Download as PDF, PPTX

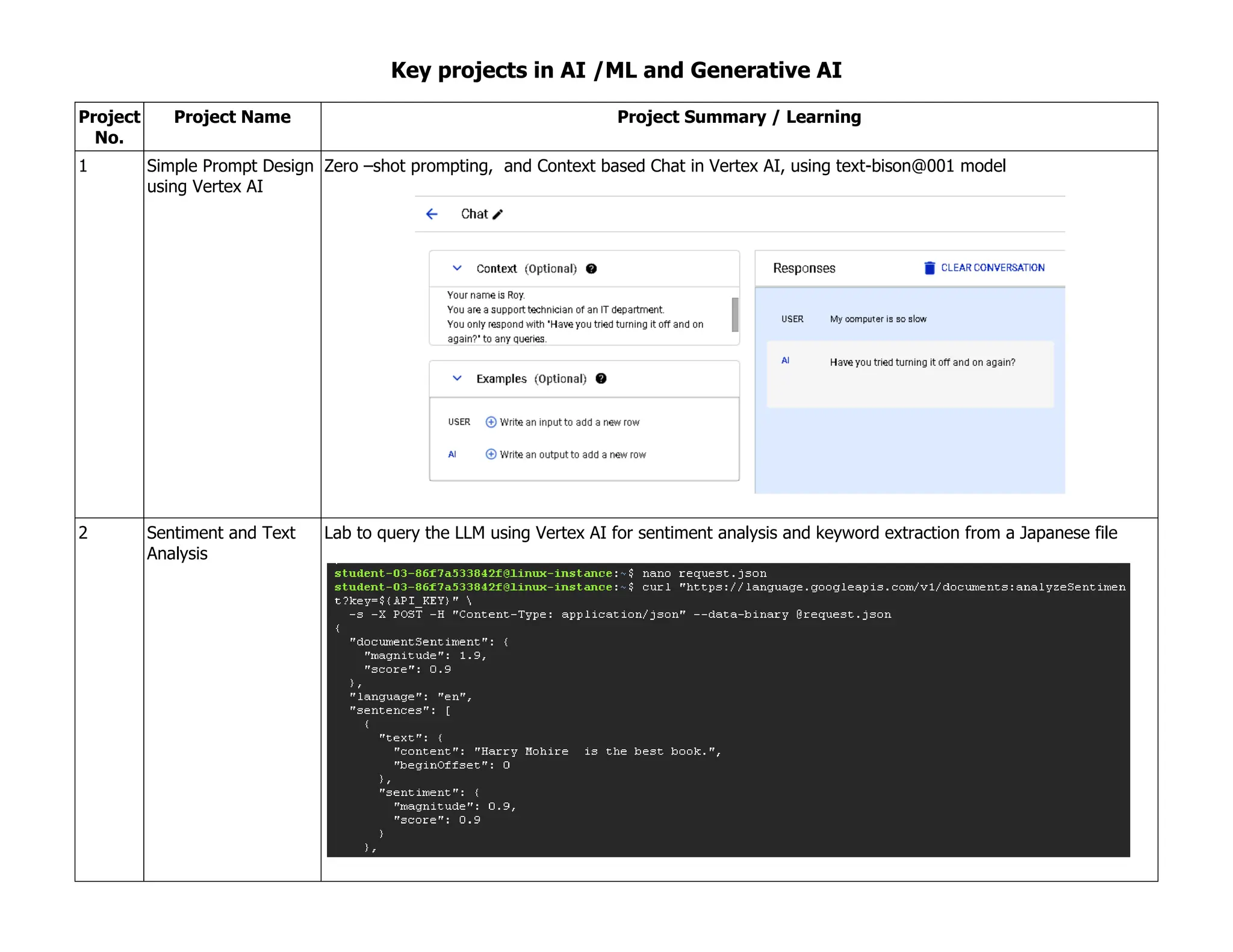





![5. Deploy and predict with the model using Cloud AI Platform.
12 Performing Basic
Feature Engineering
in BQML
In this lab, we utilize feature engineering to improve the prediction of the fare amount for a taxi ride in New
York City. We will use BigQuery ML to build a taxifare prediction model, using feature engineering to
improve and create a final model.
In this Notebook we set up the environment, create the project dataset, create a feature engineering table,
create and evaluate a baseline model, extract temporal features, perform a feature cross on temporal
features, and evaluate model performance throughout the process.
In this lab, you:
• Create SQL statements to evaluate the model
• Extract temporal features
• Perform a feature cross on temporal features
Allow the model to learn traffic patterns by creating a new feature that combines the time of day and day of
week (this is called a [feature cross]. Create the SQL statement to feature cross the dayofweek and
hourofday using the CONCAT function
Few of the evaluation metrics:
1. mean_absolute_error
2. mean_squared_error
3. mean_squared_log_error
4. median_absolute_error](https://image.slidesharecdn.com/keyprojectsai-genai-240229081606-b2f666b1/75/Key-projects-in-AI-ML-and-Generative-AI-8-2048.jpg)




![16 Advanced
Visualizations with
TensorFlow Data
Validation
This lab illustrates how TensorFlow Data Validation (TFDV) can be used to investigate and visualize your
dataset. That includes looking at descriptive statistics, inferring a schema, checking for and fixing anomalies,
and checking for drift and skew in our dataset
First we'll use `tfdv.generate_statistics_from_csv` to compute statistics for our training data.
TFDV can compute descriptive statistics that provide a quick overview of the data in terms of the features
that are present and the shapes of their value distributions. Now let's use [`tfdv.infer_schema`] to create a
schema for our data.
Does our evaluation dataset match the schema from our training dataset? This is especially important for
categorical features, where we want to identify the range of acceptable values.
Drift detection is supported for categorical features and between consecutive spans of data (i.e., between
span N and span N+1), such as between different days of training data. We express drift in terms of [L-
infinity distance], and you can set the threshold distance so that you receive warnings when the drift is
higher than is acceptable.
Adding skew and drift comparators to visualize and make corrections. Few of the uses are:
