Download as PDF, PPTX




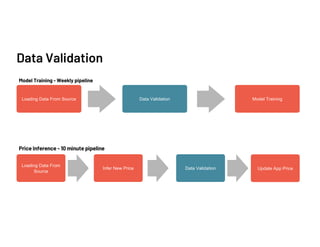















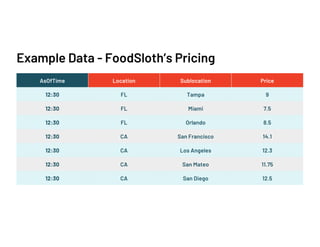


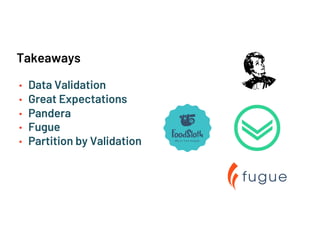















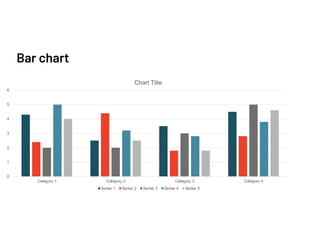


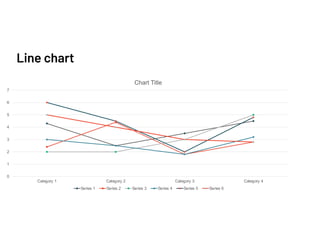
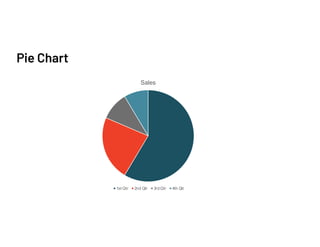





The document discusses data validation using various frameworks including Great Expectations, Pandera, and Fugue. It covers their features, advantages, and how they can be applied in Spark for data validation in a fictitious food delivery company case study. Key takeaways include the importance of validation, especially by partitioning, to accommodate geographic differences in data.























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











