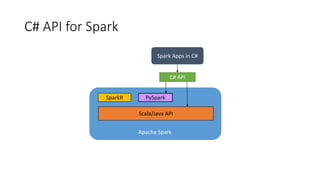
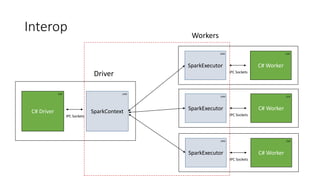
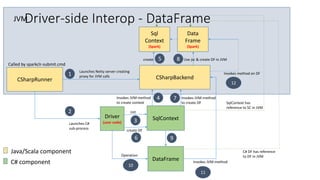
The document details the Mobius C# API for Apache Spark, presented at the Seattle Spark Meetup in February 2016. It covers the background, architecture, and implementation of the C# API, aiming to integrate Spark applications within the .NET ecosystem while reusing existing .NET libraries. Key focus areas include real-time processing of Bing logs, interop design considerations, and addressing performance optimization in Spark applications using C#.











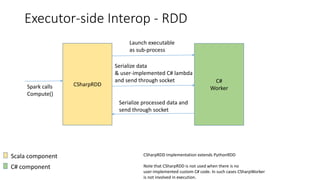
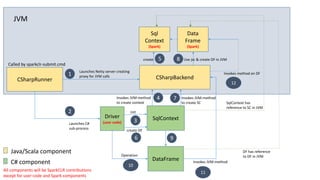
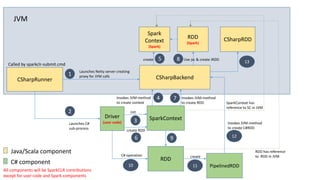
![CSharpRDD
• C# operations use CSharpRDD which needs CLR to execute
• If no C# transformation or UDF is involved, CLR is not needed – execution is
purely JVM-based
• RDD<byte[]>
• Data is stored as serialized objects and sent to C# worker process
• Transformations are pipelined when possible
• Avoids unnecessary serialization & deserialization within a stage](https://image.slidesharecdn.com/seattle-spark-meetup-mobius-csharp-api-160316050736/85/Seattle-Spark-Meetup-Mobius-CSharp-API-13-320.jpg)

























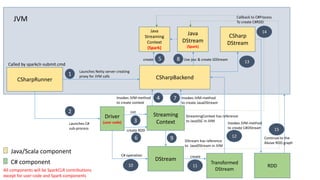





![DStream sample
// write code here to drop text files under <directory>test
… … …
StreamingContext ssc = StreamingContext.GetOrCreate(checkpointPath,
() =>
{
SparkContext sc = SparkCLRSamples.SparkContext;
StreamingContext context = new StreamingContext(sc, 2000);
context.Checkpoint(checkpointPath);
var lines = context.TextFileStream(Path.Combine(directory, "test"));
var words = lines.FlatMap(l => l.Split(' '));
var pairs = words.Map(w => new KeyValuePair<string, int>(w, 1));
var wordCounts = pairs.ReduceByKey((x, y) => x + y);
var join = wordCounts.Join(wordCounts, 2);
var state = join.UpdateStateByKey<string, Tuple<int, int>, int>((vs, s) => vs.Sum(x => x.Item1 + x.Item2) + s);
state.ForeachRDD((time, rdd) =>
{
object[] taken = rdd.Take(10);
});
return context;
});
ssc.Start();
ssc.AwaitTermination();](https://image.slidesharecdn.com/seattle-spark-meetup-mobius-csharp-api-160316050736/85/Seattle-Spark-Meetup-Mobius-CSharp-API-53-320.jpg)












![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)






















































