Downloaded 219 times













![1 - Arrays
[
1, 2, 3, "four",
5, "six", [ 7, 8, 9 ]
]](https://image.slidesharecdn.com/thinkingindocuments-140529173742-phpapp02/75/Back-to-Basics-1-Thinking-in-documents-16-2048.jpg)
















![One to Many
Schema Design Choices
contact
• phone_ids: [ ]
phone1 N
contact phone
• contact_id1 N
Redundant to track relationship on both sides
• Both references must be updated for consistency
• Not possible in relational DBs
• Save a fetch?
Contact
• phones
phone N](https://image.slidesharecdn.com/thinkingindocuments-140529173742-phpapp02/75/Back-to-Basics-1-Thinking-in-documents-40-2048.jpg)

![Many to Many
Schema Design Choices
group
• contact_ids: [ ]
contactN N
group
contact
• group_ids: [
]
N N
Redundant to track
relationship on both sides
• Both references must be
updated for consistency
Redundant to track
relationship on both sides
• Duplicated data must be
updated for consistency
group
• contacts
contact
N
contact
• groups
group
N](https://image.slidesharecdn.com/thinkingindocuments-140529173742-phpapp02/75/Back-to-Basics-1-Thinking-in-documents-44-2048.jpg)
![Many to Many
General Recommendation
• Depends on use case
1. Simple address book
• Contact references groups
2. Corporate email groups
• Group embeds contacts for performance
• Exceptional cases
– Scaling: maximum document size is 16MB
– Scaling may affect performance and working set
group
contact
• group_ids: [
]
N N](https://image.slidesharecdn.com/thinkingindocuments-140529173742-phpapp02/75/Back-to-Basics-1-Thinking-in-documents-45-2048.jpg)






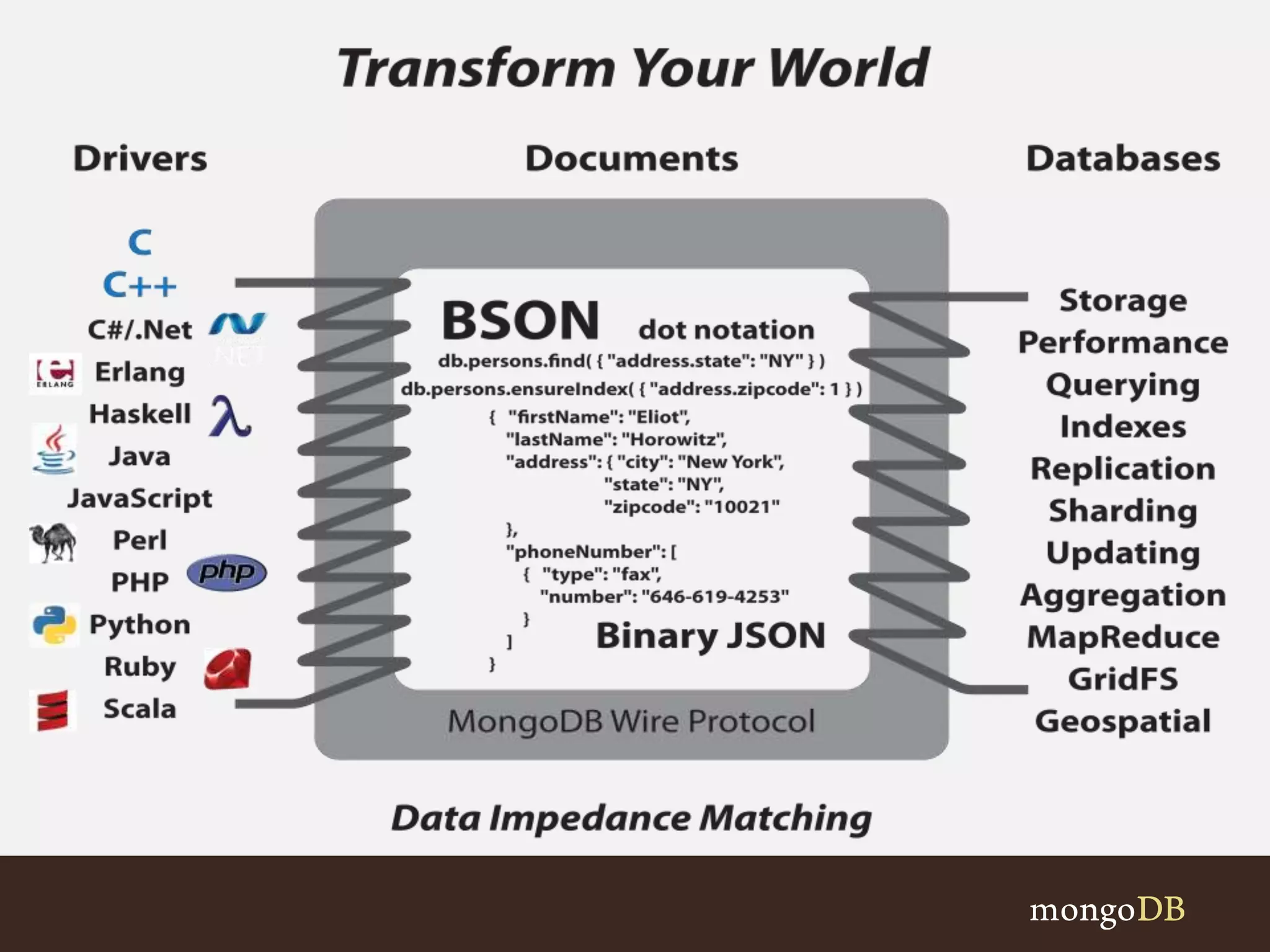

This document discusses document databases and schema design when modeling data. It introduces key concepts like embedding related data within documents for optimal performance and flexibility compared to traditional relational schemas. Examples are provided for how to model one-to-one, one-to-many, and many-to-many relationships either through embedding or referencing other documents. General recommendations suggest embedding by default for relationships where related data is often accessed together, while referencing may be better for scaling or inconsistent many-to-many relationships. The goal is to design schemas that match how the application will use the data for best results.
Introduction of Mike Friedman, a Perl Engineer at MongoDB, emphasizing the importance of thinking in documents.
Overview of the presentation agenda, highlighting key topics like Records, Entities, and Schema Design.