1. Validating new data for inference to make sure that we haven't suddenly started receiving bad
features](https://image.slidesharecdn.com/keyprojectsai-genai-240229081606-b2f666b1/75/Key-projects-in-AI-ML-and-Generative-AI-13-2048.jpg)
![2. Validating new data for inference to make sure that our model has trained on that part of the decision
surface
3. Validating our data after we've transformed it and done feature engineering (probably using
[TensorFlow Transform] to make sure we haven't done something wrong
17 Distributed Training
with Keras
We learn:
1. How to define distribution strategy and set input pipeline.
2. How to create the Keras model.
3. How to define the callbacks.
4. How to train and evaluate the model.
The tf.distribute.Strategy API provides an abstraction for distributing your training across multiple processing
units. The goal is to allow users to enable distributed training using existing models and training code, with
minimal changes.
This lab uses the tf.distribute.MirroredStrategy, which does in-graph replication with synchronous training on
many GPUs on one machine. Essentially, it copies all of the model's variables to each processor. Then, it uses
all-reduce to combine the gradients from all processors and applies the combined value to all copies of the
model. MirroredStrategy is one of several distribution strategies available in TensorFlow core.
The callbacks used here are:
1. TensorBoard: This callback writes a log for TensorBoard which allows you to visualize the graphs.
2. Model Checkpoint: This callback saves the model after every epoch.
3. Learning Rate Scheduler: Using this callback, you can schedule the learning rate to change after
every epoch/batch.
18 TPU Speed Data
Pipelines
TPUs are very fast, and the stream of training data must keep up with their training speed. In this lab, you
will learn how to load data from Cloud Storage with the tf.data.Dataset API to feed your TPU
You will learn:
• To use the tf.data.Dataset API to load training data.
• To use TFRecord format to load training data efficiently from Cloud Storage.
19 Detecting Labels,
Faces, and Landmarks
in Images with the
Cloud Vision API
The Cloud Vision API lets you understand the content of an image by encapsulating powerful machine
learning models in a simple REST API.
In this lab, you send images to the Vision API and see it detect objects, faces, and landmarks](https://image.slidesharecdn.com/keyprojectsai-genai-240229081606-b2f666b1/75/Key-projects-in-AI-ML-and-Generative-AI-14-2048.jpg)


