Download as PDF, PPTX






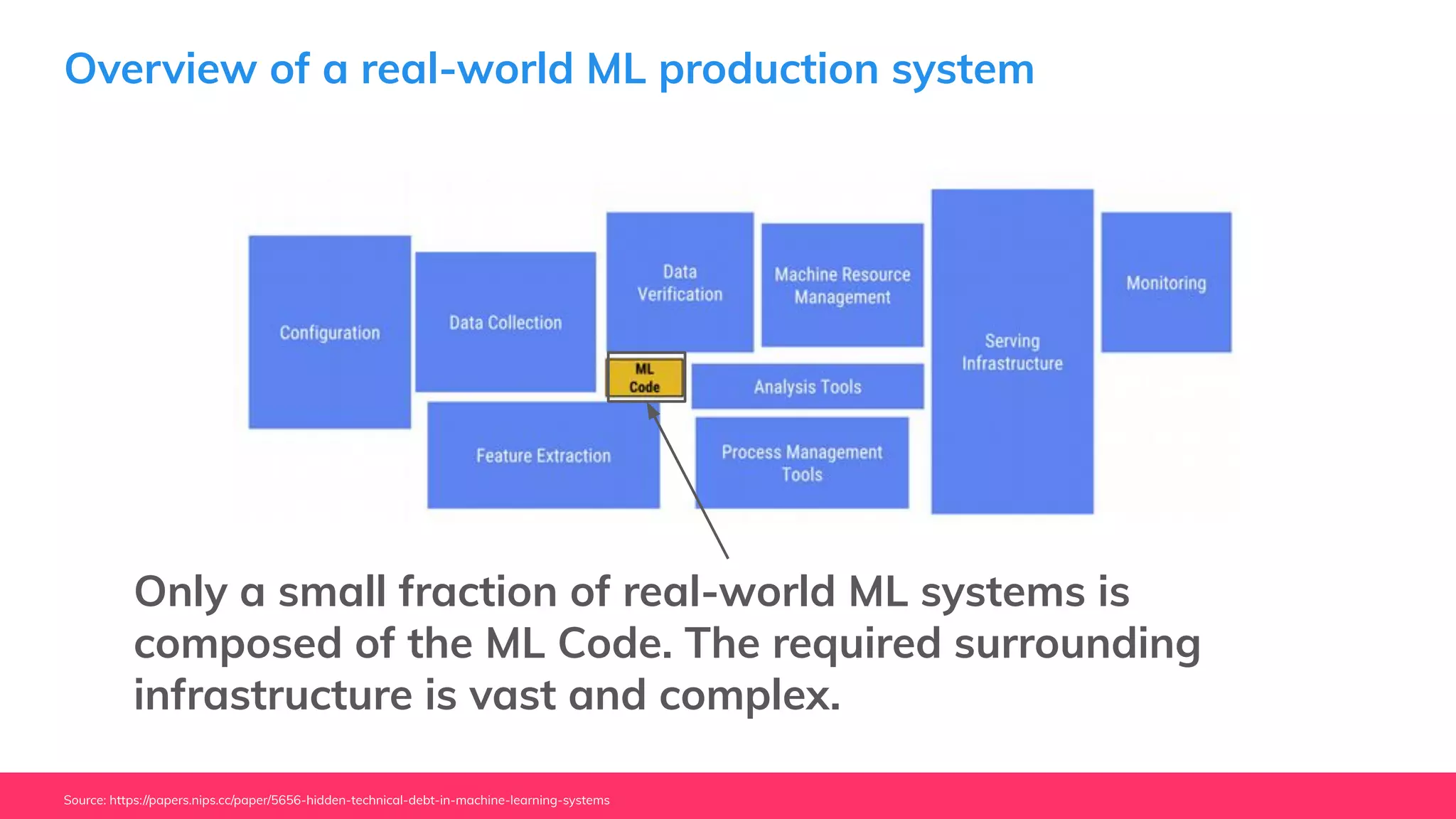
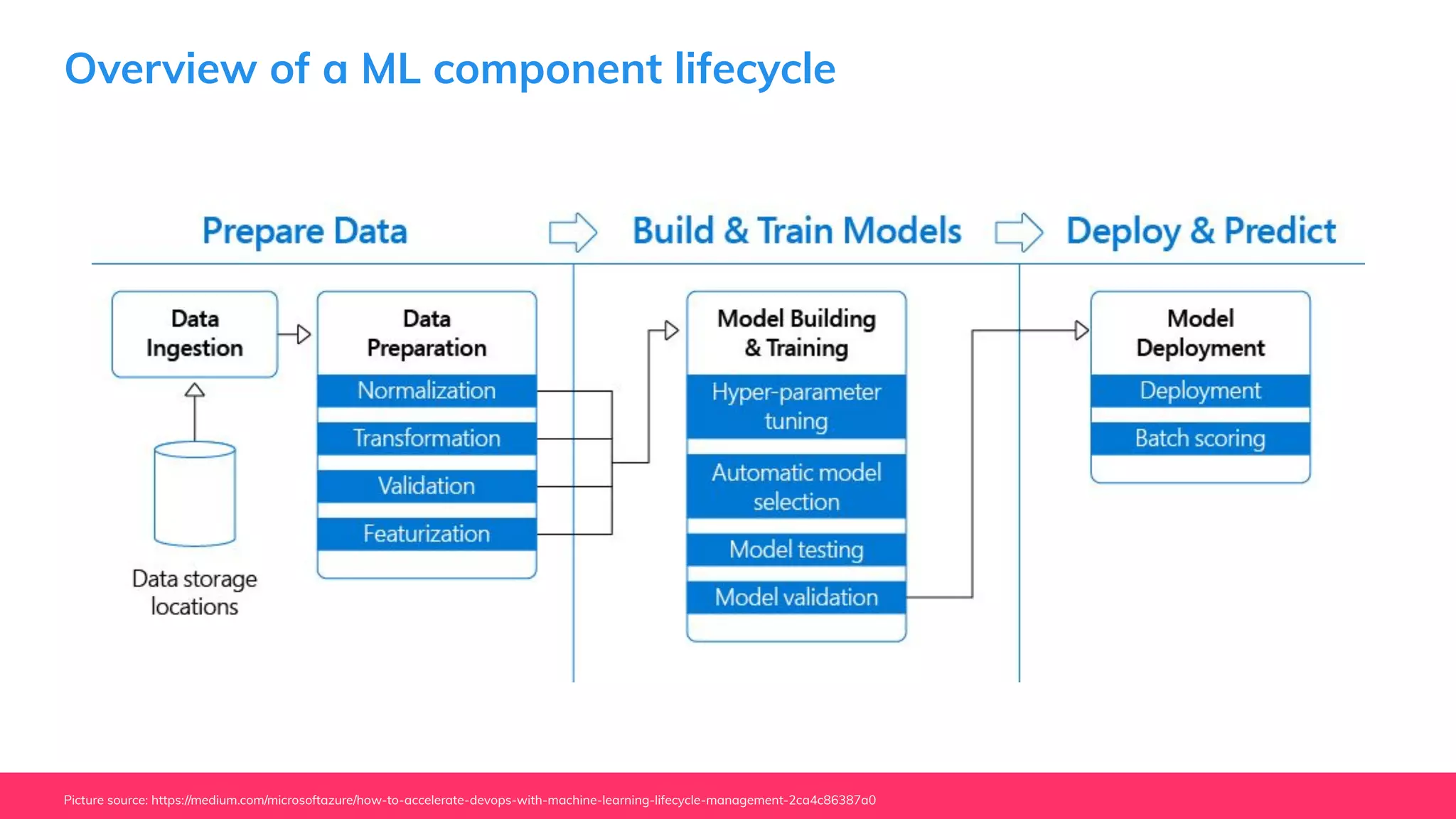