Emphasis on Schema Design as a critical aspect of application development for proper data structuring.
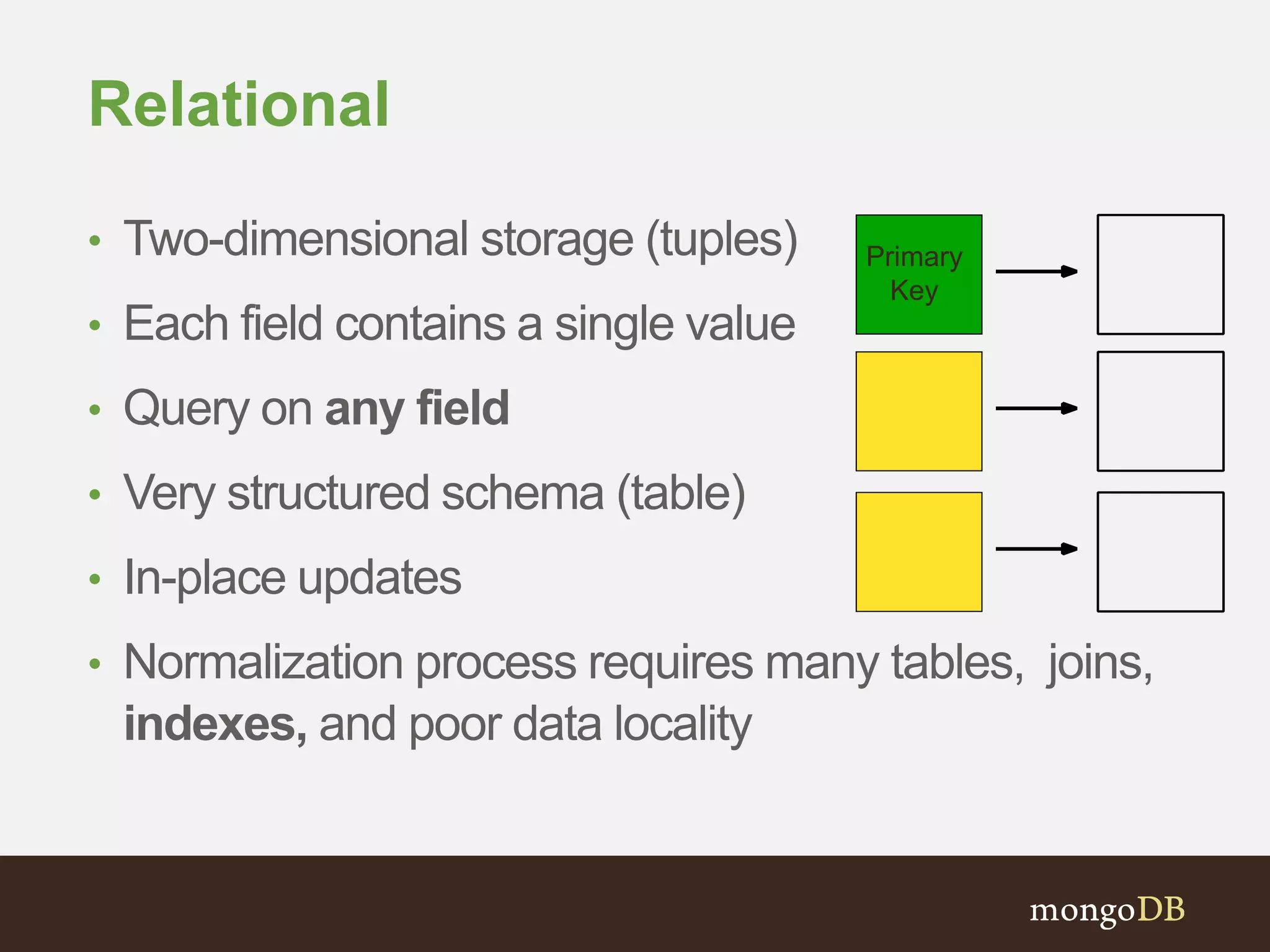
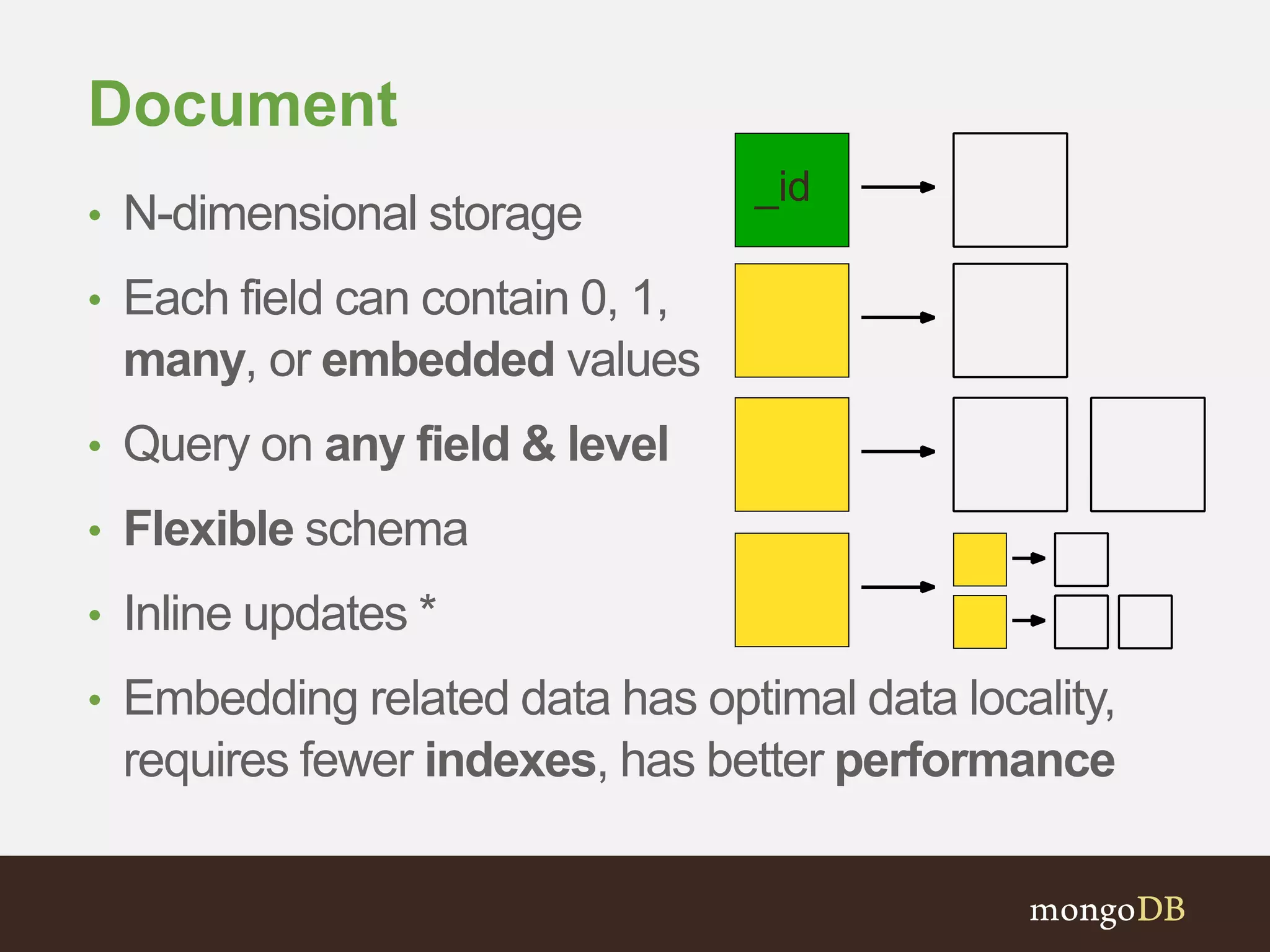
Explains the concept of Records: Key-Value (1D), Relational (2D), and Document (N-dimensional) storage with advantages of flexible schemas.
