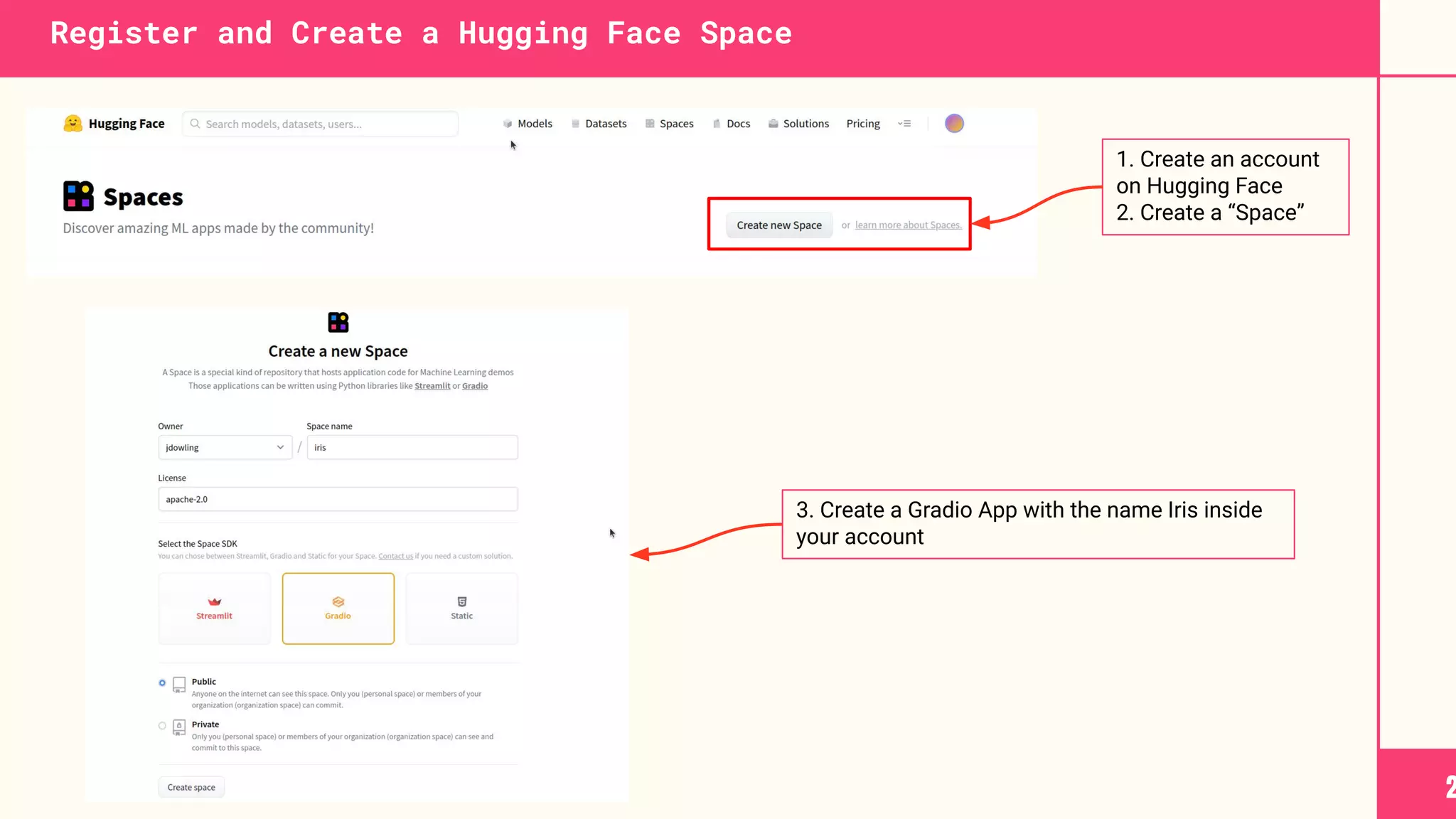
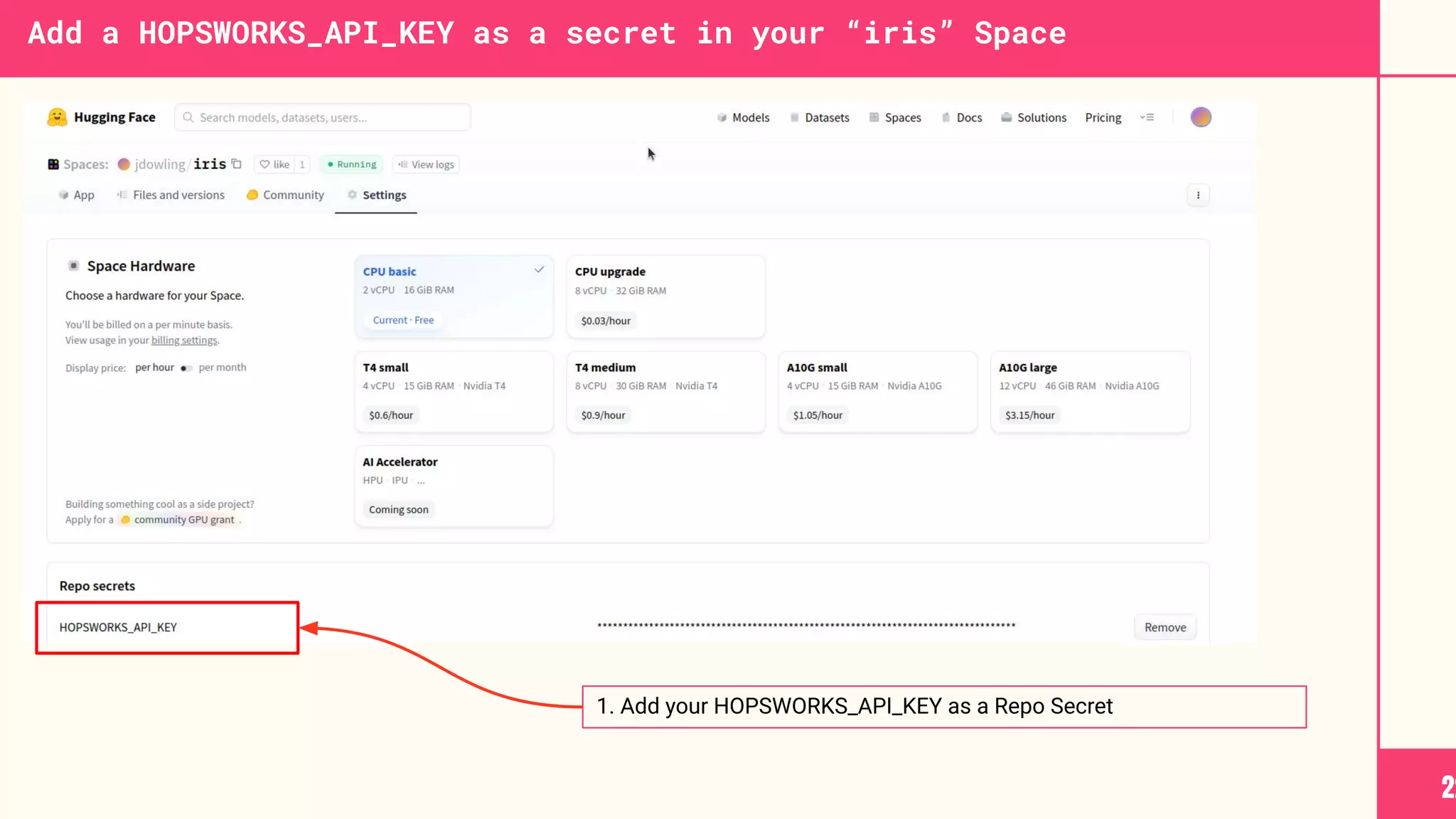
Download as PDF, PPTX










![[Image from https://scikit-learn.org/stable/modules/neighbors.html#classification]
As we can see here two
features (sepal_length and
sepal_width) is not enough
features to separate the three
different varieties (setosa,
versicolor, virginica).
