












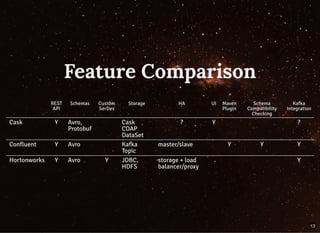

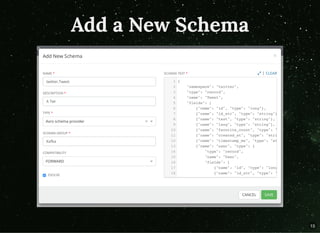
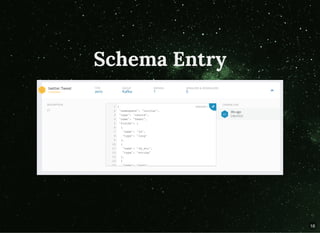
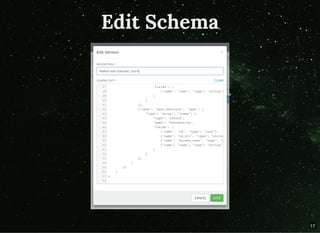





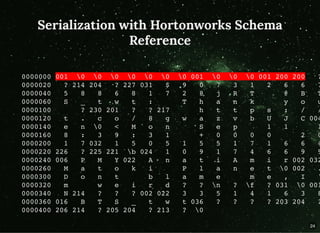


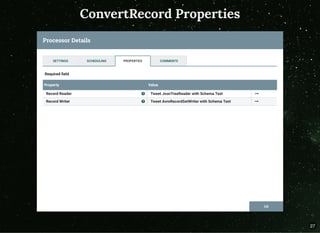


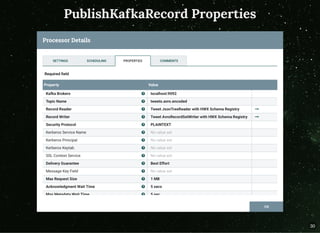








The document discusses moving beyond simply moving bytes in stream processing and instead focusing on understanding data semantics through the use of a schema registry. A schema registry is a centralized service for storing and retrieving schemas to support serialization and deserialization across applications and systems. Several existing schema registries are described, along with how schemas can be referenced in messages rather than embedded. The use of a schema registry in a data pipeline is demonstrated. Finally, the document discusses implementing serialization and deserialization using schemas with Apache Flink.
























