Discussion on core schema design concepts, focusing on differences between Traditional and Document Schema designs.
Highlights flexibility in schema design with choices for fields and structures that can be easily evolved.
Discusses the use of Arrays within documents: multiple values per field and querying capabilities.
Describes how a value in a document can be another document, allowing nested structures and efficient querying.
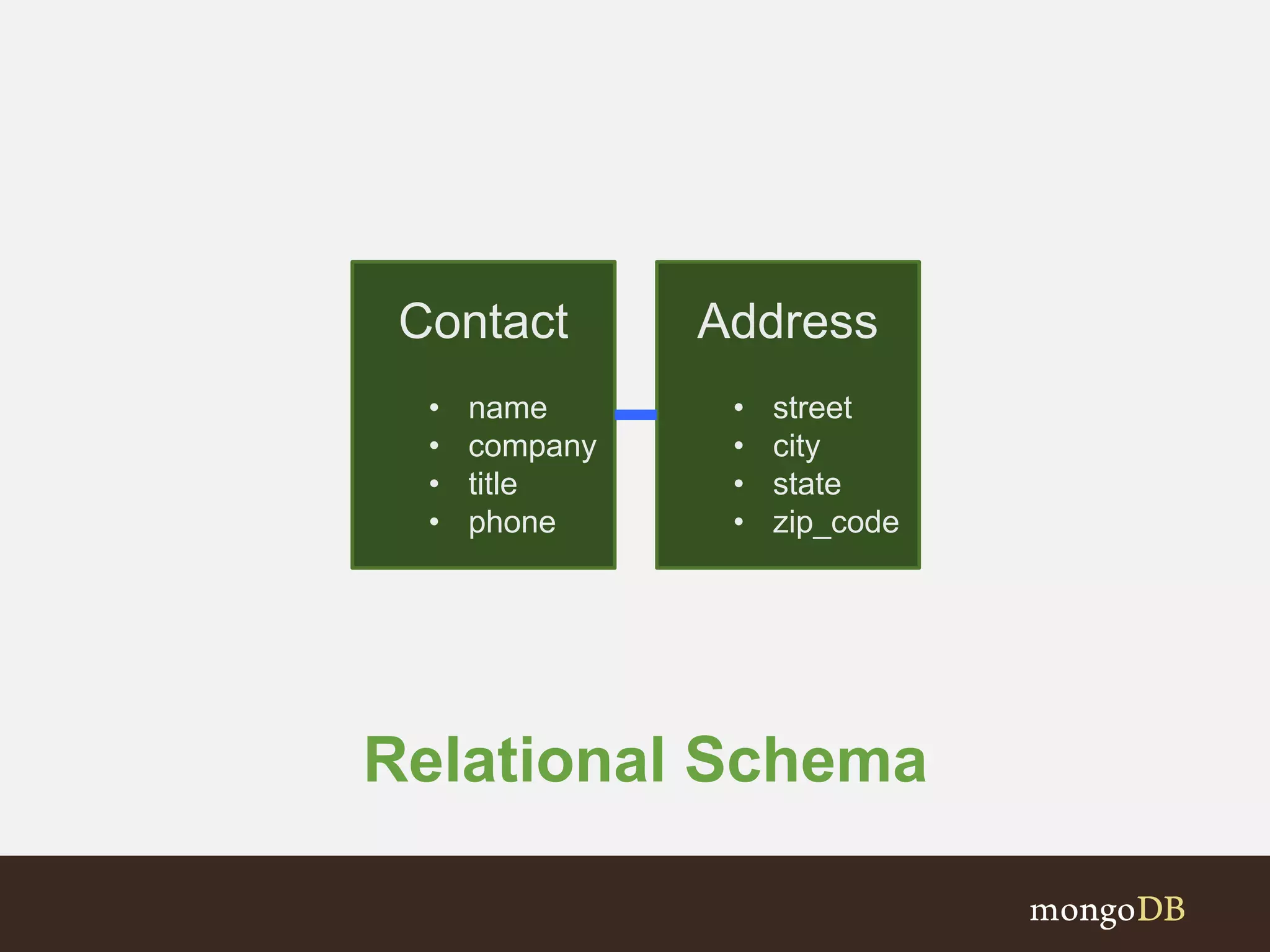
Definition of an Entity in a model with its associations; begins modeling a business card example.