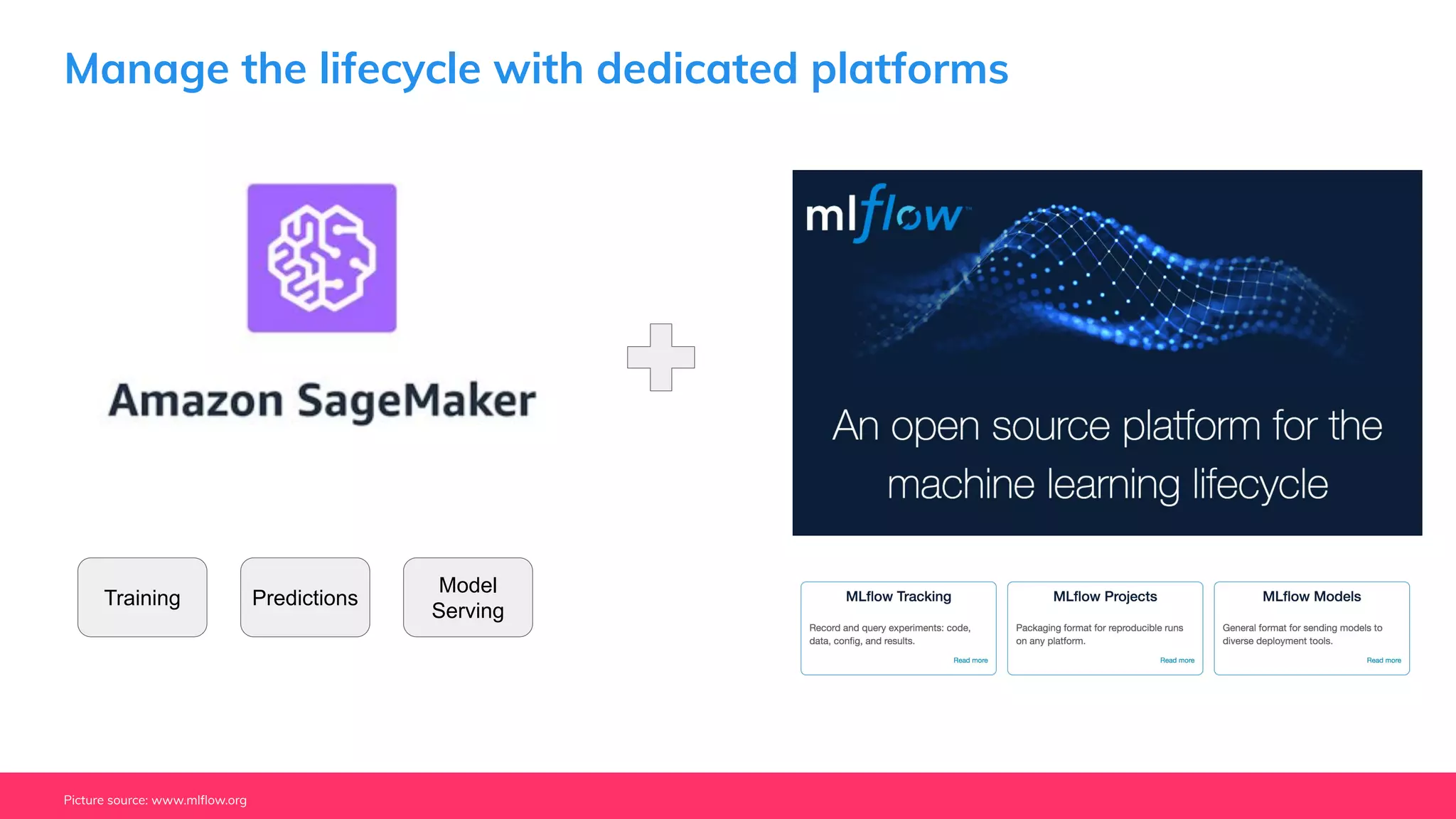

