Modul Ajar Statistika Inferensia ke-4: Uji Hipotesa Proporsi Parametrik
Dokumen tersebut membahas tentang statistika inferensia yang menganalisis data sampel untuk menggeneralisasi ke populasi, mengestimasi parameter, menguji hipotesa, dan membuat prediksi."
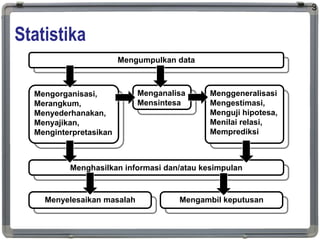
Statistika
Statistika adalah cabangilmu matematika yang
mempelajari metode ilmiah untuk mengumpulkan,
mengorganisasi, merangkum, menyederhanakan,
menyajikan, menginterpretasikan, menganalisa dan
mensintesa data (numerik atau nonnumerik) untuk
menghasilkan informasi dan/atau kesimpulan, yang
membantu dalam penyelesaian masalah dan/atau
pengambilan keputusan.
2
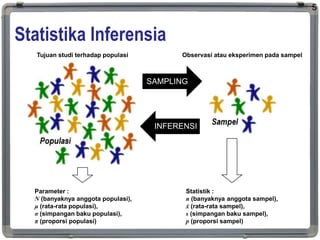
Statistika Inferensia
Statistika inferensiaadalah cabang statistika yang
menganalisa atau mensintesa data untuk
menggeneralisasi sampel terhadap populasi,
mengestimasi parameter, menguji hipotesa, menilai
relasi, dan membuat prediksi untuk menghasilkan
informasi dan/atau kesimpulan.
Terdapat banyak alat bantu statistika (statistical tools)
yang dapat dipergunakan untuk menginferensi
populasi atau sistem yang menjadi sumber asal data
sampel
4
5.
Statistika Inferensia
5
Tujuan studiterhadap populasi Observasi atau eksperimen pada sampel
SAMPLING
INFERENSI
Parameter :
N (banyaknya anggota populasi),
μ (rata-rata populasi),
σ (simpangan baku populasi),
π (proporsi populasi)
Statistik :
n (banyaknya anggota sampel),
ẋ (rata-rata sampel),
s (simpangan baku sampel),
p (proporsi sampel)
6.
Tipe Data
Data Nominal,data yang hanya berupa simbol (meski berupa
angka) untuk membedakan nilainya tanpa menunjukkan tingkatan
Data Ordinal, data yang mempunyai nilai untuk menunjukkan
tingkatan, namun tanpa skala yang baku dan jelas antar tingkatan.
Data Interval, data yang mempunyai nilai untuk menunjukkan
tingkatan dengan skala tertentu sesuai intervalnya. Nilai nol hanya
untuk menunjukkan titik acuan (baseline).
Data Rasio, data yang mempunyai nilai untuk menunjukkan
tingkatan dengan skala indikasi rasio perbandingan. Nilai nol
menunjukkan titik asal (origin) yang bernilai kosong (null).
6
7.
Tipe Data
Data Parametrik,data kuantitatif yang mempunyai
sebaran variabel acak mengikuti pola distribusi
probabilitas dengan parameter tertentu (independent
and identically distributed random variables)
Data Nonparametrik, data yang tidak mempunyai
distribusi probabilitas (distribution-free)
7
8.
Tipe Data
Data Diskrit,data hasil pencacahan atau
penghitungan, sehingga biasanya dalam angka
bilangan bulat.
Data Kontinyu, data hasil pengukuran yang
memungkinkan dalam angka bilangan nyata
(meskipun dapat pula dibulatkan)
8
9.
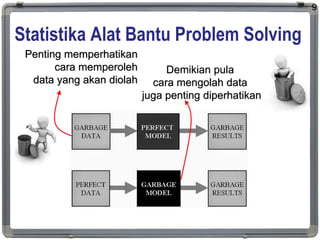
Statistika Alat BantuProblem Solving
9
Penting memperhatikan
cara memperoleh
data yang akan diolah
Demikian pula
cara mengolah data
juga penting diperhatikan
10.
Statistika Alat BantuProblem Solving
10
Metode statistika bukan
ramuan sihir
Alat statistika bukan
tongkat sihir
Akurasi dan Presisi
Akurasi(accuracy), kesesuaian hasil pengukuran
terhadap nilai obyek sesungguhnya (bias kecil)
Presisi (precision), tingkat skala ketelitian
pengukuran dari alat pengukur, atau ketersebaran
yang relatif mengumpul (variansi atau deviasi kecil)
12
13.
