Downloaded 284 times














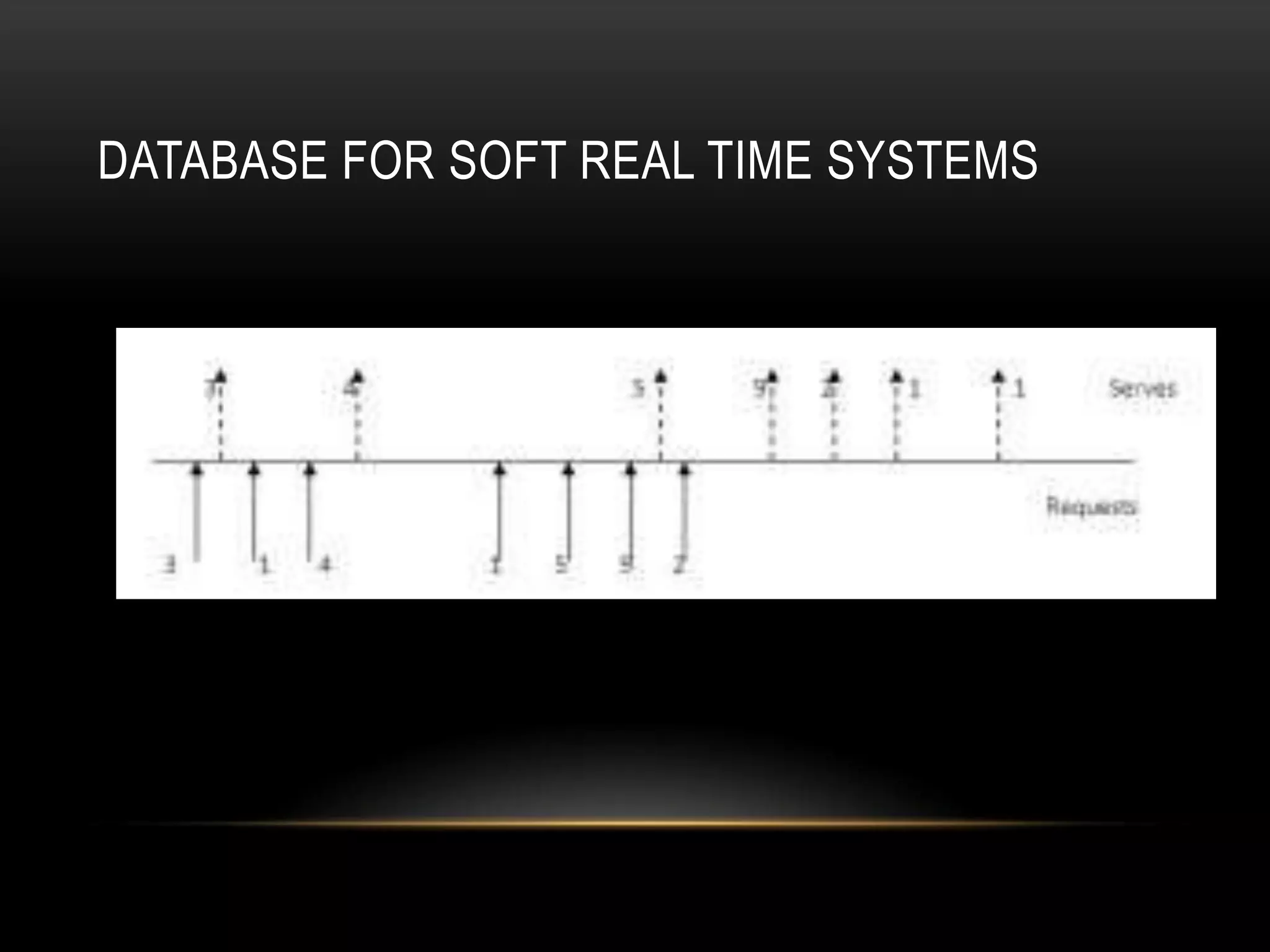


Real-time databases are optimized for predictable response times compared to general purpose databases. They often relax ACID properties like durability to meet deadlines. Transactions in real-time databases have deadlines and priorities to schedule access. Main memory databases improve speed by storing the entire database in RAM, but require disk storage for backups, logs, and larger datasets. Adaptive Earliest Deadline scheduling algorithms prioritize transactions likely to meet deadlines over those that may miss them. Disk-based scheduling like scan policies can enable soft real-time constraints for databases.










































































