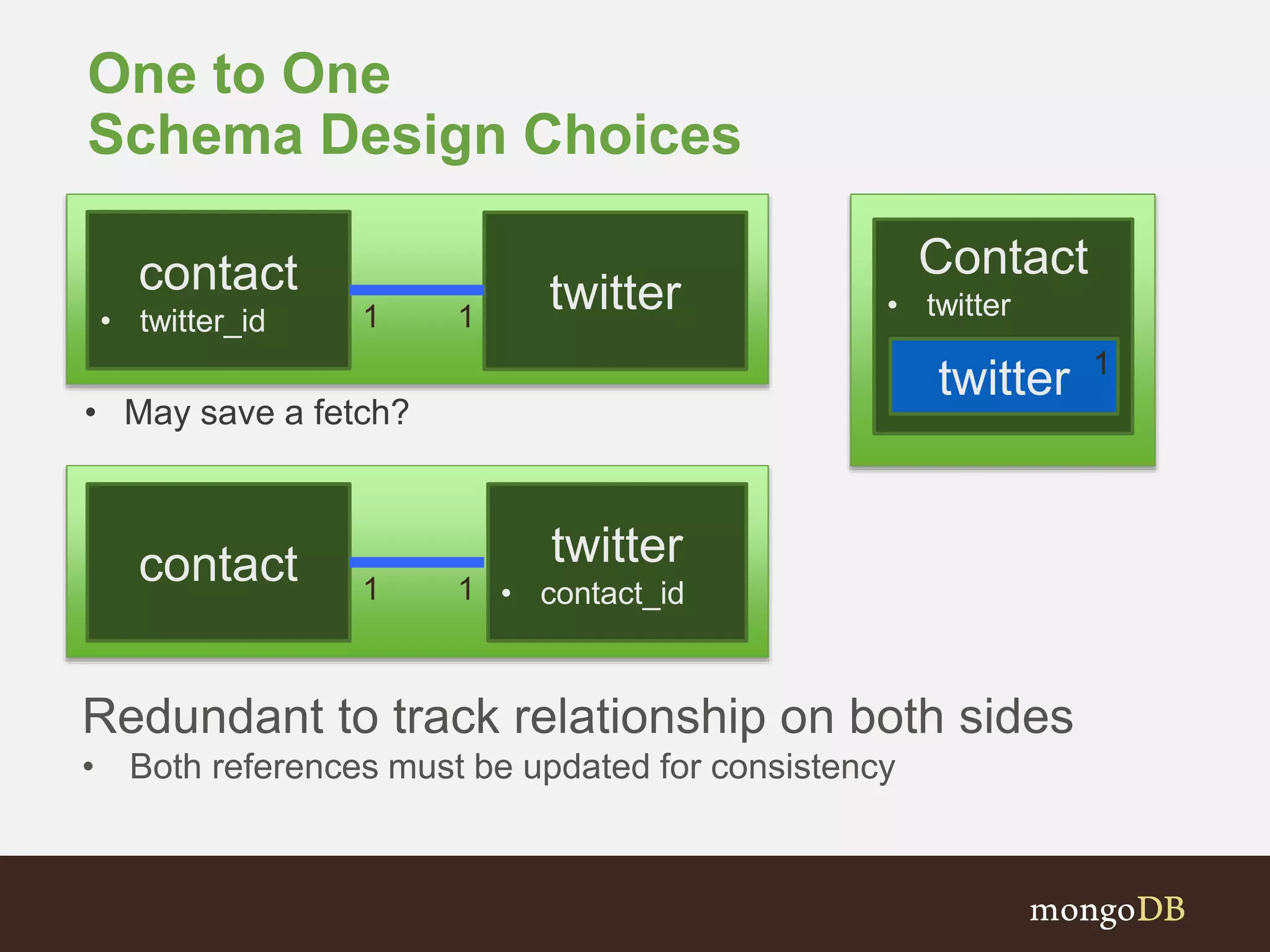
Illustrates data structures for business cards using Referencing and Embedding schemas.
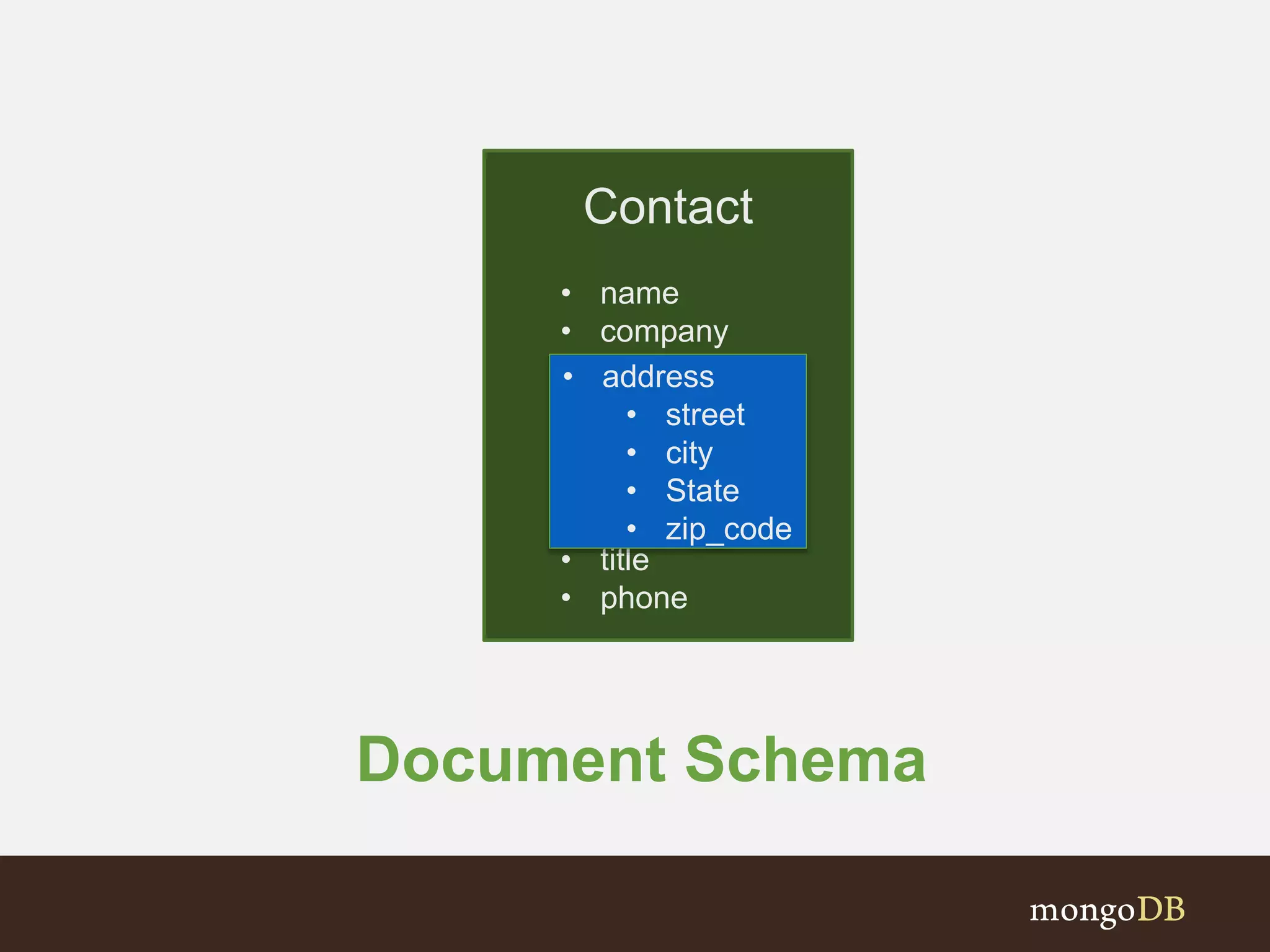
Comparison of Relational and Document Schema design choices and data structure for a Contact.
