Downloaded 21 times






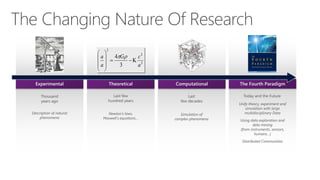
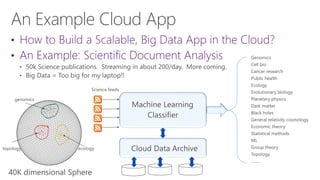




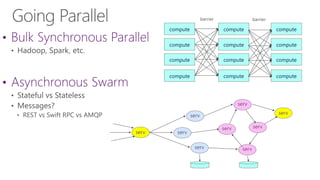


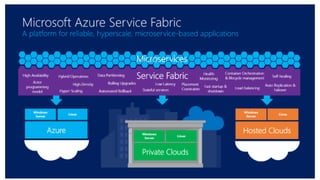
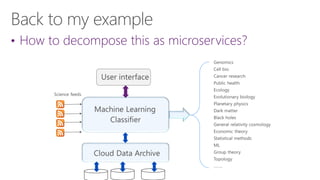
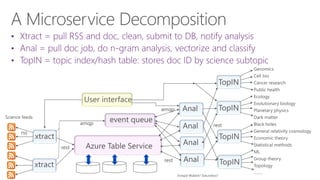

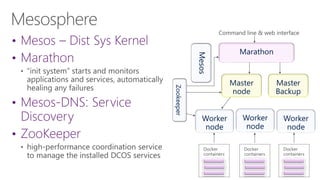







The document discusses the evolution of research fields into data science domains, emphasizing the integration of theory, experiment, and simulation using large datasets. It highlights various programming tools, frameworks, and the challenges of sustainability, sharing, and reproducibility in data science. Furthermore, it outlines the importance of collaboration in data acquisition, modeling, and analysis.





































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



