Downloaded 121 times








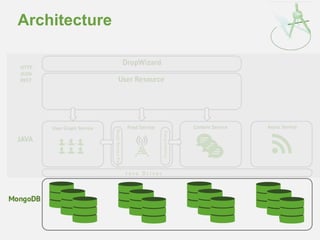




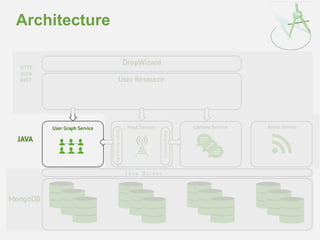






![Embedded Edge Arrays
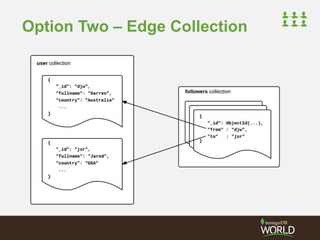
• Storing connections with user (popular choice)
Most compact form
Efficient for reads
• However….
– User documents grow
– Upper limit on degree (document size)
– Difficult to annotate (and index) edge
{
"_id" : "djw",
"fullname" : "Darren Wood",
"country" : "Australia",
"followers" : [ "jsr", "ian"],
"following" : [ "jsr", "pete"]
}](https://image.slidesharecdn.com/2014fallsocialite-140919112734-phpapp02/85/Socialite-the-Open-Source-Status-Feed-31-320.jpg)
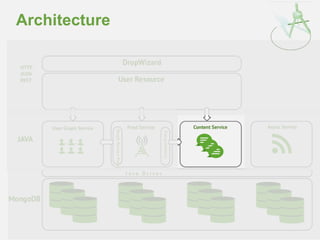
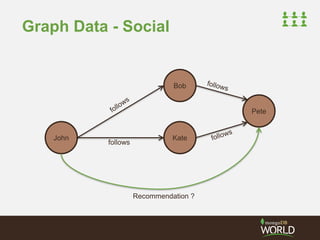
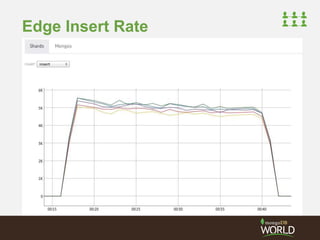
![Embedded Edge Arrays
• Creating Rich Graph Information
– Can become cumbersome
{
"_id" : "djw",
"fullname" : "Darren Wood",
"country" : "Australia",
"friends" : [
{"uid" : "jsr", "grp" : "school"},
{"uid" : "ian", "grp" : "work"} ]
}
{
"_id" : "djw",
"fullname" : "Darren Wood",
"country" : "Australia",
"friends" : [ "jsr", "ian"],
"group" : [ ”school", ”work"]
}](https://image.slidesharecdn.com/2014fallsocialite-140919112734-phpapp02/85/Socialite-the-Open-Source-Status-Feed-32-320.jpg)







