( { to: "Joe" } ).sort ( { sequence: -1 } ).limit( 2 )
Fan out on write – with
buckets](https://image.slidesharecdn.com/schematrickstips-130516192927-phpapp01/85/MongoDB-San-Francisco-2013-Data-Modeling-Examples-From-the-Real-World-presented-by-Alvin-Richards-10Gen-Technical-Director-for-EMEA-10gen-22-320.jpg)



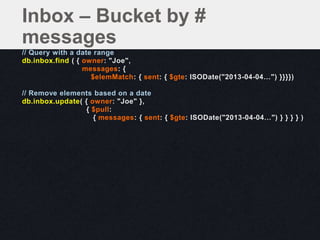
![Considerations
Limited to a known range of messages
✖Shrinking documents
• space can be reclaimed with
db.runCommand ( { compact: '<collection>' } )
✖Removing the document after the last element
in the array as been removed
– { "_id" : …, "messages" : [ ], "owner" :
"friend1", "sequence" : 0 }](https://image.slidesharecdn.com/schematrickstips-130516192927-phpapp01/85/MongoDB-San-Francisco-2013-Data-Modeling-Examples-From-the-Real-World-presented-by-Alvin-Richards-10Gen-Technical-Director-for-EMEA-10gen-27-320.jpg)
![msg = {
from: "Your Boss",
to: [ "Bob" ],
sent: new Date(),
message: "CALL ME NOW!"
}
// 2.4 Introduces $each, $sort and $slice for $push
db.messages.update(
{ _id: 1 },
{ $push: { messages: { $each: [ msg ],
$sort: { sent: 1 },
$slice: -50
}
}
}
)
Maintain the latest – Fixed
Size Array
Push this object
onto the array
Sort the resulting
array by "sent"
Limit the array to
50 elements](https://image.slidesharecdn.com/schematrickstips-130516192927-phpapp01/85/MongoDB-San-Francisco-2013-Data-Modeling-Examples-From-the-Real-World-presented-by-Alvin-Richards-10Gen-Technical-Director-for-EMEA-10gen-28-320.jpg)

![// messages: one doc per user per day
db.inbox.findOne()
{
_id: 1,
to: "Joe",
sequence: ISODate("2013-02-04T00:00:00.392Z"),
messages: [ ]
}
// Auto expires data after 31536000 seconds = 1 year
db.messages.ensureIndex( { sequence: 1 },
{ expireAfterSeconds: 31536000 } )
TTL Collections](https://image.slidesharecdn.com/schematrickstips-130516192927-phpapp01/85/MongoDB-San-Francisco-2013-Data-Modeling-Examples-From-the-Real-World-presented-by-Alvin-Richards-10Gen-Technical-Director-for-EMEA-10gen-30-320.jpg)




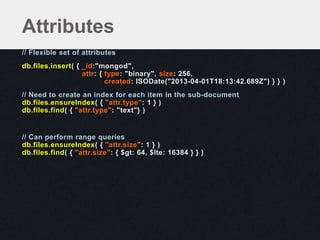

![// Flexible set of attributes, each attribute is an object
db.files.insert( { _id: "mongod",
attr: [ { type: "binary" },
{ size: 256 },
{ created: ISODate("2013-04-01T18:13:42.689Z") } ] } )
db.files.ensureIndex( { attr: 1 } )
Attributes as Objects in Array](https://image.slidesharecdn.com/schematrickstips-130516192927-phpapp01/85/MongoDB-San-Francisco-2013-Data-Modeling-Examples-From-the-Real-World-presented-by-Alvin-Richards-10Gen-Technical-Director-for-EMEA-10gen-37-320.jpg)
![// Range queries
db.files.find( { attr: { $gt: { size:64 }, $lte: { size: 16384 } } } )
db.files.find( { attr:
{ $gte: { created: ISODate("2013-02-01T00:00:01.689Z") } } } )
// Multiple condition – Only the first predicate on the query can use the Index
// ensure that this is the most selective.
// Index Intersection will allow multiple indexes, see SERVER-3071
db.files.find( { $and: [ { attr: { $gte: { created: ISODate("2013-02-01T…") } } },
{ attr: { $gt: { size:128 }, $lte: { size: 16384 } } }
] } )
// Each $or can use an index
db.files.find( { $or: [ { attr: { $gte: { created: ISODate("2013-02-01T…") } } },
{ attr: { $gt: { size:128 }, $lte: { size: 16384 } } }
] } )
Queries](https://image.slidesharecdn.com/schematrickstips-130516192927-phpapp01/85/MongoDB-San-Francisco-2013-Data-Modeling-Examples-From-the-Real-World-presented-by-Alvin-Richards-10Gen-Technical-Director-for-EMEA-10gen-38-320.jpg)






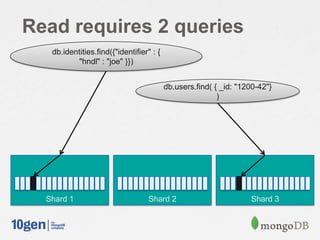





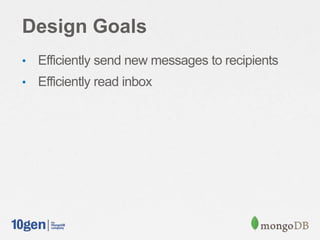
The document discusses the importance of schema design in MongoDB, emphasizing how it differs from traditional relational databases. It outlines three real-world use cases of message inbox systems, detailing different approaches for handling message storage and retrieval efficiently. The speaker highlights considerations of performance, flexibility, and indexing options while modeling domain problems.






















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)