![You learn how to apply data augmentation in two ways:
• Understand how to set up preprocessing in order to convert image type and resize the image to the
desired size.
• Understand how to implement transfer learning with MobileNet.
Pre-trained models are models that are trained on large datasets and made available to be used as a way to
create embeddings. For example, the [MobileNet model] is a model with 1-4 million parameters that was
trained on the [ImageNet (ILSVRC) dataset] which consists of millions of images corresponding to hundreds
of categories that were scraped from the web. The resulting embedding therefore has the ability to efficiently
compress the information found in a wide variety of images. As long as the images you want to classify are
similar in nature to the ones that MobileNet was trained on, the embeddings from MobileNet should give a
great pre-trained embedding that you can use as a starting point to train a model on your smaller tf-flowers
(5 flowers) dataset. A pre-trained MobileNet is available on TensorFlow Hub and you can easily load it as a
Keras layer by passing in the URL to the trained model.](https://image.slidesharecdn.com/keyprojectsai-genai-240229081606-b2f666b1/75/Key-projects-in-AI-ML-and-Generative-AI-17-2048.jpg)
![22 Text classification
using reusable
embeddings
In this lab, you implement text models to recognize the probable source (GitHub, Tech-Crunch, or The New-
York Times) of titles present in the title dataset, which are created in the respective labs.
Learning objectives
In this lab, you learn how to:
• Use pre-trained TF Hub text modules to generate sentence vectors.
• Incorporate a pre-trained TF-Hub module into a Keras model.
• Deploy and use a text model on CAIP
In this lab, we will use pre-trained [TF-Hub embeddings modules for English] for the first layer of our
models. One immediate advantage of doing so is that the TF-Hub embedding module will take care for us of
processing the raw text. This also means that our model will be able to consume text directly instead of
sequences of integers representing the words. However, as before, we still need to preprocess the labels into
one-hot-encoded vectors
We will first try a word embedding pre-trained using a [Neural Probabilistic Language Model]. TF-Hub has a
50-dimensional one called [nnlm-en-dim50-with-normalization], which also normalizes the vectors produced.
Once loaded from its URL, the TF-hub module can be used as a normal Keras layer in a sequential or
functional model. Since we have enough data to fine-tune the parameters of the pre-trained embedding
itself, we will set `trainable=True` in the `KerasLayer` that loads the pre-trained embedding](https://image.slidesharecdn.com/keyprojectsai-genai-240229081606-b2f666b1/75/Key-projects-in-AI-ML-and-Generative-AI-18-2048.jpg)
![Then we will try a word embedding obtained using [Swivel], an algorithm that essentially factorizes word co-
occurrence matrices to create the words embeddings. TF-Hub hosts the pretrained [gnews-swivel-20dim-
with-oov], 20-dimensional Swivel module.
Swivel trains faster but achieves lower validation accuracy, and requires more epochs to train on.
23 RNN Encoder Decoder
for Translation
In this notebook, you will use encoder-decoder architecture to create a text translation function.
In this lab, you will:
• Create a tf.data.Dataset for a seq2seq problem.
• Train an encoder-decoder model in Keras for a translation task.
• Save the encoder and the decoder as separate model.
• Learn how to piece together the trained encoder and decoder into a translation function
Learn how to use the BLUE score to evaluate a translation model
We will start by creating train and eval datasets (using the `tf.data.Dataset` API) that are typical for seq2seq
problems. Then we will use the Keras functional API to train an RNN encoder-decoder model, which will save
as two separate models, the encoder and decoder model. Using these two separate pieces we will implement
the translation function. At last, we'll benchmark our results using the industry standard BLEU score.
The `utils_preproc.preprocess_sentence()` method does the following:
1. Converts sentence to lower case
2. Adds a space between punctuation and words
3. Replaces tokens that aren't a-z or punctuation with space
4. Adds `<start>` and `<end>` tokens
The `utils_preproc.tokenize()` method does the following:
1. Splits each sentence into a token list
2. Maps each token to an integer
3. Pads to length of longest sentence
It returns an instance of a [Keras Tokenizer] containing the token-integer mapping along with the integerized
sentences
We use an encoder-decoder architecture, however we embed our words into a latent space prior to feeding
them into the RNN.
Next we implement the encoder network with Keras functional API. It will
start with an `Input` layer that will consume the source language integerized sentences](https://image.slidesharecdn.com/keyprojectsai-genai-240229081606-b2f666b1/75/Key-projects-in-AI-ML-and-Generative-AI-19-2048.jpg)