Demonstrates schema flexibility through examples of possible variations in address book contacts.
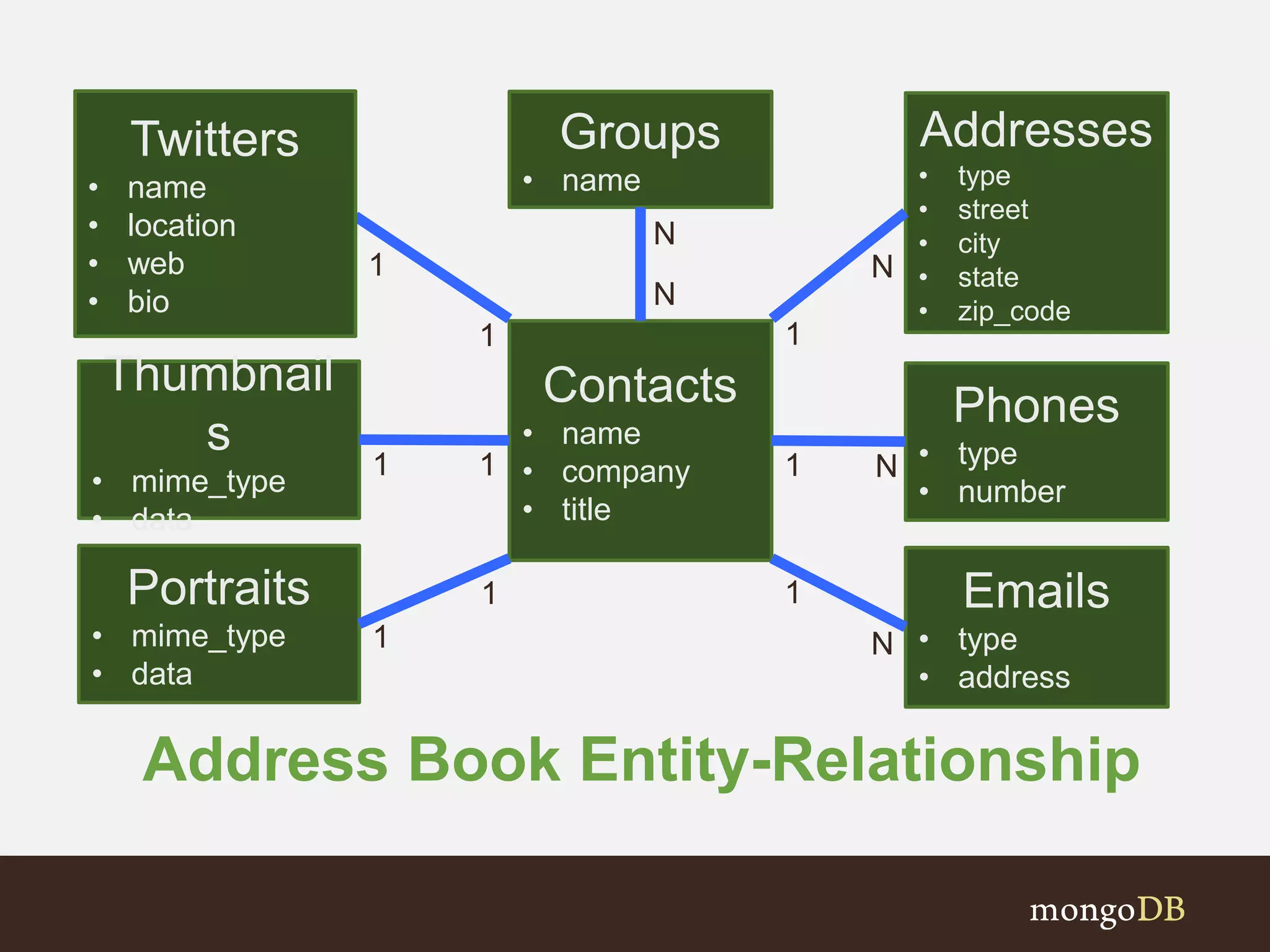
