Downloaded 41 times







![Should you embed comments?
{
title : “MongoDB is fun” ,
author : “eliot” ,
date : “2010-12-03” ,
comments : [
{ author : “bob” , text : “...” } ,
{ author : “joe” , text : “...” }
]
}
db.posts.update( { title : “MongoDB is fun” } ,
{ $push : { author : “sam” , text : “...” } } )](https://image.slidesharecdn.com/2010-mongosv-scaling-101214134055-phpapp01/85/Scaling-with-MongoDB-7-320.jpg)











![Use Case: User Profiles
{ email : “eliot@10gen.com” ,
addresses : [ { state : “NY” } ]
}
• Shard by email
• Lookup by email hits 1 node
• Index on { “addresses.state” : 1 }](https://image.slidesharecdn.com/2010-mongosv-scaling-101214134055-phpapp01/85/Scaling-with-MongoDB-22-320.jpg)



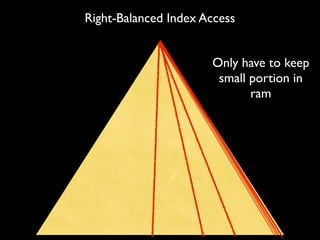


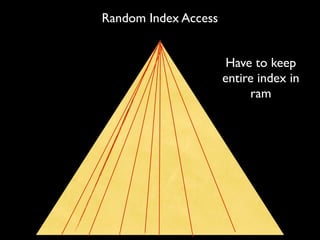
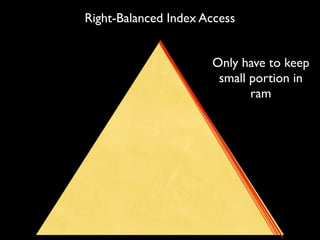
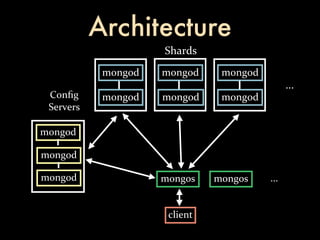
This document summarizes strategies for scaling MongoDB databases. It discusses scaling through optimization techniques like schema design, indexing, and hardware configuration. It also covers horizontal scaling by adding shards. Specific topics covered include choosing a shard key, embedding data vs references, index design, and hardware considerations like disk and network performance. Replica sets and sharding architectures are presented as solutions for scaling reads and writes.

























![[PASS Summit 2016] Azure DocumentDB: A Deep Dive into Advanced Features](https://cdn.slidesharecdn.com/ss_thumbnails/passdocdbadvfeatures-161029023827-thumbnail.jpg?width=640&height=640&fit=bounds)











































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































