Downloaded 181 times


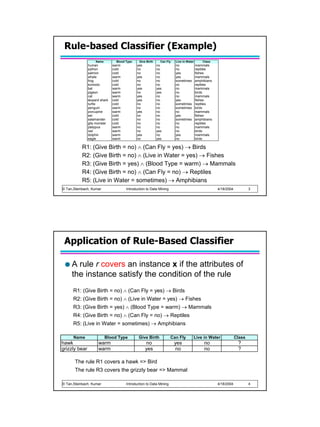






![Rule Growing (Examples)
CN2 Algorithm:
– Start from an empty conjunct: {}
– Add conjuncts that minimizes the entropy measure: {A}, {A,B}, …
– Determine the rule consequent by taking majority class of instances
covered by the rule
RIPPER Algorithm:
– Start from an empty rule: {} => class
– Add conjuncts that maximizes FOIL’s information gain measure:
R0: {} => class (initial rule)
R1: {A} => class (rule after adding conjunct)
Gain(R0, R1) = t [ log (p1/(p1+n1)) – log (p0/(p0 + n0)) ]
where t: number of positive instances covered by both R0 and R1
p0: number of positive instances covered by R0
n0: number of negative instances covered by R0
p1: number of positive instances covered by R1
n1: number of negative instances covered by R1
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 19
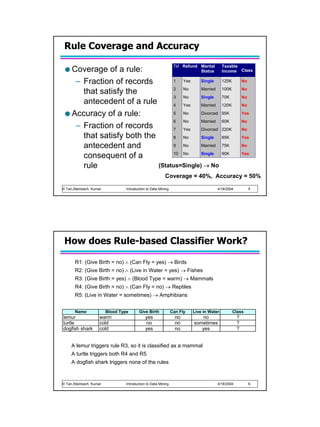
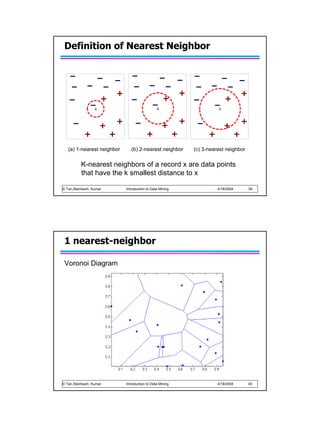
Instance Elimination
Why do we need to
eliminate instances?
R3 R2
– Otherwise, the next rule is
R1
identical to previous rule + + + + +
+ ++ +
Why do we remove class = +
+
+++
+ +
+
+
+
+ +
positive instances? + + + +
+ + +
+ +
– Ensure that the next rule is -
- -
-
- - -
-
different - -
class = - - -
Why do we remove -
-
-
-
negative instances? -
- -
-
– Prevent underestimating -
accuracy of rule
– Compare rules R2 and R3
in the diagram
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 20](https://image.slidesharecdn.com/chap5alternativeclassification-121113234511-phpapp02/85/rule-based-classifier-10-320.jpg)