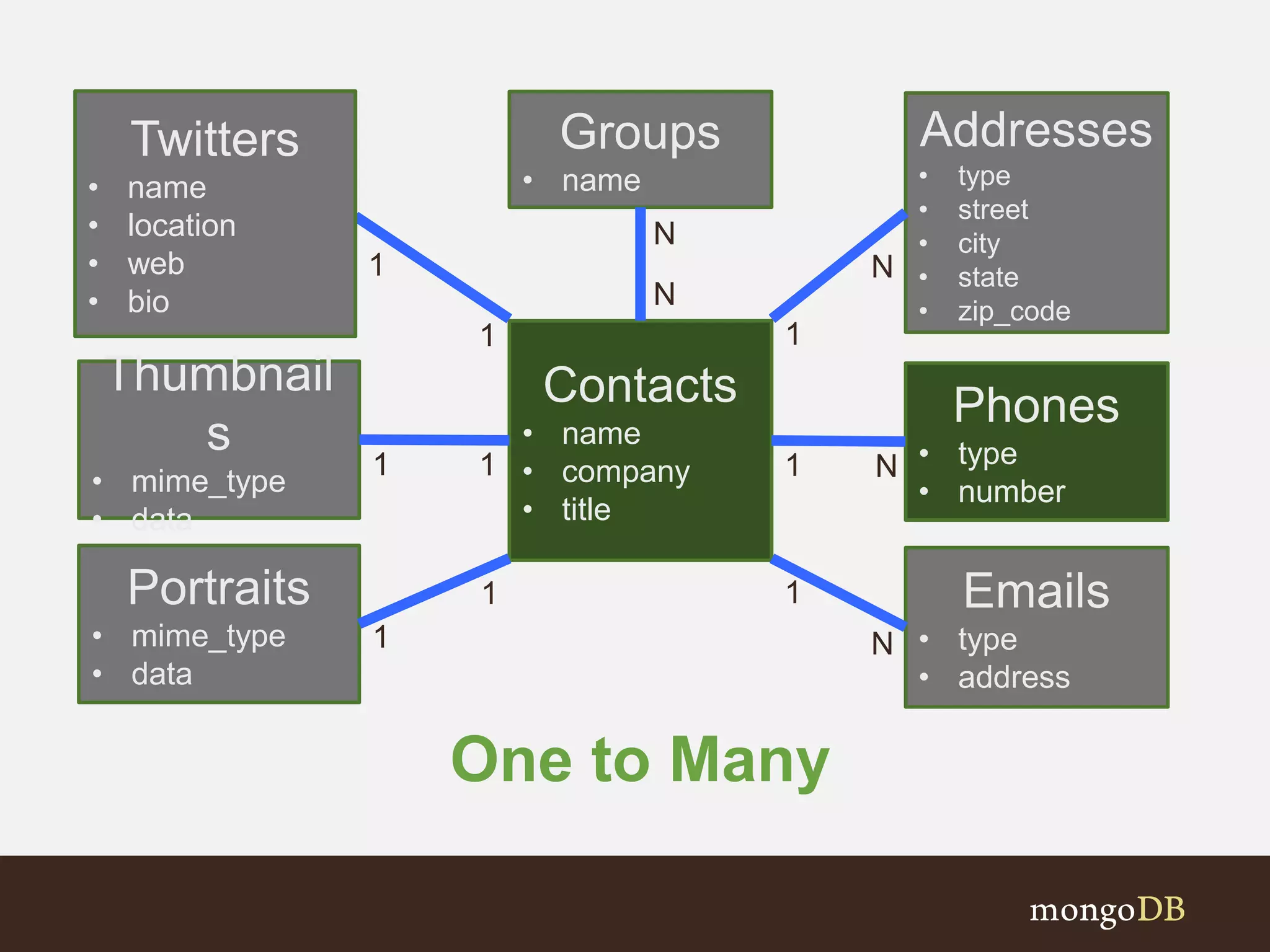
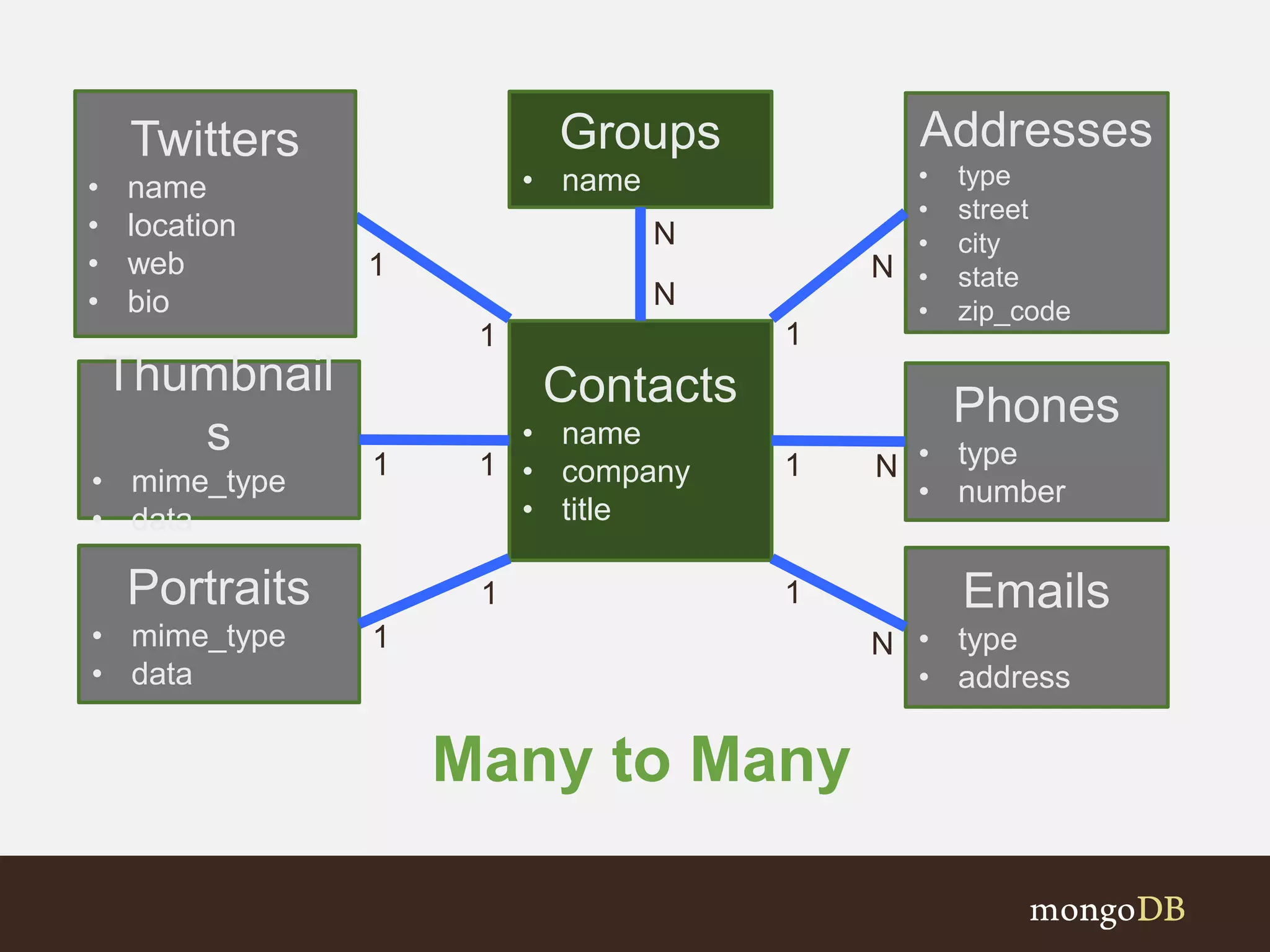
Discusses key questions and relationships between entities in an address book structure.