Akurat dan Presisi
Tidakpresisi, akibat pola sebaran sampel
lebih melebar daripada pola sebaran
populasi menyebabkan deviasi yang besar.
Tidak akurat, akibat pergeseran
pemusatan sampel menjauh dari
pemusatan populasi menyebabkan bias
yang besar.
Akurat dan presisi, bias dan deviasi kecil,
membutuhkan sampel sedikit.
13
14.
Kesalahan Pengambilan Kesimpulan
Galattipe 1 () : kesalahan menyimpulkan karena
menolak hipotesa yang semestinya diterima
Galat tipe 2 () : kesalahan menyimpulkan karena
menerima hipotesa yang semestinya ditolak
14
15.
Kesalahan Pengambilan Kesimpulan
15
Thetrue state of nature
Decision H0 is true H0 is false
Reject H0 Type I error Exact decision
Fail to reject H0 Exact decision Type II error
The true state of nature
Decision H0 is true H0 is false
Reject H0 1 –
Fail to reject H0 1 –
16.
Ukuran Ketelitian Pendugaan
Tingkatkeberartian (significance level, ), probabilitas
penolakan data observasi, karena menyimpang signifikan terhadap
sasaran.
Tingkat kepercayaan (confidence coefficient,1-), persentase
data observasi yang diyakini tidak berbeda signifikan dengan target.
Kuasa statistik (power,1-), persentase data observasi yang
diyakini berbeda signifikan dengan target.
Derajat kebebasan (degree of freedom, df=n-k), besaran
yang menunjukkan bebas terhadap bias dari n data observasi.
16
Hipotesa
Hipotesa adalah pernyataansebuah pendugaan (presumption),
anggapan (claim), pemikiran (postulate), penegasan (assertion), atau
penerkaan (conjecture), yang mungkin benar atau salah, mengenai
data dan statistik dari satu atau lebih sampel yang berkenaan dengan
parameter dari satu atau lebih populasi
Hipotesa berkaitan dengan
Evaluasi keputusan
Analisa data observasi atau eksperimen
Prediksi statistik
Estimasi parameter
Pengujian
Komparasi perbandingan
18
19.
Hipotesa
Hipotesa statistik diformulasikandalam dua bentuk,
yaitu :
Hipotesa nol (null hypothesis), dinotasikan Ho (dibaca “H-naught”)
dengan format persamaan atau menggunakan tanda baca “=“
Hipotesa alternatif (alternative hypothesis), dinotasikan H1 (dibaca
“H-one”) dengan format pertidaksamaan.
Dua arah (two tail) menggunakan tanda baca “”
Satu arah (one tail) menggunakan tanda baca “<“ atau “>”
19
20.
Pengujian Hipotesa
Pengujian hipotesa(hypothesis testing) adalah
prosedur menggunakan informasi dalam sampel acak dari
sebuah populasi dan probabilitasnya (termasuk distribusinya)
melalui pengujian statistik untuk membentuk keputusan atau
kesimpulan secara induksi atau inferensia menggeneralisasi
terhadap populasinya.
20
21.
Pengujian Hipotesa
Daerah penolakanatau kritis (critical region) yaitu
daerah yang mencakup semua nilai yang memenuhi hipotesa
alternatif.
Daerah penerimaan (acceptance region) yaitu daerah
yang mencakup semua nilai yang memenuhi hipotesa nol.
Nilai kritis (critical value) yaitu nilai yang menjadi batas
antara daerah penolakan dan penerimaan.
Kesimpulan menolak Ho, jika statistik uji < nilai kritis kiri (left-
tailed) atau statistik uji > nilai kritis kanan (right tailed)
21
Kesimpulan Pengujian Hipotesa
Menerimahipotesa nol (lebih tepatnya “gagal menolak
hipotesa nol”) menyatakan bahwa data sampel tidak
mampu memberikan bukti yang cukup dan signifikan untuk
menolaknya.
Menolak hipotesa nol menyatakan bahwa data sampel
memberikan bukti yang cukup dan signifikan untuk
menolaknya.
23
P-Value
P-value adalah tingkatsignifikansi terrendah di mana nilai
observasi dari statistik uji signifikan.