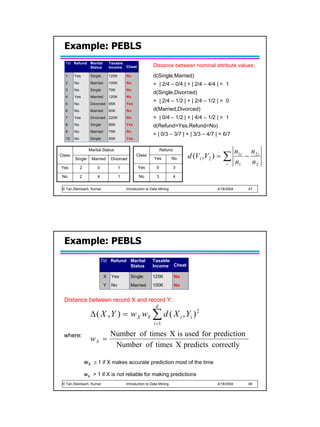






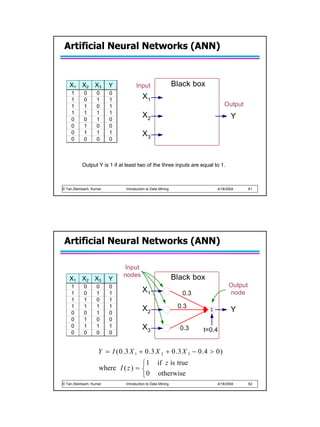
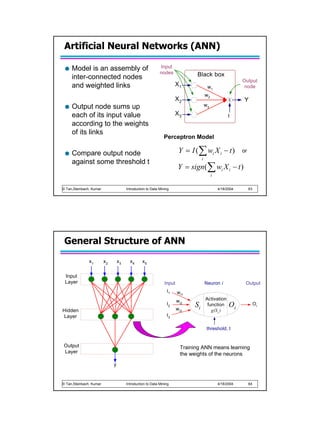
![Algorithm for learning ANN
Initialize the weights (w0, w1, …, wk)
Adjust the weights in such a way that the output
of ANN is consistent with class labels of training
examples
– Objective function: E = ∑ [Yi − f ( wi , X i )]
2
i
– Find the weights wi’s that minimize the above
objective function
e.g., backpropagation algorithm (see lecture notes)
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 65
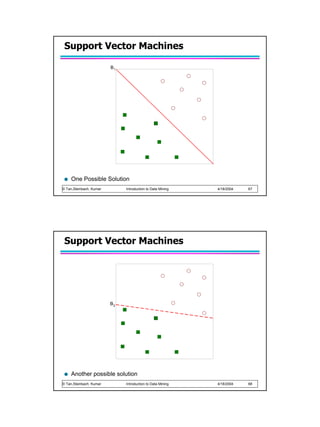
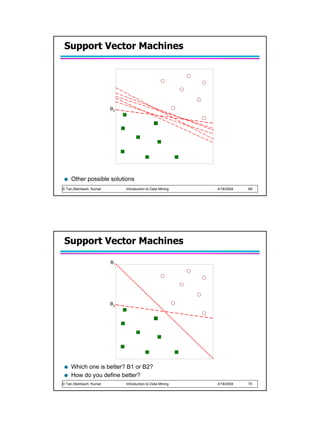
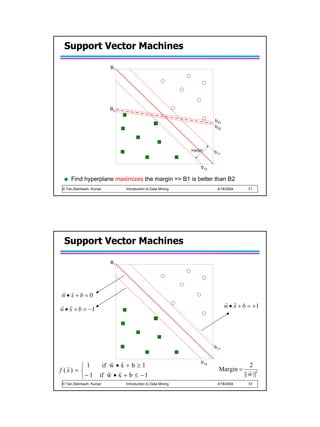
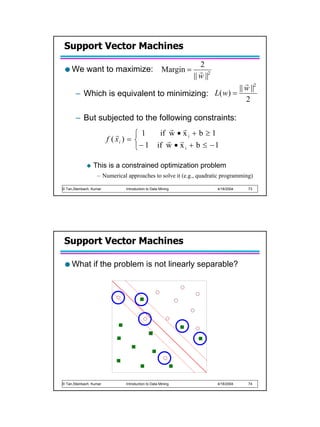
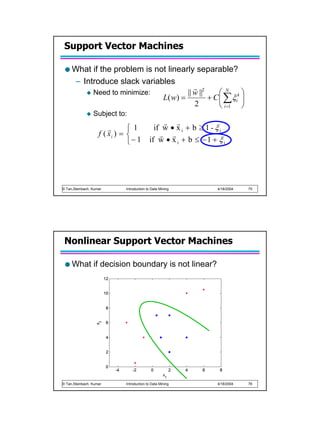
Support Vector Machines
Find a linear hyperplane (decision boundary) that will separate the data
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 66](https://image.slidesharecdn.com/chap5alternativeclassification-121113234511-phpapp02/85/rule-based-classifier-33-320.jpg)
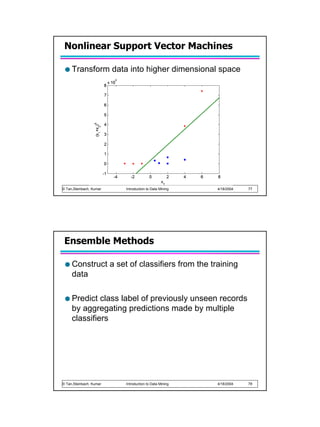



This document provides an overview of rule-based classification techniques for data mining. It describes how rule-based classifiers work by using a set of "if-then" rules to classify records. Each rule has a condition part and a class label part. It discusses evaluating rule coverage and accuracy, and how to generate rules directly from data using sequential covering algorithms or indirectly from other models like decision trees. The key steps of sequential covering include growing rules, eliminating instances, evaluating rules, stopping criteria, and pruning rules.















































