Downloaded 103 times





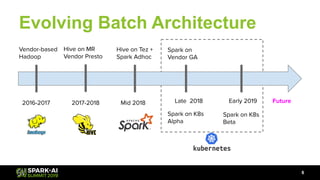
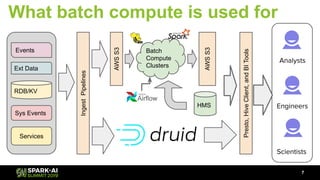
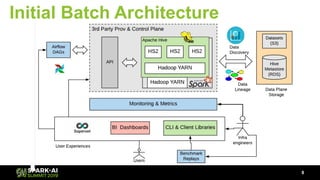







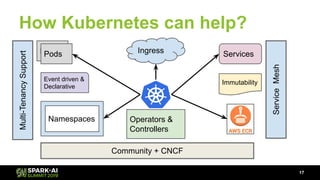



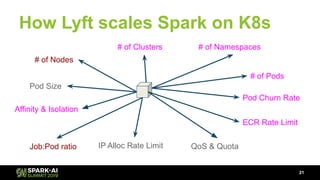
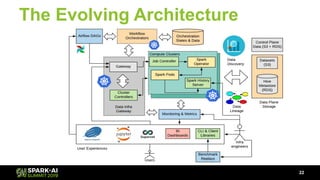
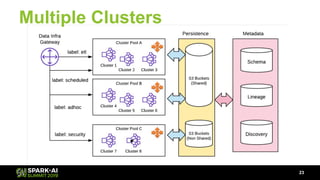
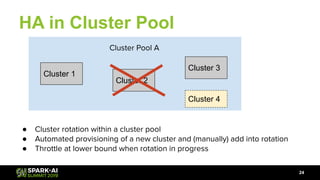
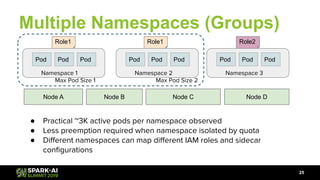
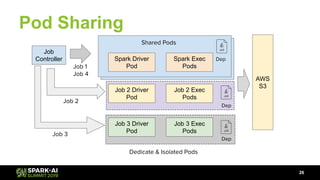
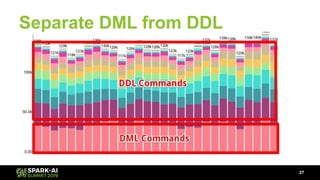
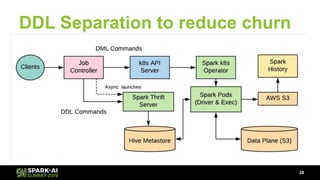


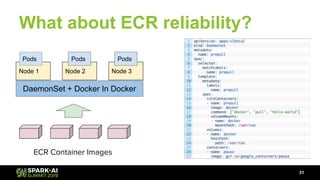
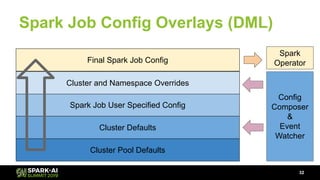
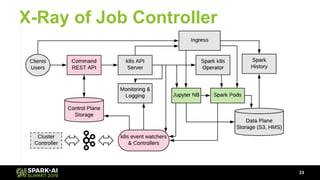

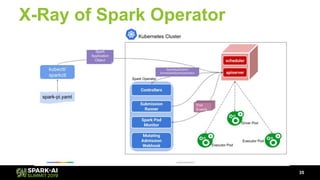
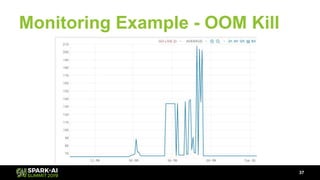





The document discusses Lyft's data landscape and the implementation of Apache Spark on Kubernetes to improve batch data compute processes. It highlights challenges faced in data infrastructure, such as vendor dependency and versioning issues, while suggesting solutions through Kubernetes for enhanced scalability and resource management. Key takeaways emphasize the potential of Spark and Kubernetes in unifying batch data compute use cases despite existing challenges.































![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)