Classify Iris Flowers with K-Nearest Neighbors](https://image.slidesharecdn.com/pyconsweden2022-dowling-serverlessmlwithhopsworks-221104124102-9ce2103f/75/PyCon-Sweden-2022-Dowling-Serverless-ML-with-Hopsworks-pdf-25-2048.jpg)
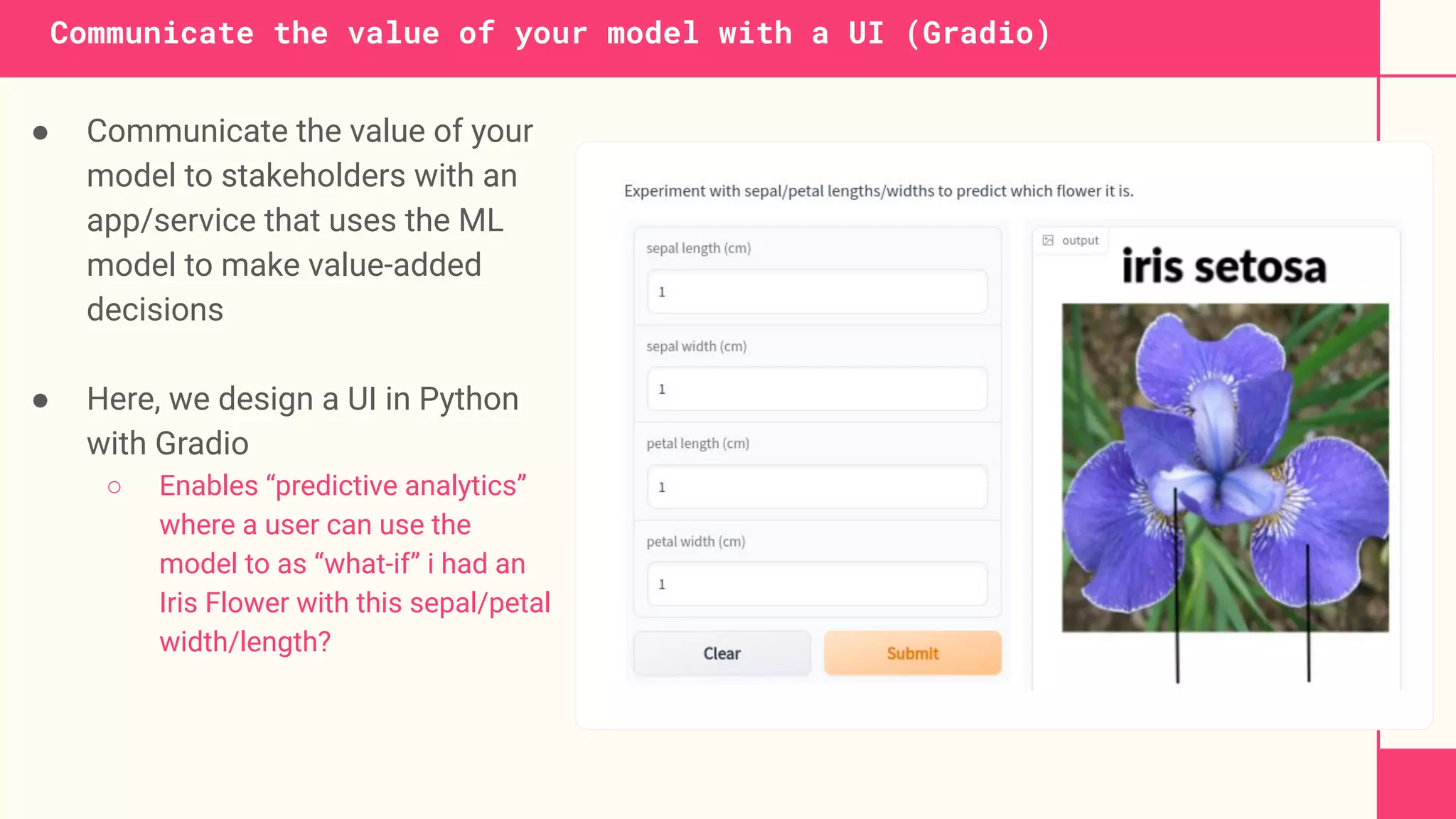
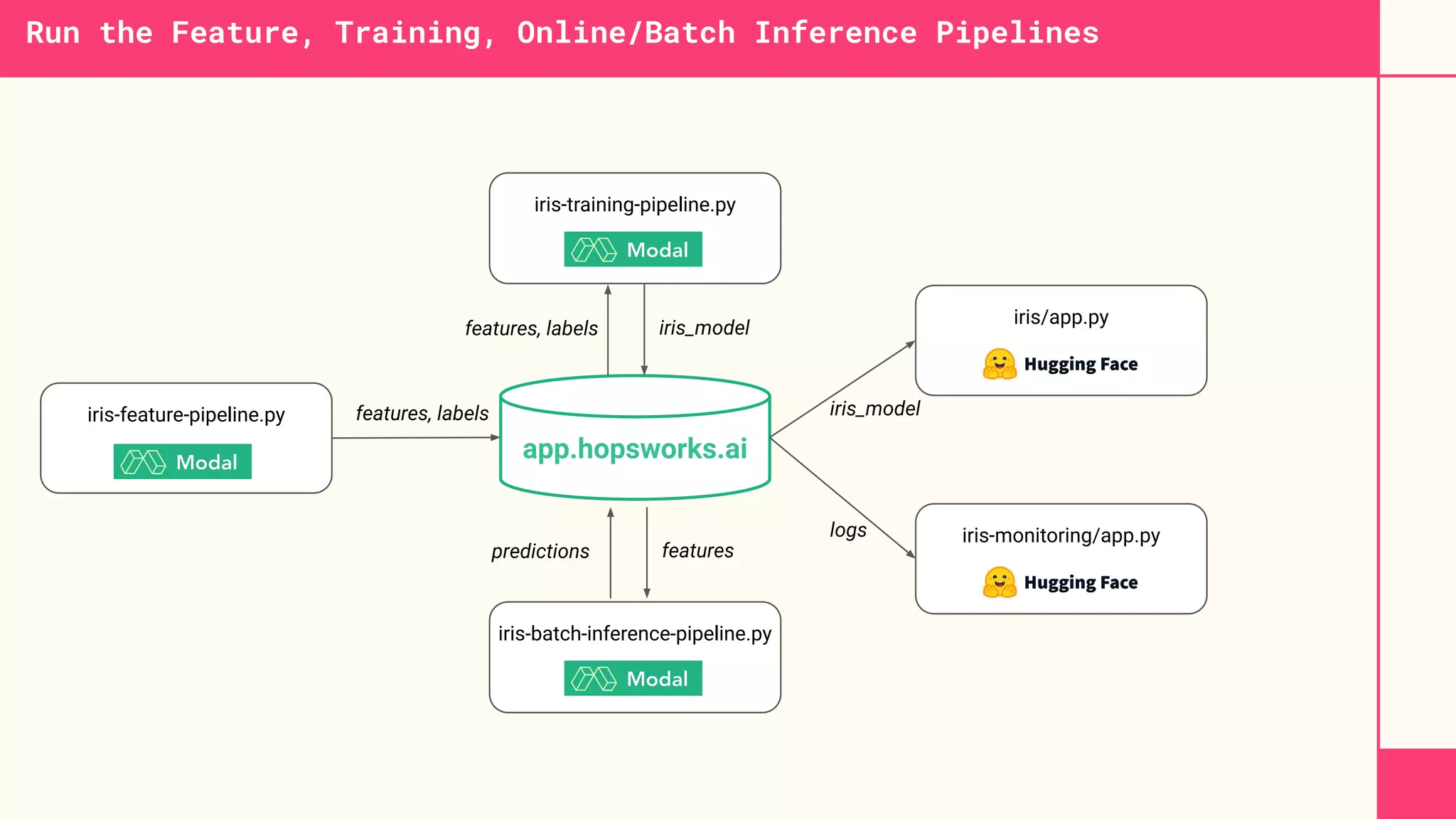
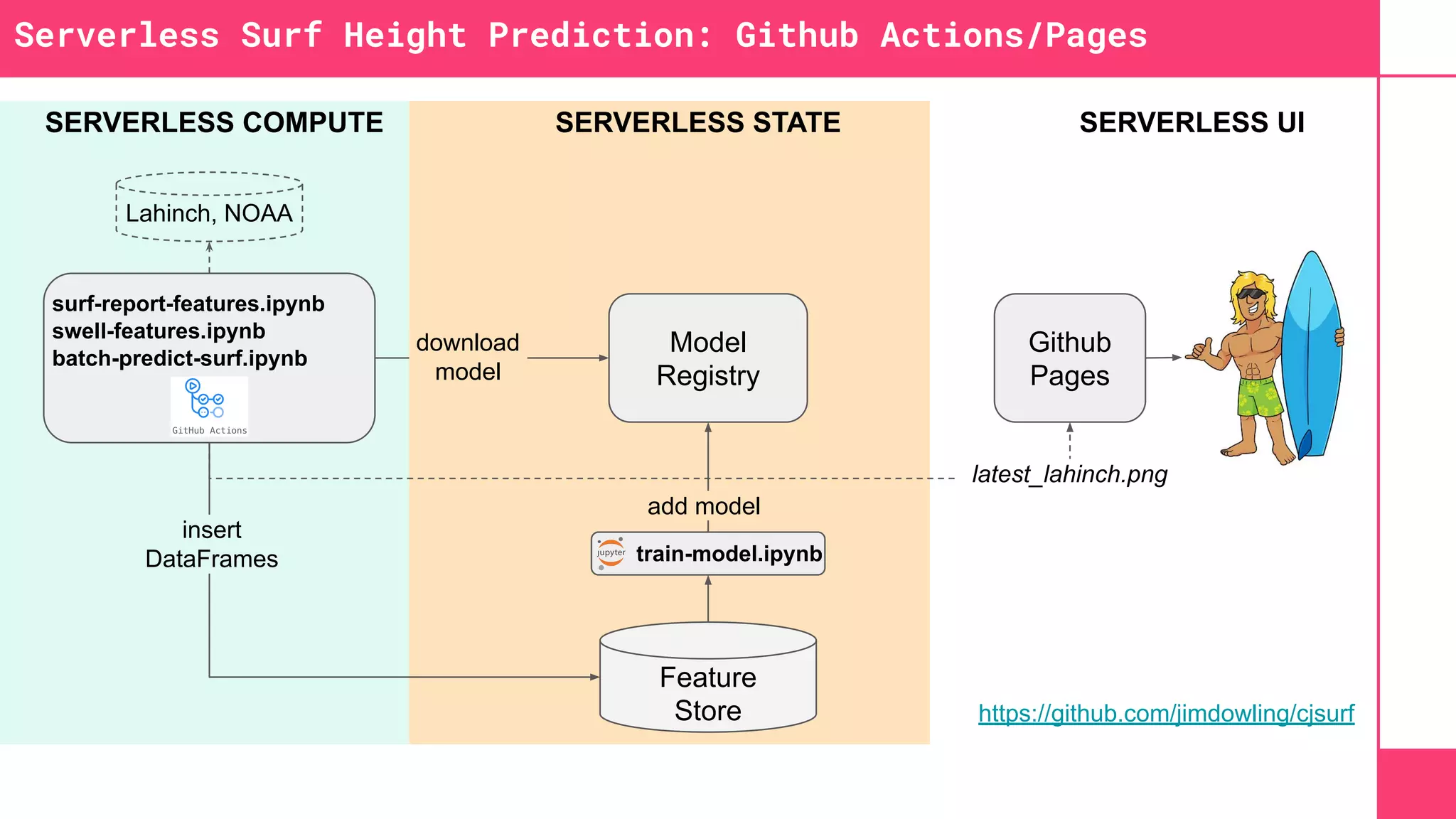


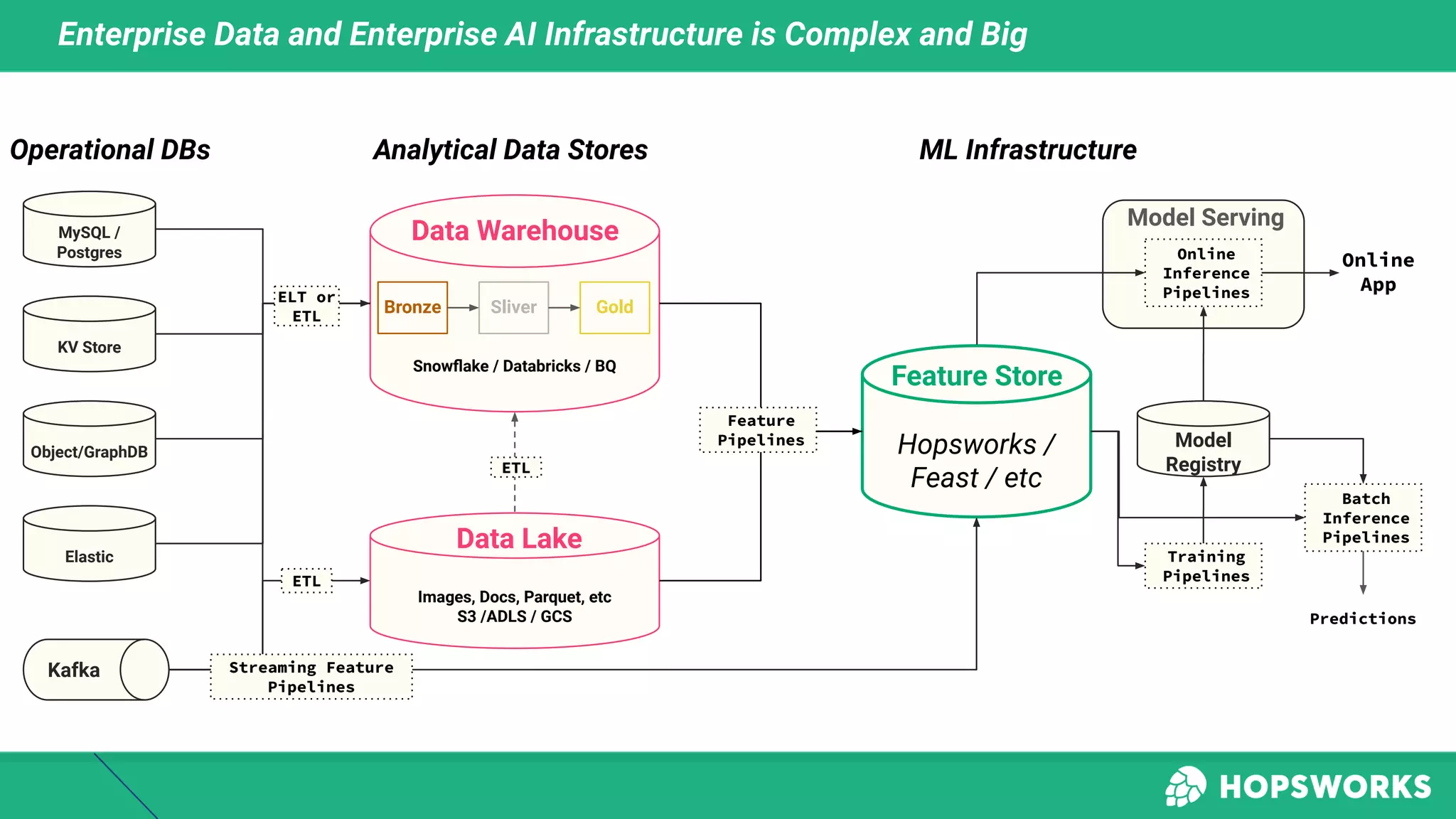
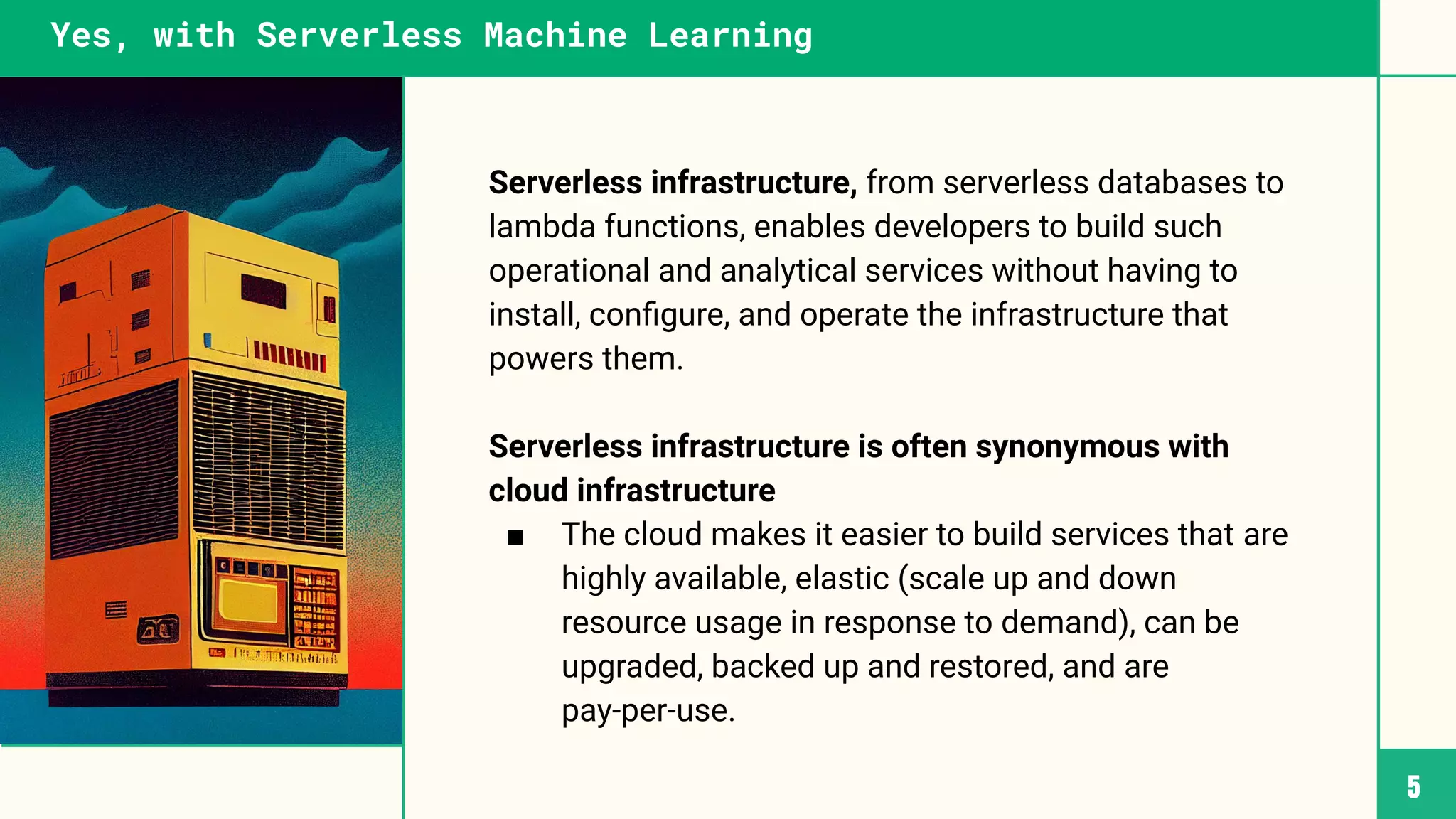