P-value merupakan tingkat signifikansi terrendah yang
menandakan batas penolakan hipotesa nol dari data
observasi.
Penggunaan pendekatan P-value sebagai alat bantu
pengambilan keputusan sedikit lebih natural, dan hampir
semua software statistik menyertakan P-value bersama nilai
statistik uji.
Kesimpulan menolak Ho, jika P-value < α
25
Langkah Pengujian Hipotesa
1.Menentukan tujuan pengujian hipotesa
2. Formulasi hipotesa
3. Memilih uji statistik
4. Menentukan tingkat keberartian
5. Membangun daerah keputusan
6. Menghitung statistik uji
7. Menarik kesimpulan
27
28.
Langkah Pengujian Hipotesa
1.Menentukan tujuan pengujian hipotesa
Berdasarkan masalah yang menjadi fokus studi, untuk
menentukan parameter of interest sebagai tujuan
pengujiannya.
28
Tujuan pengujian hipotesa berawal dari maksud mempelajari sistem atau
menjawab permasalahan. Tujuan menjadi dasar utama dalam menentukan
populasi, memilih sampel, mengambil data dan mengujinya untuk memperoleh
kesimpulan yang selaras dengan tujuan tersebut.
29.
Langkah Pengujian Hipotesa
2.Formulasi hipotesa
Hipotesa diformulasikan berdasarkan praduga yang
dirumuskan sesuai dengan tujuan. Praduga tidak selalu
menjadi hipotesa nol, bahkan lebih diutamakan praduga
direfleksikan pada hipotesa alternatif.
29
Hipotesa alternatif H1 biasanya merepresentasikan permasalahan yang akan
dijawab atau teori yang akan diuji, sehingga formulasi spesifik menjadi krusial.
Hipotesa nol H0 menyatakan status quo atau equality yang meniadakan
(nullifies) atau berlawanan (opposes) H1 dan menjadi complement dari H1 yang
bersifat mutually exclusive. Penggunaan format pertidaksamaan dengan tanda
pengujian satu arah memberikan deskripsi lebih spesifik pada H1.
30.
Langkah Pengujian Hipotesa
3.Memilih uji statistik
Uji statistik dalam statistik inferensia dikelompokkan
menjadi dua, uji parametrik (berdistribusi) dan uji
nonparametrik. Uji statistik yang dipilih harus disesuaikan
dengan tujuan pengujian, hipotesa dan data (evidence)
yang diuji.
30
Uji parametrik mempertimbangkan tipe data dan distribusi data.
Pendekatan distribusi normal terkadang dapat dipergunakan dengan merujuk
Central Limit Theorem dan Law of Large Number
31.
Langkah Pengujian Hipotesa
4.Menentukan tingkat keberartian
Tingkat keberartian (terkadang juga disebut taraf nyata atau
tingkat ketelitian) menunjukkan luas daerah penolakan.
Tingkat keberartian sebenarnya juga menunjukkan
besarnya peluang terjadinya galat tipe I.
31
Semakin besar nilai tingkat keberartian semakin besar peluang galat tipe 1.
Sebaliknya semakin kecil nilainya semakin kecil pula peluang galat tipe 1, tetapi
juga semakin besar peluang galat tipe 2, bukannya bermakna semakin teliti.
Peluang galat tipe 2 beririsan dengan daerah penerimaan, sehingga sebenarnya
peluang galat tipe 2 tidak sama besar dengan satu dikurangi peluang galat tipe 1.
32.
Langkah Pengujian Hipotesa
5.Membangun daerah keputusan
Daerah keputusan terbagi menjadi dua, yaitu daerah
penolakan dan daerah penerimaan. Di antara kedua daerah
tersebut dibatasi oleh nilai kritis. Nilai kritis diperoleh
berdasarkan tingkat keberartian, dan distribusi (termasuk
parameter) yang dipergunakan dalam uji statistik.
32
Semakin besar nilai tingkat keberartian semakin luas daerah penolakan
(semakin besar peluang galat tipe 1).
Sebaliknya semakin kecil nilainya semakin luas daerah penerimaan (semakin
besar peluang galat tipe 2), bukannya bermakna semakin teliti.
33.
Langkah Pengujian Hipotesa
6.Menghitung statistik uji
Perhitungan statistik uji berdasarkan uji statistik yang dipilih
dan distribusi (termasuk parameter) yang dipergunakan.
