Download to read offline








![Key Features
More specifically, BioBurst will incorporate the following major
components and operational characteristics:
• A software-defined I/O accelerator appliance with 40 terabytes of
non-volatile (“flash”) memory and software designed to alleviate the
small-block/small-file random access I/O problem characteristic of
many bioinformatics codes;
• Derived from Exascale program “burst buffer” technology
• An FPGA-based computational accelerator node (Edico Genome
DRAGEN) that has been shown to conduct demultiplexing, mapping,
and variant calling of a single human genome in 22 minutes as
compared to ~10 hours on standard computing hardware [2];
• 672 commodity (x86) computing cores providing a separately
scheduled resource for running various bioinformatics
computations;
• Integration with a Lustre parallel file system, which supports
streaming I/O, and has the capacity to stage large amounts of data
characteristic of many bioinformatics studies; and,](https://image.slidesharecdn.com/san-diego-supercomputing-sc17-user-group-171206201558/75/San-diego-supercomputing-sc17-user-group-10-2048.jpg)
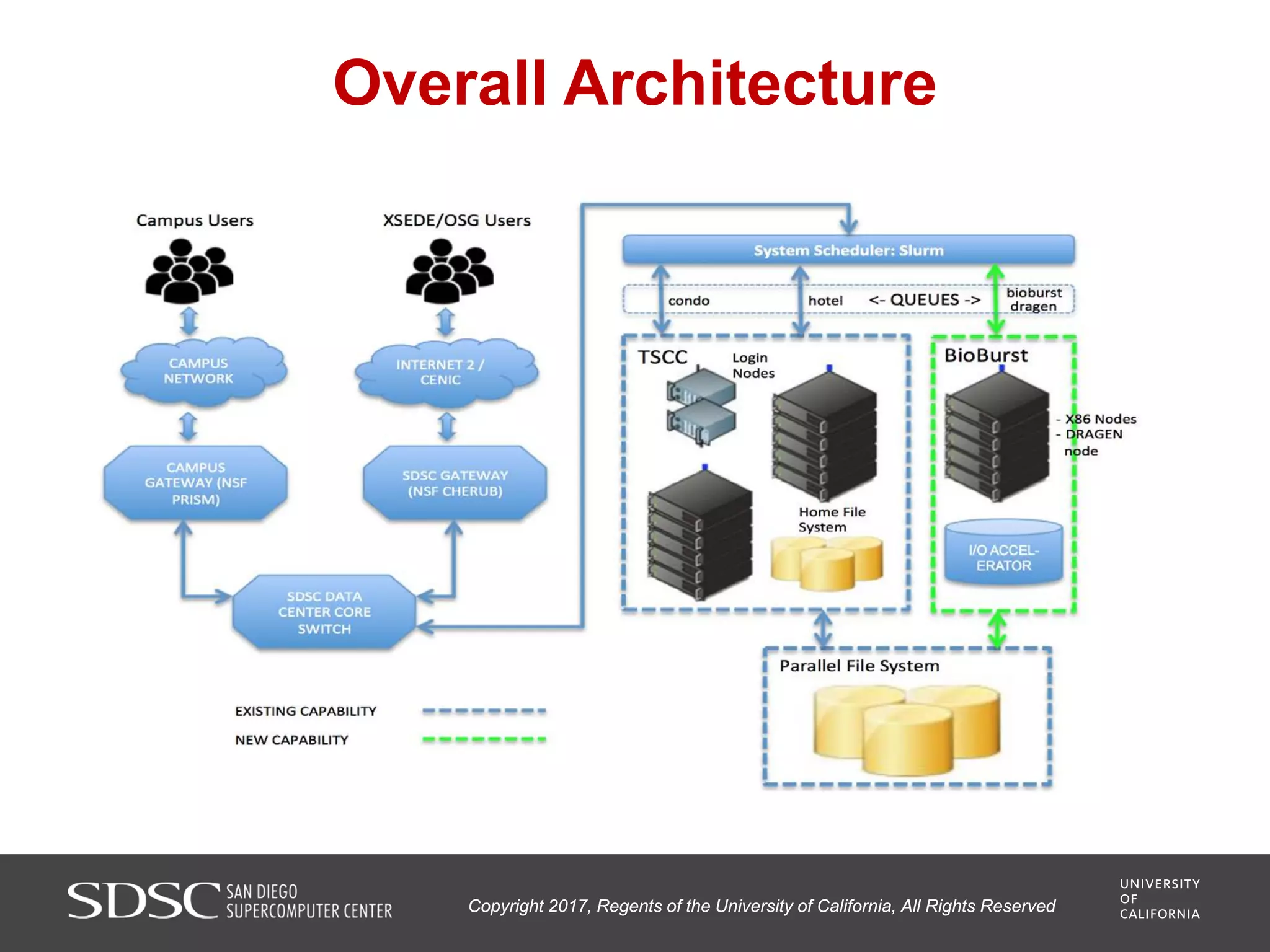
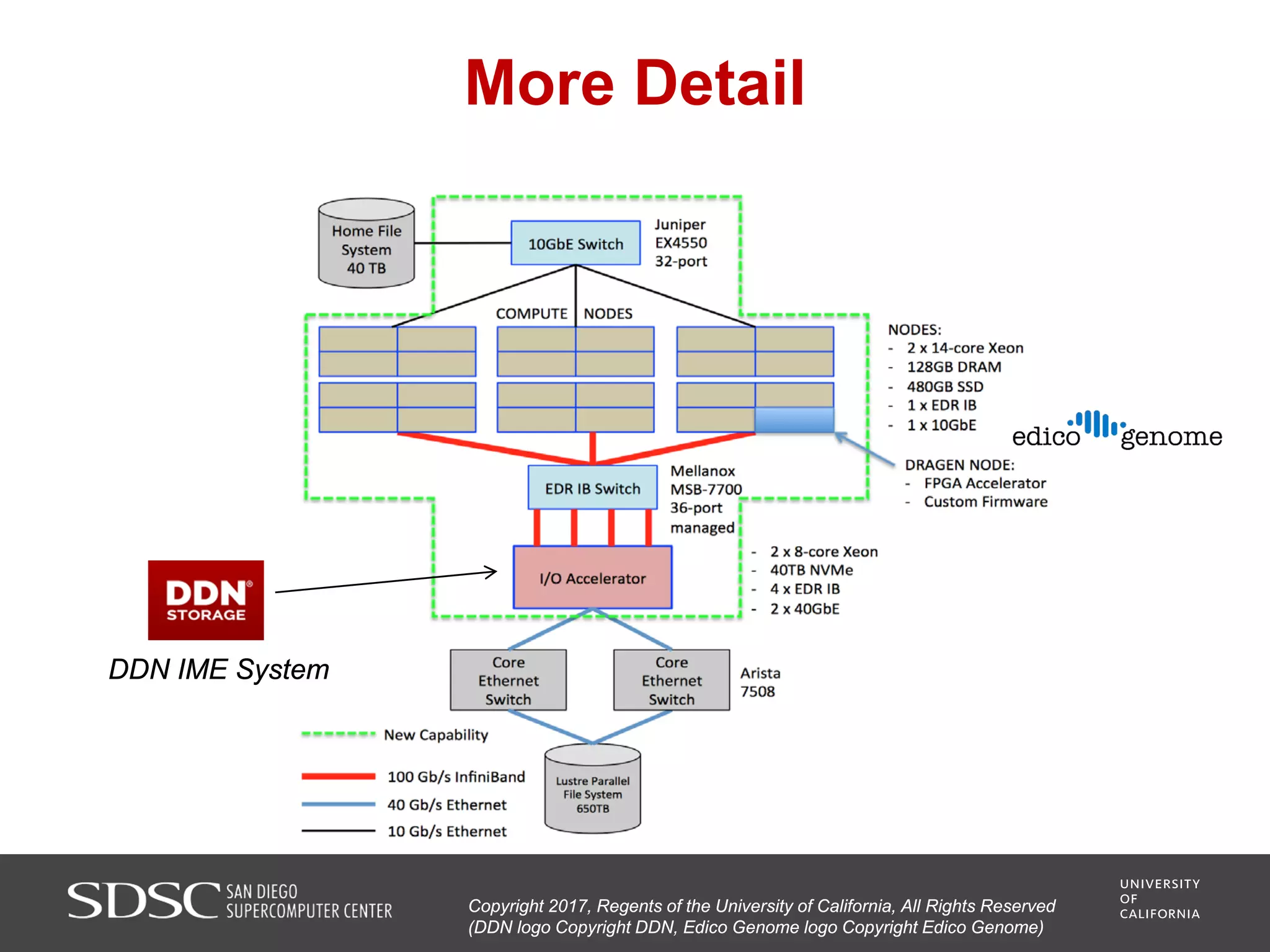
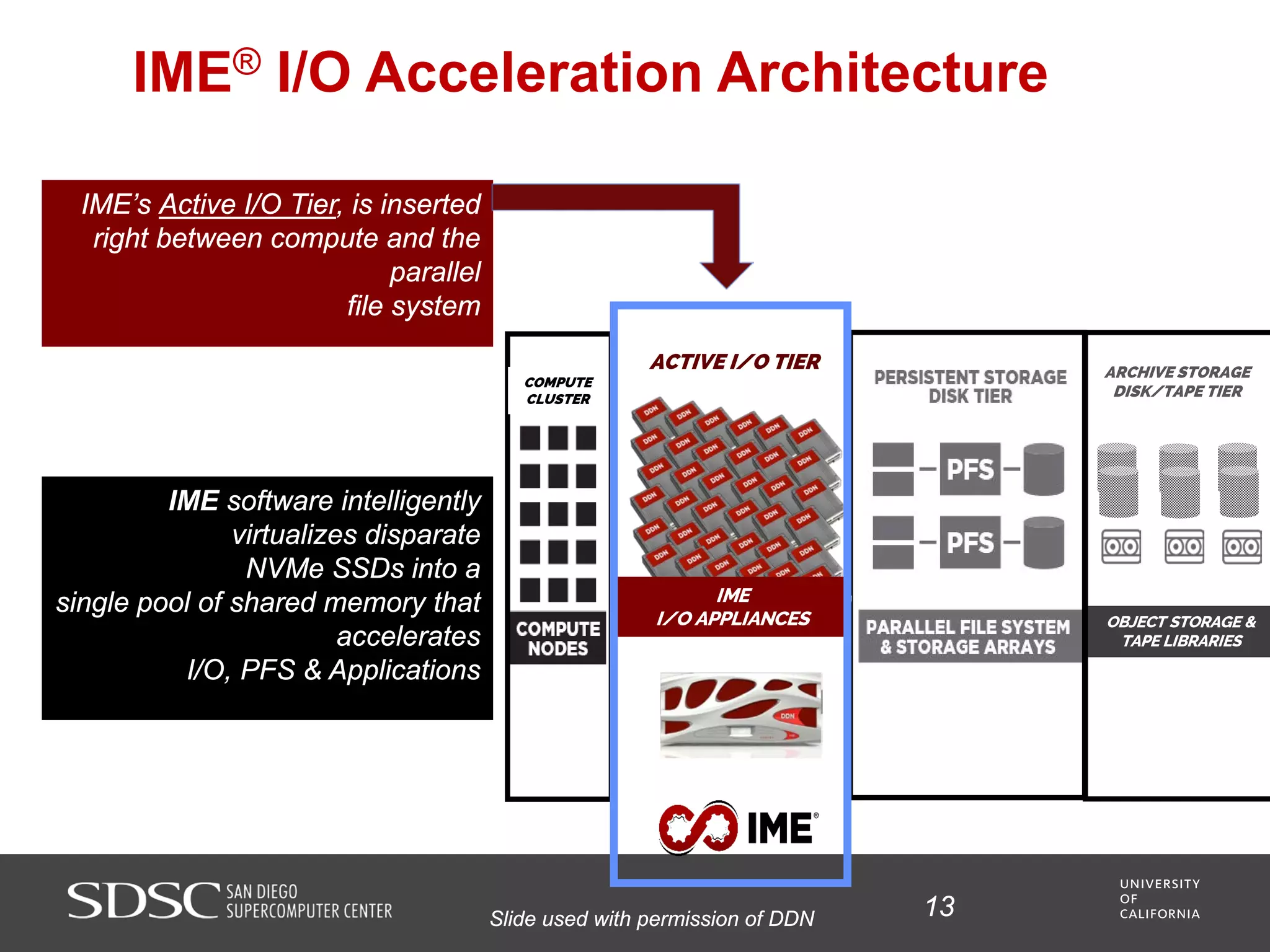






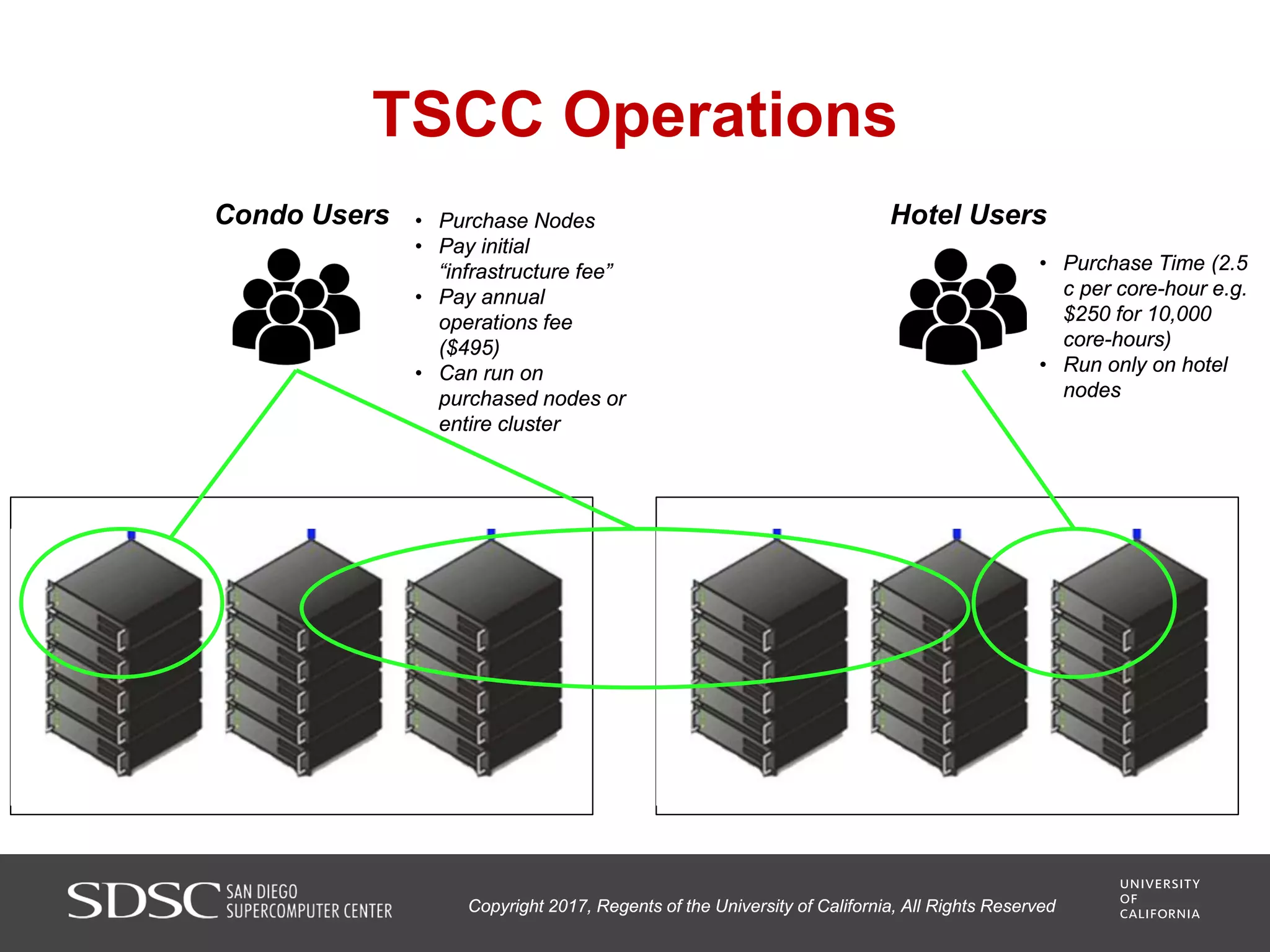
UC San Diego's BioBurst cluster provides additional resources for bioinformatics workloads through an I/O accelerator, FPGA-based computational accelerator, and 672 additional compute cores. The I/O accelerator uses 40TB of flash memory to alleviate small block/file I/O issues in bioinformatics applications. The FPGA accelerator can perform genome analysis tasks much faster than standard hardware. The resources are integrated with UC San Diego's existing high performance computing cluster to improve research productivity and address bottlenecks in genomics and other bioinformatics applications and pipelines.










































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