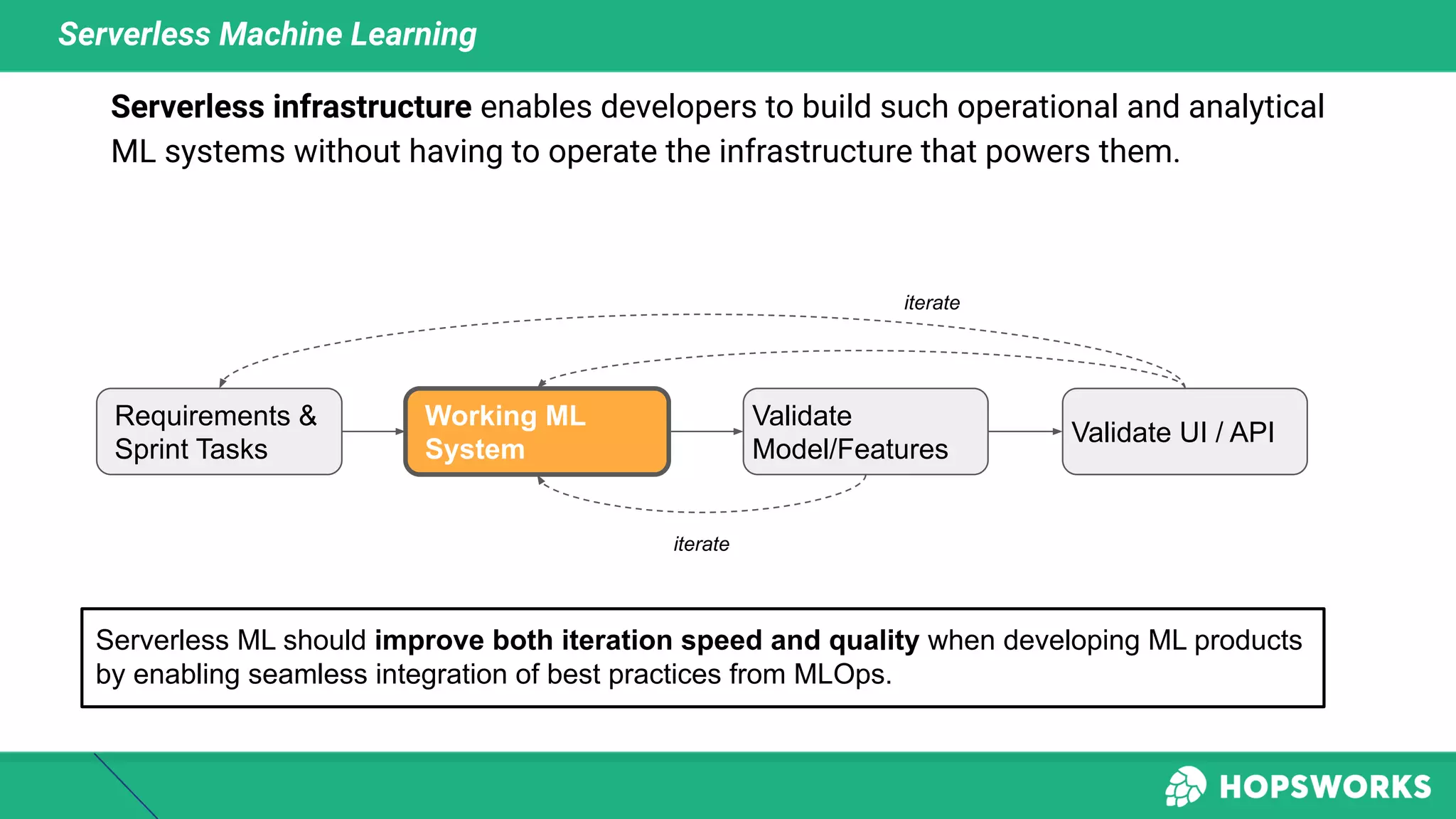
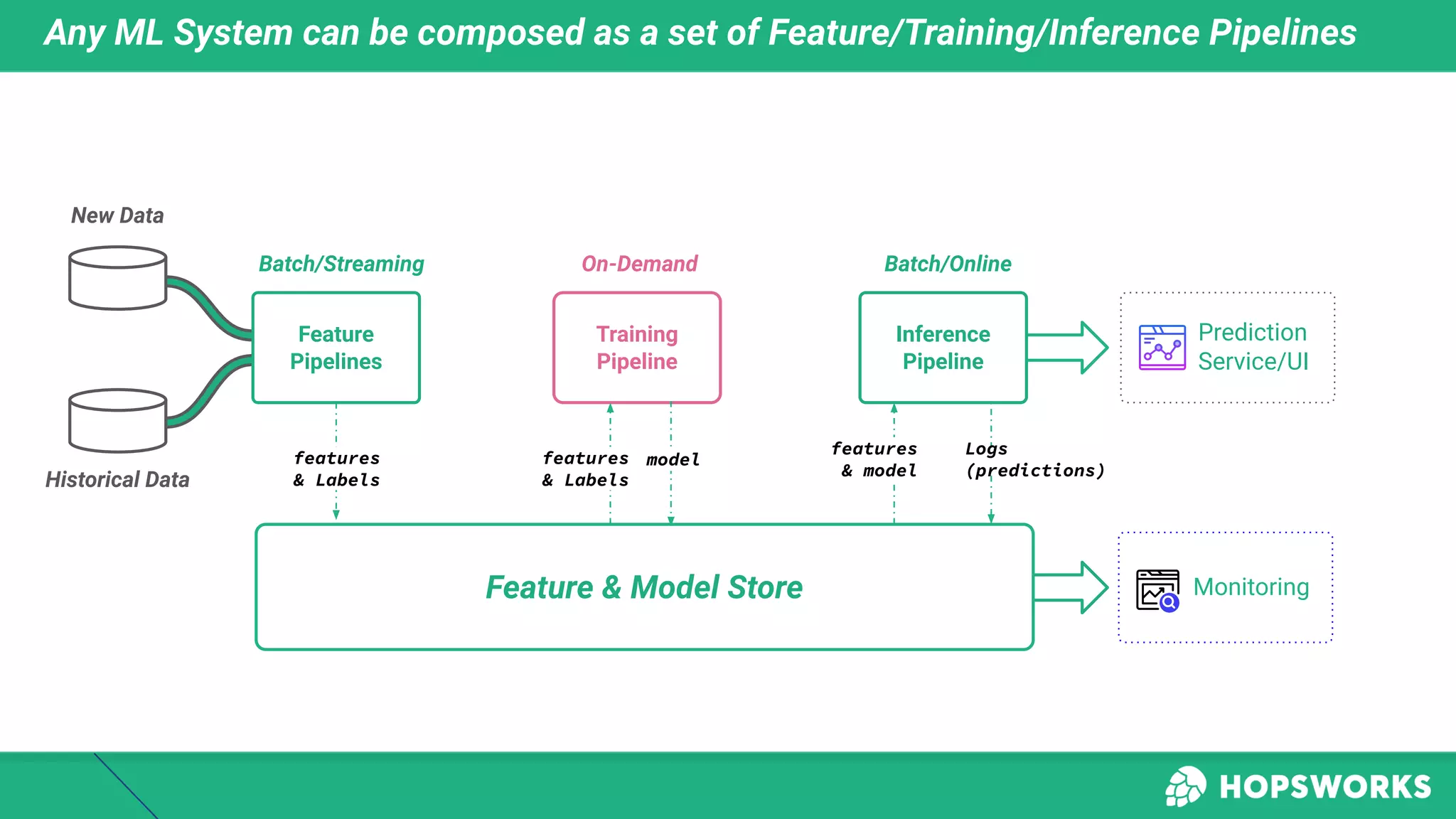
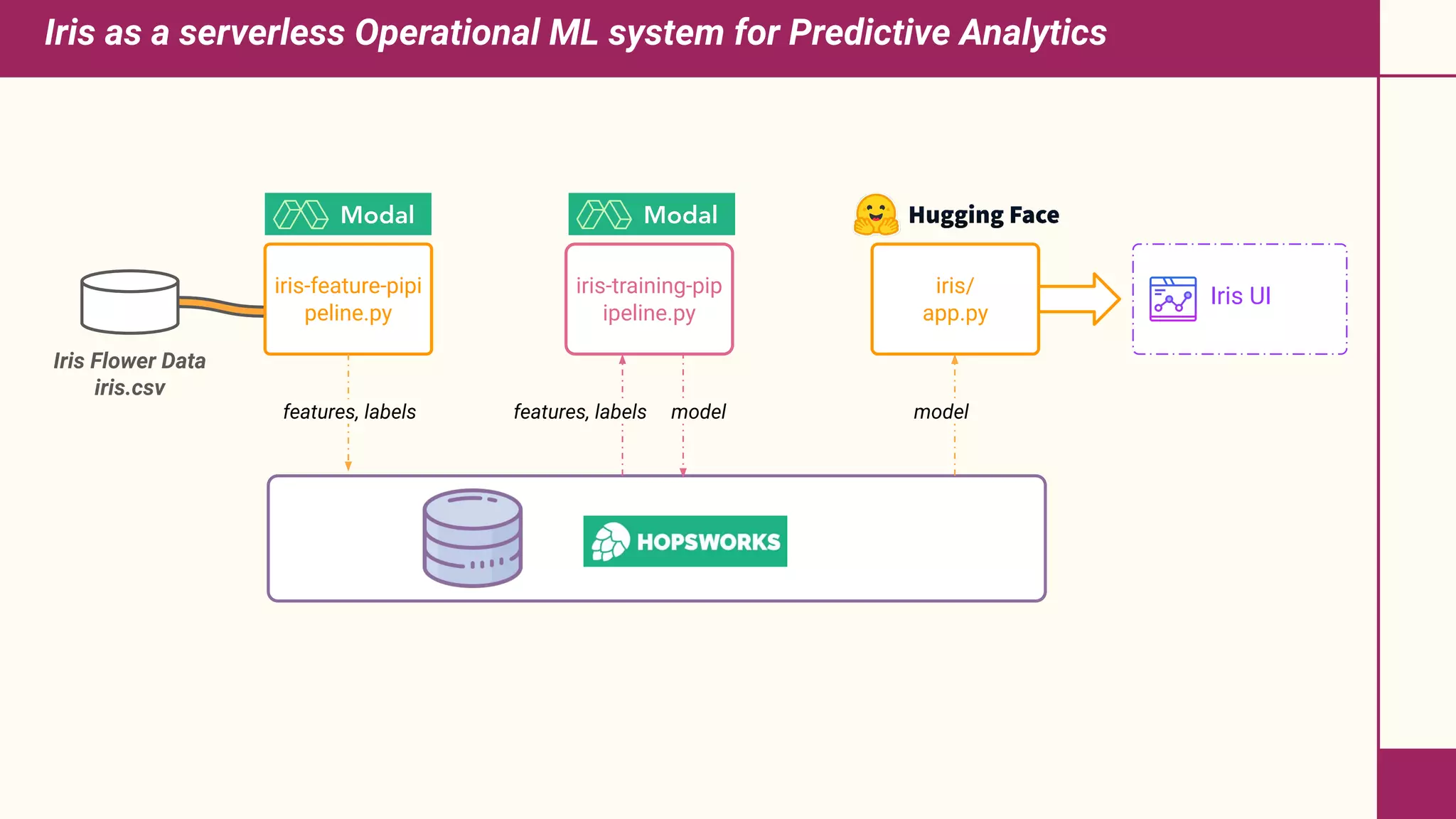
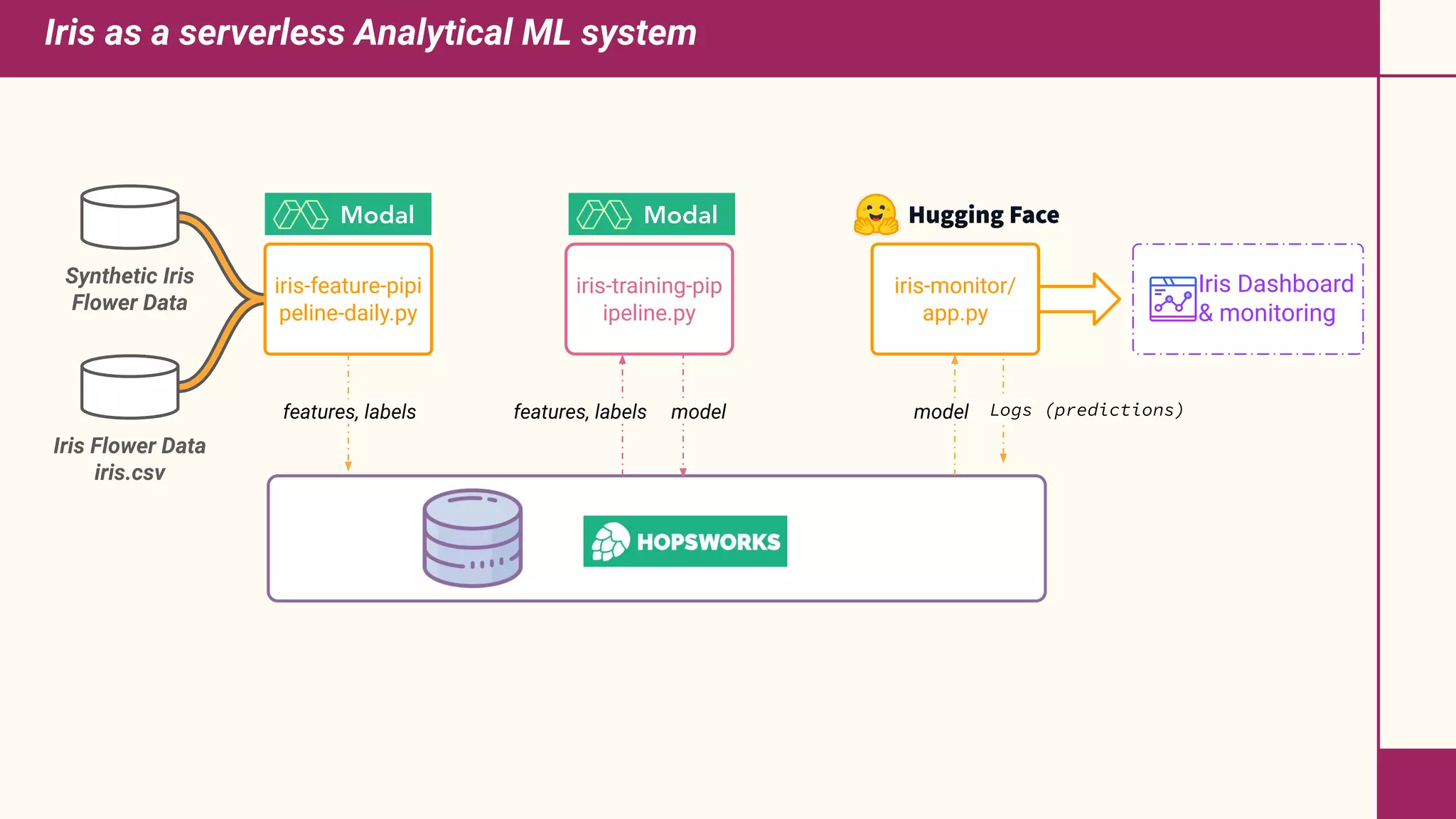
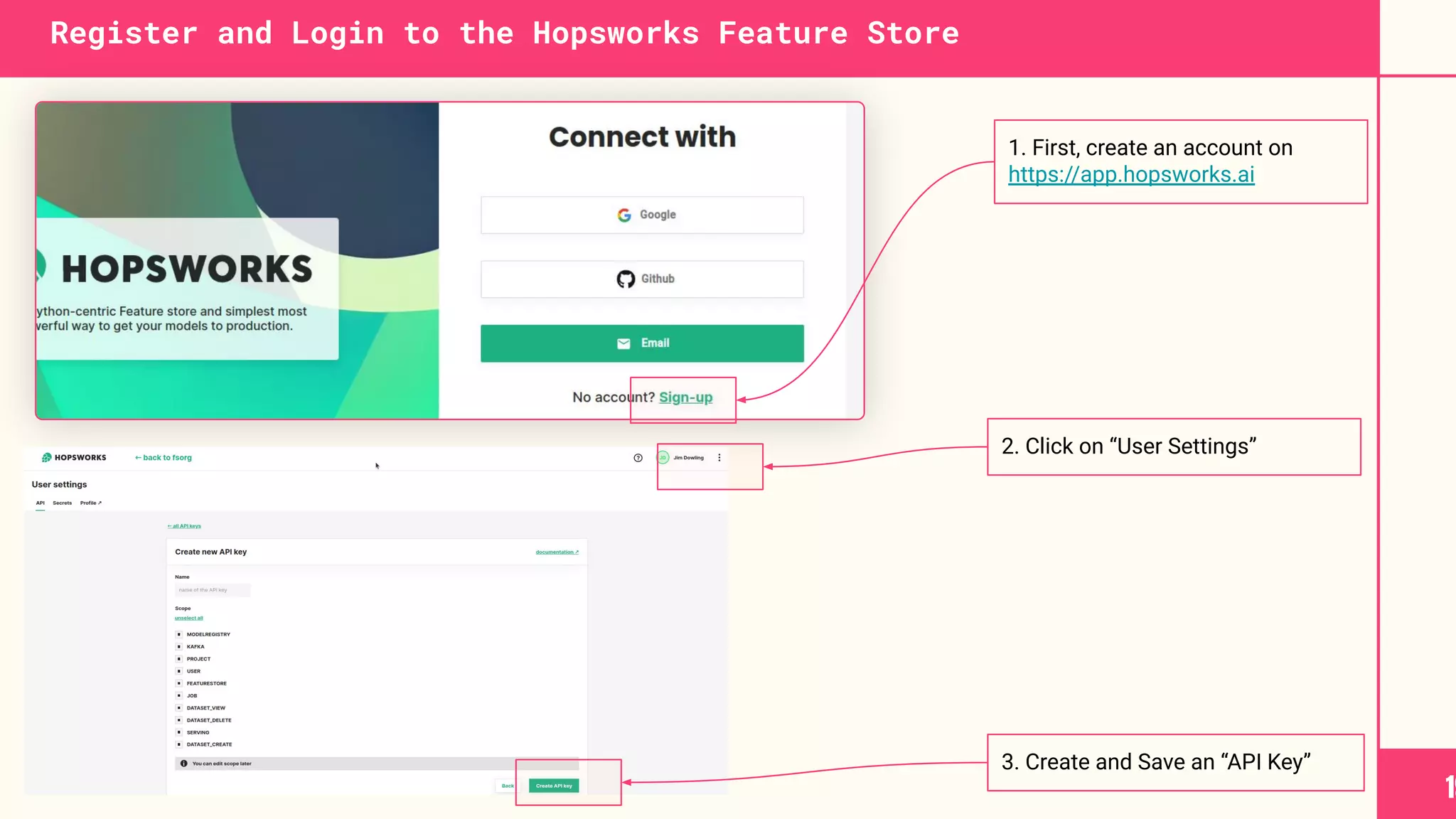
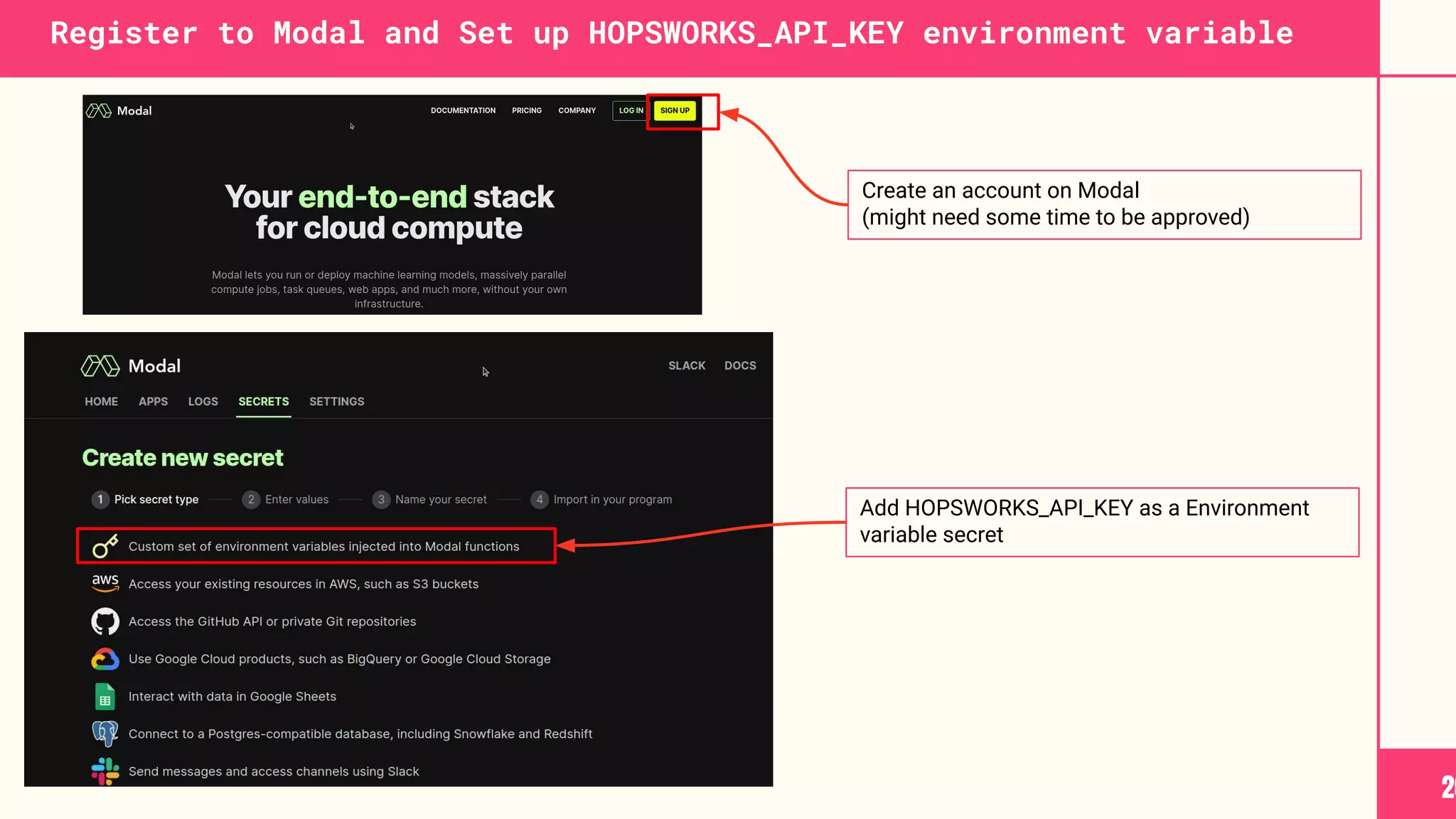
This document discusses building machine learning systems using serverless services and Python. It introduces the Iris flower classification dataset as a case study. The key steps outlined are to: create accounts on Hopsworks, Modal, and HuggingFace; build and run feature, training and inference pipelines on Modal to classify Iris flowers; and create a predictive user interface using Gradio on HuggingFace to allow users to input Iris flower properties and predict the variety. The document emphasizes that serverless infrastructure allows building operational and analytical ML systems without managing underlying infrastructure.




























![ARVC and flecainide case report[EI] Jim.docx.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/finalarvcandflecainidecasereporteijim-230918192356-cebc27e5-thumbnail.jpg?width=640&height=640&fit=bounds)






