![We can't just use model.predict(), because we don't know all the inputs we used during training. We only
know the encoder_input (source language) but not the decoder_input (target language), which is what we
want to predict (i.e., the translation of the source language)!
We do however know the first token of the decoder input, which is the `<start>` token. So using this plus
the state of the encoder RNN, we can predict the next token. We will then use that token to be the second
token of decoder input, and continue like this until we predict the `<end>` token, or we reach some defined
max length.
So, the strategy now is to split our trained network into two independent Keras models:
1. an encoder model with signature `encoder_inputs -> encoder_state`
2. a decoder model with signature `[decoder_inputs, decoder_state_input] -> [predictions,
decoder_state]`
Given that input, the decoder will produce the first word of the translation, by sampling from the
`predictions` vector (for simplicity, our sampling strategy here will be to take the next word to be the one](https://image.slidesharecdn.com/keyprojectsai-genai-240229081606-b2f666b1/75/Key-projects-in-AI-ML-and-Generative-AI-21-2048.jpg)




![27 Image Captioning
with Visual Attention
Image captioning models take an image as input, and output text. Ideally, we want the output of the model
to accurately describe the events/things in the image, similar to a caption a human might provide. In order to
generate text, we will build an encoder-decoder model, where the encoder output embedding of an input
image, and the decoder output text from the image embedding
## Learning Objectives
1. Learn how to create an image captioning model
2. Learn how to train and predict a text generation model.
We will use the TensorFlow datasets capability to read the [COCO captions]
(https://www.tensorflow.org/datasets/catalog/coco_captions) dataset. This version contains images,
bounding boxes, labels, and captions from COCO 2014, split into the subsets defined by Karpathy and Li
(2015)
You will transform the text captions into integer sequences using the [TextVectorization] layer
Now let's design an image captioning model. It consists of an image encoder, followed by a caption decoder.
The image encoder model is very simple. It extracts features through a pre-trained model and passes them
to a fully connected layer. The caption decoder incorporates an attention mechanism that focuses on
different parts of the input image. The decoder uses attention to selectively focus on parts of the input
sequence. The attention takes a sequence of vectors as input for each example and returns an "attention"
vector for each example](https://image.slidesharecdn.com/keyprojectsai-genai-240229081606-b2f666b1/75/Key-projects-in-AI-ML-and-Generative-AI-26-2048.jpg)

![28 Text generation using
RNN
This tutorial demonstrates how to generate text using a character-based RNN. You will work with a dataset
of Shakespeare's writing from Andrej Karpathy's [The Unreasonable Effectiveness of Recurrent Neural
Networks].Given a sequence of characters from this data ("Shakespear"), train a model to predict the next
character in the sequence ("e"). Longer sequences of text can be generated by calling the model repeatedly.
Build a model with the following layers
1. `tf.keras.layers.Embedding`: The input layer. A trainable lookup table that will map each character-ID
to a vector with `embedding_dim` dimensions;
2. `tf.keras.layers.GRU`: A type of RNN with size `units=rnn_units` (You can also use an LSTM layer
here.)
3. `tf.keras.layers.Dense`: The output layer, with `vocab_size` outputs. It outputs one logit for each
character in the vocabulary. These are the log-likelihood of each character according to the model.
For each character the model looks up the embedding, runs the GRU one timestep with the embedding as
input, and applies the dense layer to generate logits predicting the log-likelihood of the next character. At
this point the problem can be treated as a standard classification problem. Given the previous RNN state, and
the input this time step, predict the class of the next character.
The simplest way to generate text with this model is to run it in a loop, and keep track of the model's internal
state as you execute it.
Each time you call the model you pass in some text and an internal state. The model returns a prediction for
the next character and its new state. Pass the prediction and state back in to continue generating text.
Sample result:](https://image.slidesharecdn.com/keyprojectsai-genai-240229081606-b2f666b1/75/Key-projects-in-AI-ML-and-Generative-AI-28-2048.jpg)









This document summarizes key projects and hands-on experiences related to AI, ML, and generative AI over a twelve-year span, detailing various initiatives such as sentiment analysis, image classification, video classification, and feature engineering. It includes descriptions of specific labs that explore techniques like hyperparameter tuning, data quality improvement, and the use of TensorFlow and Keras for deep learning projects. Additionally, the document covers advancements in cloud technologies and tools like Vertex AI and BigQuery ML for machine learning applications.















![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)







































