Hasil perhitungan statistik uji tergantung kecukupan,
sebaran, kevalidan dan kesesuaian data.
33
Data yang keliru akan memberikan hasil yang keliru (garbage in garbage out)
Uji statistik yang keliru memberikan hasil yang keliru (failure makes inappropriate
result). Periksa datanya, pahami uji statistik yang dipilih, pelajari distribusi yang
dipergunakan, dan pastikan sesuai dengan tepat.
34.
Langkah Pengujian Hipotesa
7.Menarik kesimpulan
Kesimpulan ditarik berdasarkan hasil perhitungan statistik
uji, apakah berada di daerah penerimaan atau daerah
penolakan.
34
The truth or falsity of a statistical hypothesis is never known with absolute
certainty unless we examine the entire population. It should be made clear that
the decision procedure must include an awareness of the probability of a wrong
conclusion.
35.
Kekeliruan Yang KerapkaliTerjadi
Menggunakan data yang salah.
Data yang tidak tepat.
Distribusi (termasuk parameter) yang keliru.
Kesalahan dalam sampling.
Kesalahan dalam pengukuran.
Memilih pengujian yang salah.
Tidak sesuai dengan tujuan studi.
Formulasi hipotesa keliru.
Tidak sesuai dengan hipotesa.
35
36.
Kekeliruan Yang KerapkaliTerjadi
Membangun daerah keputusan yang salah.
Tingkat keberartian yang tidak tepat.
Kurang memperhatikan sebaran data yang berdampak
pada kurtosis dan skewness.
Terlalu ketat / longgar terhadap peluang galat.
Menarik kesimpulan yang salah.
Tidak berpijak kembali pada data (evidence) dan
hipotesa.
Analisa yang kurang lengkap dan keliru.
36
Fungsi Probabilitas DistribusiNormal
Parameter (mean) dan (standard deviation)
Probability Density Function, f(x)
Cummulative Distribution Function, F(x)
38
2
)
2
/(
)
(
.
2
)
(
2
2
x
e
x
f
f(x)
F(x)
x
di
i
f
x
F )
(
)
(
where erf is the error function
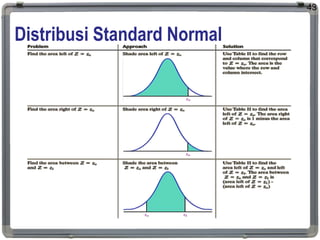
Distribusi Standard Normal
DistribusiStandard Normal adalah distribusi normal
yang mempunyai parameter = 0 dan = 1
Distribusi Standard Normal juga disebut dengan
Distribusi Z.
40
41.
Fungsi Distribusi StandardNormal
Parameter (mean) dan (standard deviation)
Probability Density Function, f(x)
Cummulative Distribution Function, F(x)
41
2
)
(
2
/
2
x
e
x
f
f(x)
F(x)
x
di
i
f
x
F )
(
)
(
where erf is the error function
Cara membaca TabelZ
46
z0 = -1.65
P(Z<-1,65) = 0,049471
dan
P(Z>-1,65) = 1 - 0,049471
= 0,950529
z0 = 1.28
P(Z<1,28) = 0,899727
dan
P(Z>1,28) = 1 - 0,899727
= 0,100273
Zα = - Z(1 - α)
jika α semakin besar maka
P(Z < zα) semakin besar dan
P(Z > zα) semakin kecil
47.
Cara membaca TabelZ
Nilai z0 saat P(Z < z0) = 0,05
Nilai z0 saat P(Z < z0) = 0,90
47
z0 = -1,65 + (
(0,05 – 0,049471)
X (-1,64 – (-1,65)))
(0,050503 – 0,049471)
= -1,65 + ( 0,5126 X 0,01)
= -1,644874
z0 = 1,28 + (
(0,90 – 0,899727)
X (1,29 – 1,28))
(0,901475 – 0,899727)
= 1,28 + ( 0,1562 X 0,01)
= 1,281562
48.
Cara membaca TabelZ
Nilai P(Z < z0) saat z0 = -1,645
Nilai P(Z < z0) saat z0 = 1,285
48
P-value = 0,049471 + (
(-1,645 – (-1,65))
X (0,050503 – 0,049471))
(-1,64 – (-1,65))
= 0,049471 + ( 0,5 X 0,001032)
= 0,049987
P-value = 0,899727 + (
(1,285 – 1,28)
X (0,901475 – 0,899727))
(1,29 – 1,28)
= 0,899727 + ( 0,5 X 0,001748)
= 0,900601
49.