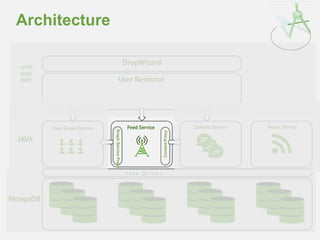

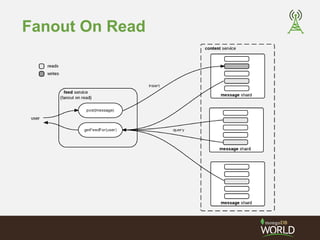

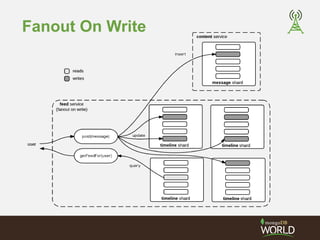


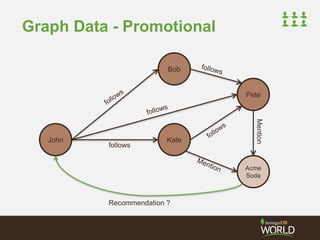
![Timeline Buckets - Time
Upsert to time range buckets for each user
> db.timed_buckets.find().pretty()
{
"_id" : {"_u" : "jsr", "_t" : 516935},
"_c" : [
{"_id" : ObjectId("...dc1"), "_a" : "djw", "_m" : "message from daz"},
{"_id" : ObjectId("...dd2"), "_a" : "ian", "_m" : "message from ian"}
]
}
{
"_id" : {"_u" : "ian", "_t" : 516935},
"_c" : [
{"_id" : ObjectId("...dc1"), "_a" : "djw", "_m" : "message from daz"}
]
}
{
"_id" : {"_u" : "jsr", "_t" : 516934 },
"_c" : [
{"_id" : ObjectId("...da7"), "_a" : "ian", "_m" : "earlier from ian"}
]
}](https://image.slidesharecdn.com/2014fallsocialite-140919112734-phpapp02/85/Socialite-the-Open-Source-Status-Feed-51-320.jpg)
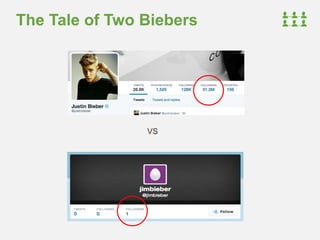
![Timeline Buckets - Size
More complex, but more consistently sized
> db.sized_buckets.find().pretty()
{
"_id" : ObjectId("...122"),
"_c" : [
{"_id" : ObjectId("...dc1"), "_a" : "djw", "_m" : "message from daz"},
{"_id" : ObjectId("...dd2"), "_a" : "ian", "_m" : "message from ian"},
{"_id" : ObjectId("...da7"), "_a" : "ian", "_m" : "earlier from ian"}
],
"_s" : 3,
"_u" : "jsr"
}
{
"_id" : ObjectId("...011"),
"_c" : [
{"_id" : ObjectId("...dc1"), "_a" : "djw", "_m" : "message from daz"}
],
"_s" : 1,
"_u" : "ian"
}](https://image.slidesharecdn.com/2014fallsocialite-140919112734-phpapp02/85/Socialite-the-Open-Source-Status-Feed-52-320.jpg)
![Timeline - Cache
Store a limited cache, fall back to "fanout on read"
– Create single cache doc on demand with upsert
– Limit size of cache with $slice
– Timeout docs with TTL for inactive users
> db.timeline_cache.find().pretty()
{
"_c" : [
{"_id" : ObjectId("...dc1"), "_a" : "djw", "_m" : "message from daz"},
{"_id" : ObjectId("...dd2"), "_a" : "ian", "_m" : "message from ian"},
{"_id" : ObjectId("...da7"), "_a" : "ian", "_m" : "earlier from ian"}
],
"_u" : "jsr"
}
{
"_c" : [
{"_id" : ObjectId("...dc1"), "_a" : "djw", "_m" : "message from daz"}
],
"_u" : "ian"
}](https://image.slidesharecdn.com/2014fallsocialite-140919112734-phpapp02/85/Socialite-the-Open-Source-Status-Feed-53-320.jpg)
![Embedding vs Linking Content
Embedded content for direct access
– Great when it is small, predictable in size
Link to content, store only metadata
– Read only desired content on demand
– Further stabilizes cache document sizes
> db.timeline_cache.findOne({”_id" : "jsr"})
{
"_c" : [
{"_id" : ObjectId("...dc1”)},
{"_id" : ObjectId("...dd2”)},
{"_id" : ObjectId("...da7”)}
],
”_id" : "jsr"
}](https://image.slidesharecdn.com/2014fallsocialite-140919112734-phpapp02/85/Socialite-the-Open-Source-Status-Feed-54-320.jpg)

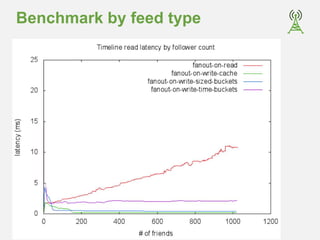


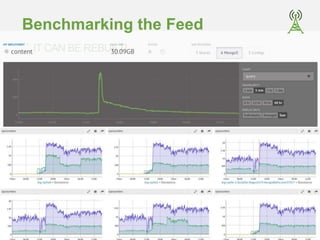




The document outlines the development of a social platform utilizing MongoDB, focusing on various architectural decisions such as user timeline caching, schema indexing, and operational testing. Key features include a fanout feed model for content delivery and an open-source project called Socialite, which serves as a reference implementation. It also discusses benchmarking results and specific challenges encountered during scaling considerations and content management.











































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