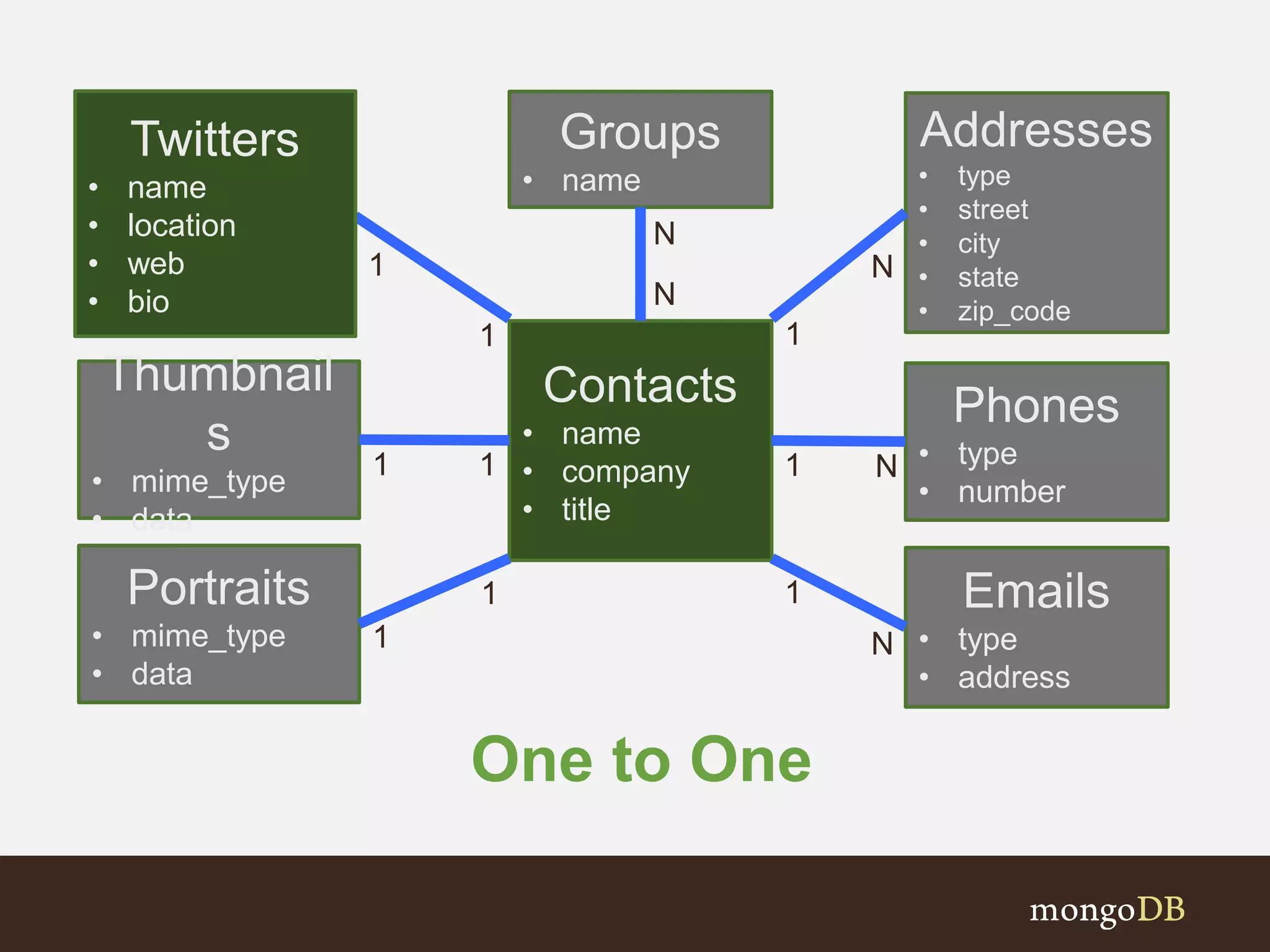
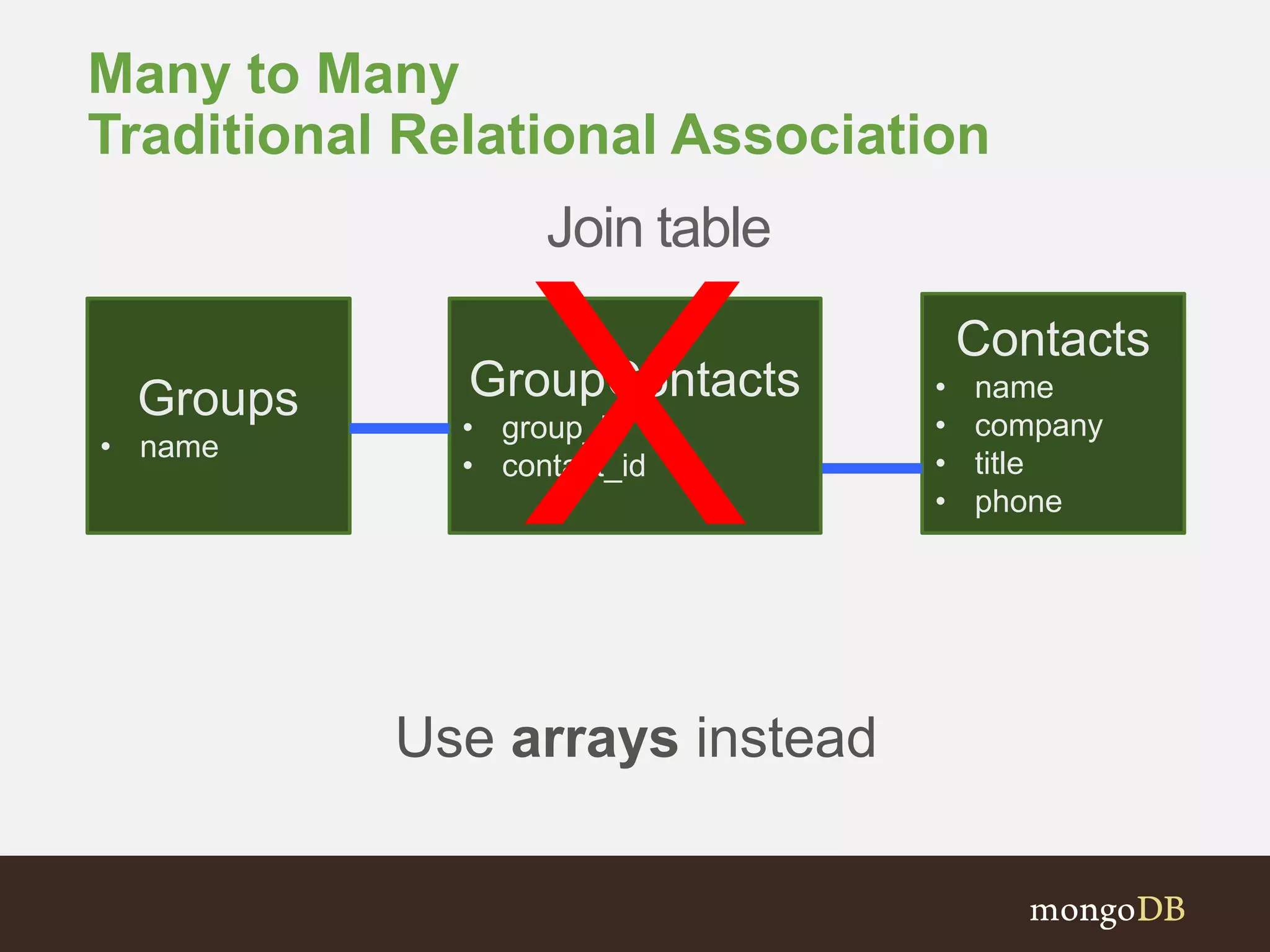
Examines various association types (One-to-One, One-to-Many, Many-to-Many) and schema design choices.
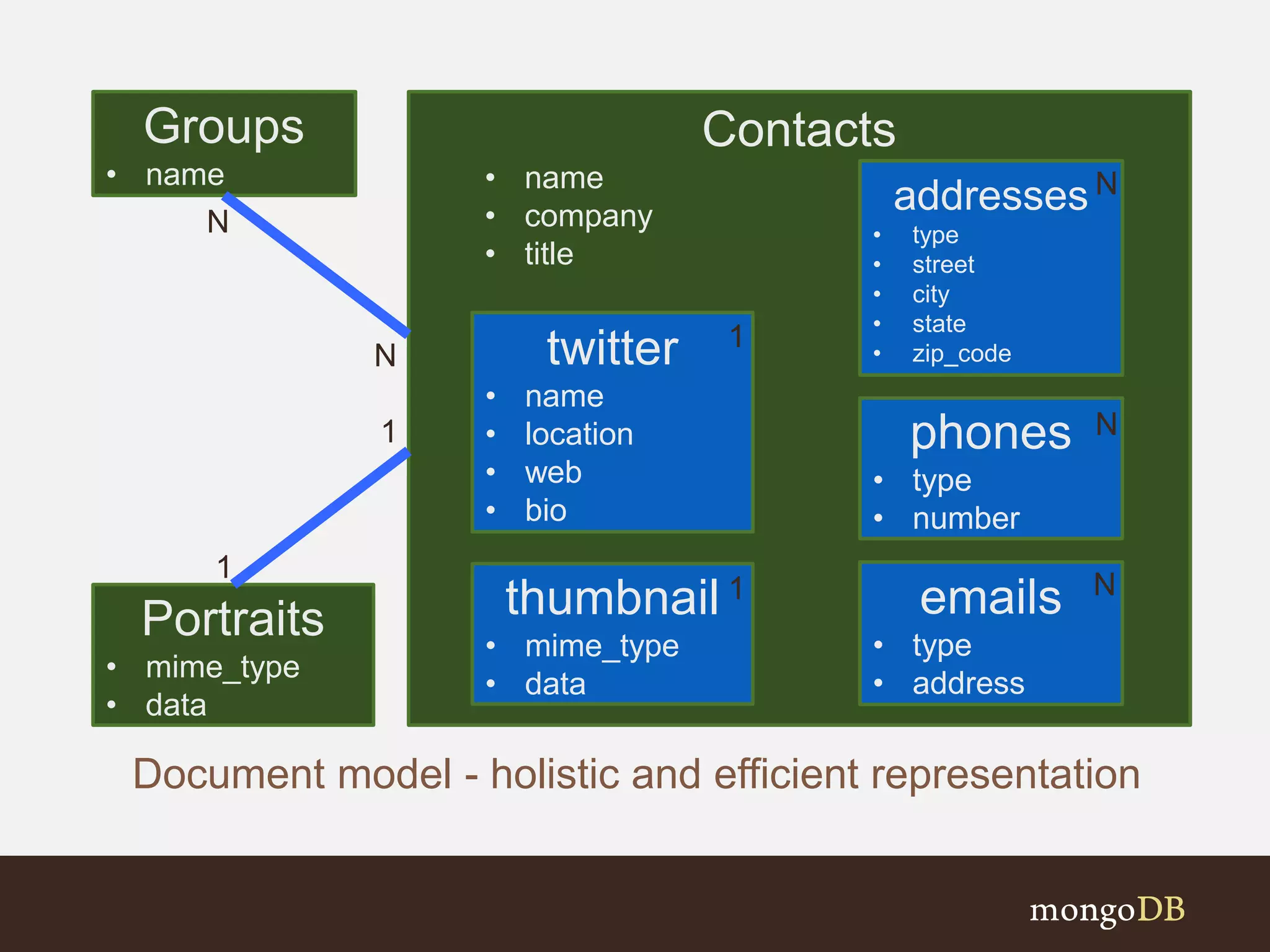
Presents a holistic representation of contacts and details included in a typical document model.
Recommendations for managing the working set to optimize performance in MongoDB.
General recommendations for schema migration and design choices between embedding and referencing.
Final thoughts emphasizing the interplay between applications, databases, and flexible schema design.

























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)










![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)







![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)