Distribusi Binomial
Distribusi Binomialmenunjukkan sebaran variabel
acak banyaknya sukses dari n buah percobaan
Bernoulli bebas dalam rentang semua gagal (0)
hingga semua sukses (n), X{0,1,...,n}, dengan
probabilitas sukses setiap percobaan sebesar p.
49
50.
Distribusi Binomial
Hubungan DistribusiBinomial dengan Distribusi
Normal
Jika X adalah variabel acak independen berdistribusi
Binomial (n,p), di mana n sangat besar (n), maka X
dapat didekati dengan distribusi Normal (,) dengan =
n.p dan 2= n.p.(1 – p), dan didekati dengan distribusi
Normal Standar dengan
di mana n.p > 5 dan n.(1 – p) > 5
50
)
1
.(
.
.
p
p
n
p
n
X
Z
51.
Distribusi Binomial
Hubungan DistribusiBinomial dengan Distribusi
Normal
Jika diambil sampel acak sebanyak n dari populasi
berdistribusi normal dengan anggota yang sangat besar
(N) dan terdapat X (<n) observasi bagian dari sampel
tersebut yang sukses (masuk dalam kategori yang
dimaksud), maka rasio antara X dan n merupakan titik
estimator dari proporsi populasi (dengan rata-rata sebesar
p dan variansi sebesar (p.(1–p))/n) atas kesuksesan
(kategori yang dimaksud) tersebut. Di mana n dan p
adalah parameter distribusi binomial.
51
52.
Fungsi Distribusi Binomial
Parameter p (probability of success) dan n (number of trials)
Probability Mass Function, p(x)
Cummulative Distribution Function, F(x)
52
other
n
x
p
p
x
n
x
p
x
n
x
0
,...,
1
,
0
)
1
(
)
(
p(x)
F(x)
0
)
(
0
0
)
(
0
x
i
p
x
x
F
x
i
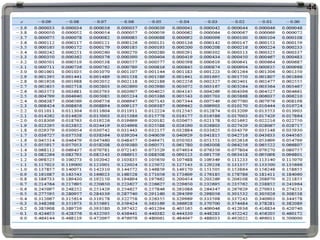
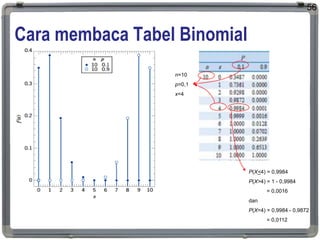
Cara membaca TabelBinomial
Nilai x0 saat P(X < x0) < 0,05 dengan n=10 p=0,7
Nilai x0 saat P(X > x0) < 0,10 dengan n=10 p=0,7
57
x0 = 4, karena P(X < 4) = 0,0473 < α, sedangkan P(X < 5) = 0,1503 > α
x0 = 9, karena P(X > 9) = 1 - 0,9718 = 0,0282 < α,
sedangkan P(X > 8) = 1 - 0,8507 = 0,1493 > α
58.
Cara membaca TabelBinomial
Nilai P(X < x0) saat x0 = 3 dengan n=10 p=0,7
Nilai P(X > x0) saat x0 = 8 dengan n=10 p=0,7
58
P(X < 3) = 0,0106
P(X > 8) = 1 - 0,8507 = 0,1493
59.
