Download as PDF, PPTX






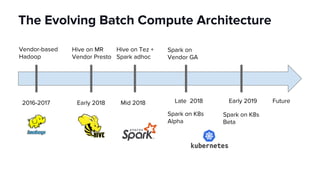
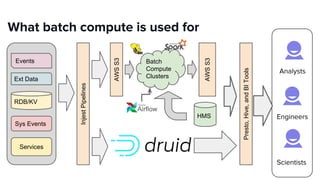
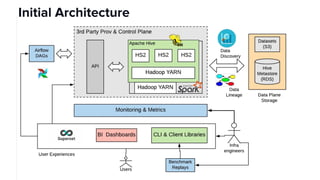



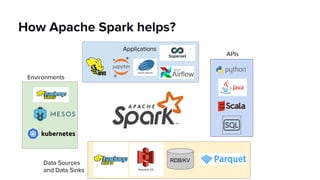

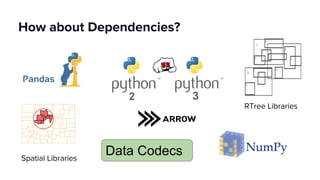

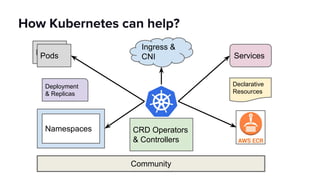



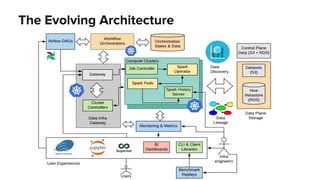
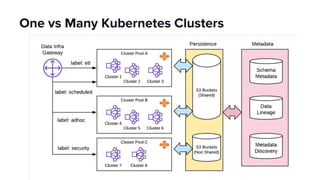
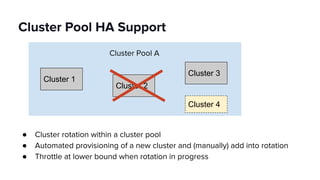

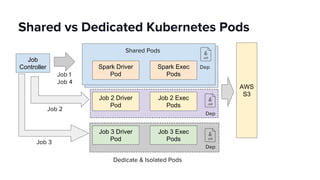
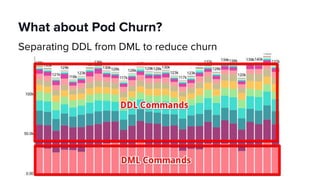
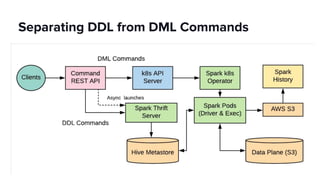
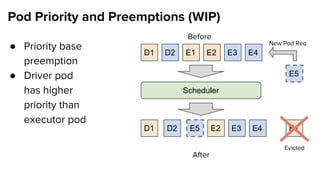
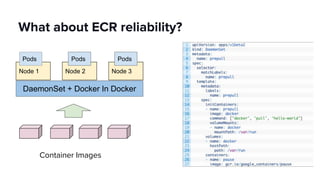
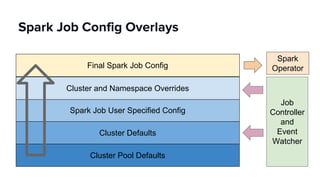
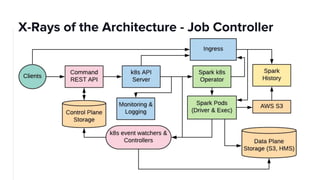
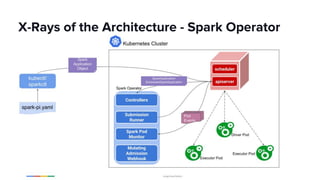

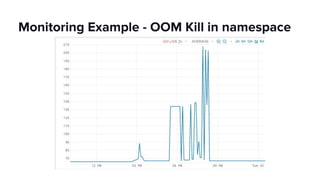





The document discusses scaling Apache Spark on Kubernetes at Lyft, highlighting the challenges faced in the data landscape including batch data ingestion, data streaming, and operational analytics. It outlines how using Kubernetes can address issues related to dependencies and multi-version support, enabling more efficient scaling of Spark jobs across multiple clusters. Key takeaways emphasize the potential of Kubernetes in improving resource isolation and scheduling, though challenges still exist when implementing Spark at scale.































![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)



