Cara membaca TabelBinomial
Nilai p saat P(X < x0) = 0,05 dengan x0 = 3 dan n = 10
Nilai p saat P(X > x0) = 0,10 dengan x0 = 8 dan n = 10
59
p = 0,6 + (
(0,05 – 0,0548)
X (0,7 – 0,6))
(0,0106 – 0,0548)
= 0,6 + ( 0,108597 X 0,1)
= 0,61086
p = 0,6 + (
(0,10 – 0,0464)
X (0,7 – 0,6))
(0,1493 – 0,0464)
= 0,6 + ( 0,520894 X 0,1)
= 0,652089
Uji Hipotesa Proporsidgn MS Excel
76
Parameter P-value Test Table of
Left-tailed Right-tailed Statistics Distribution
Single
proportion n
small sample
size
BINOMDIST(X;
n;p;TRUE)
1-
BINOMDIST(X;
n;p;TRUE)
X BINOM.INV(n;
p;)
Single
proportion n
large sample
size
NORMDIST(X;n*
p; SQRT(n*p*(1-
p));TRUE)
1-
NORMDIST(X;n*
p; SQRT(n*p*(1-
p));TRUE)
NORMSINV(PVal
ue)
NORMSINV()
NORMDIST(Pro
p;p; SQRT(p*(1-
p)/n);TRUE)
1-
NORMDIST(pro
p;p; SQRT(p*(1-
p)/n);TRUE)
Two sample
proportion
NORMSDIST((Prop1-
Prop2)/SQRT(PropBar*(1-
PropBar)*((1/n1)+(1/n2)))
NORMSINV(PVal
ue)
NORMSINV()
77.
Uji Hipotesa Proporsidgn MathCAD
77
Parameter Test Significance Level Table of
Statistics Left-tailed Right-tailed Distribution
Single sample
proportion
pnorm(z,0,1) 1- pnorm(z,0,1) qnorm(,0,1)
Two sample
proportion
78.
Uji Hipotesa Proporsidgn MatLab
Single or two sample
[h,p] = ztest(Z0,0,1,,tail)
single sample
two sample
78
#10 Statistika dapat menjadi alat bantu dalam menyelesaikan masalah. Mulai dari saat mengumpulkan data, mengolah, menginterpresikan, menganalisa dan mensitesanya. Namun saat keliru menetapkan populasi atau keliru memilih sampel, serta keliru mendeskripsikan variabel yang akan diambil datanya, melalaikan tujuan penelitian, maka hasil pengolahannyapun akan menjadi sampah. Demikian pula meskipun data yang diambil benar dan representatif, namun metode dan alat pengolahannya pun keliru yang dipilih atau keliru cara mempergunakannya, maka hasilnya pun akan menjadi sampah. Sehingga perlu kita pahami bahwa statistika cuma alat berbasis model matematis, ada angka dimasukkan akan mengeluarkan hasil, entah itu benar atau sampah.
#11 Alat statistika bukan tongkat sihir, apapun dan bagaimanapun keadaan datanya dengan tongkat sihir ajaib bisa mengubahnya menjadi hasil yang sesuai dengan tujuan penelitian. Metode statistika pun bukan ramuan sihir, apapun dan bagaimanapun keadaan datanya diolah dalam ramuan sihir ajaib bisa mewujudkan hasil yang sesuai dengan tujuan penelitian.
#63 Karena 8 lebih kecil daripada 70% X 15, maka menghitung P(X < 8). Berdasarkan alpha/2 sebesar 0,05, critical value pada left tailed adalah 6 (karena 7 melebihi), dan critical value pada right tailed adalah 14 (karena 13 melebihi). Kesimpulan gagal menolak Ho karena P-value (0,2622) > alpha (0,10)
#66 Kesimpulan menolak Ho karena statistik uji (z=2,04) > critical value (z=1,645), atau P-value (0,0207) < alpha (0,05)
#67 Kesimpulan menolak Ho karena statistik uji (z=-1,95) < critical value (z=-1,645), atau P-value (0,0256) < alpha (0,05)
#72 Kesimpulan menolak Ho karena statistik uji (Z=2,9) > critical value (Z=1,645), atau P-value (0,0019) < alpha (0,05)
#73 Kesimpulan gagal menolak Ho karena left tailed critical value (z=-1,645) < statistik uji (z=1,34) < right tailed critical value (z=1,645), atau P-value (0,18) > alpha (0,05)







































































![Uji Hipotesa Proporsi dgn MatLab
Single or two sample
[h,p] = ztest(Z0,0,1,,tail)
single sample
two sample
78](https://image.slidesharecdn.com/sinf202004-210811090528/85/Modul-Ajar-Statistika-Inferensia-ke-4-Uji-Hipotesa-Proporsi-Parametrik-78-320.jpg)





































