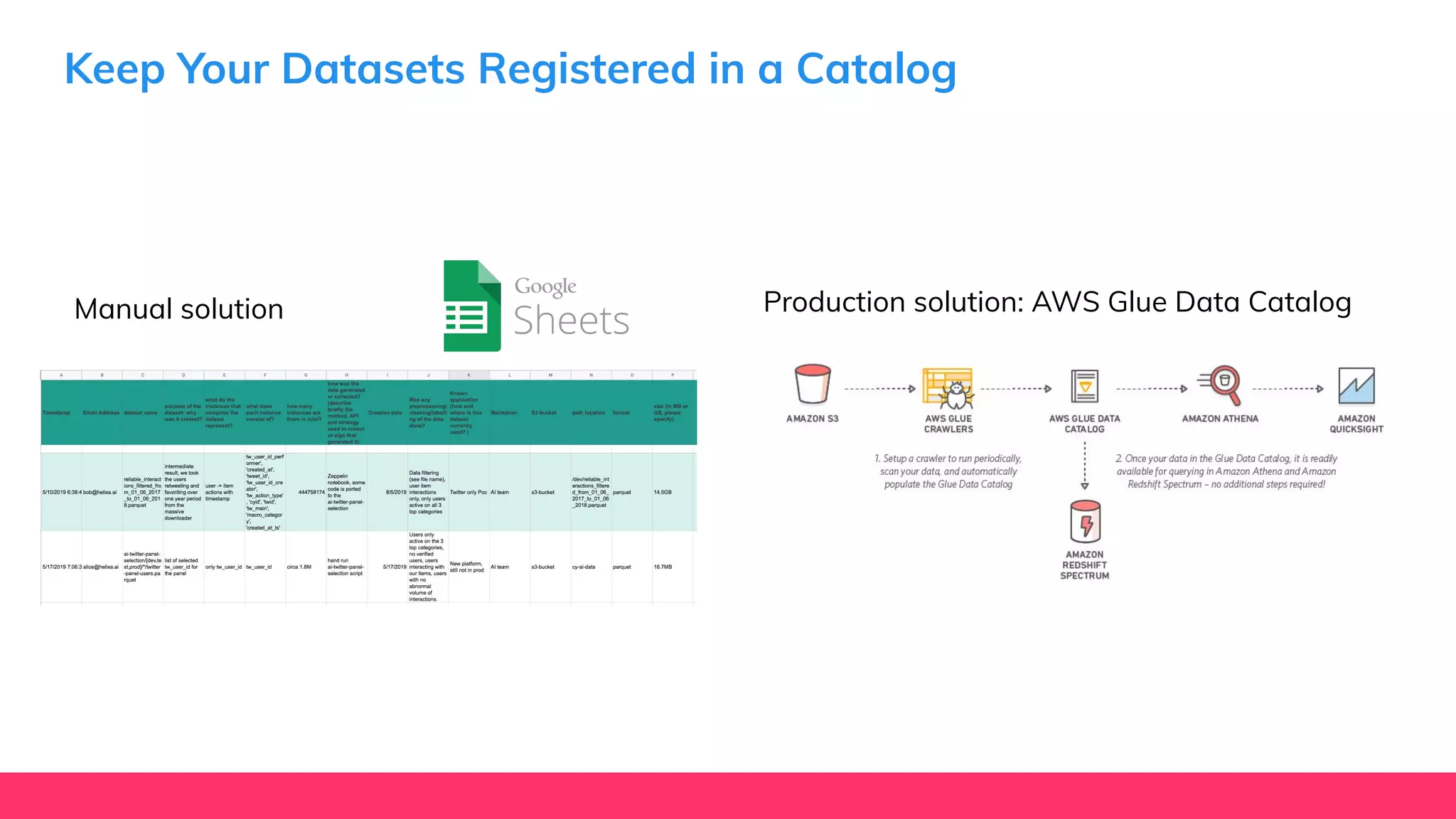
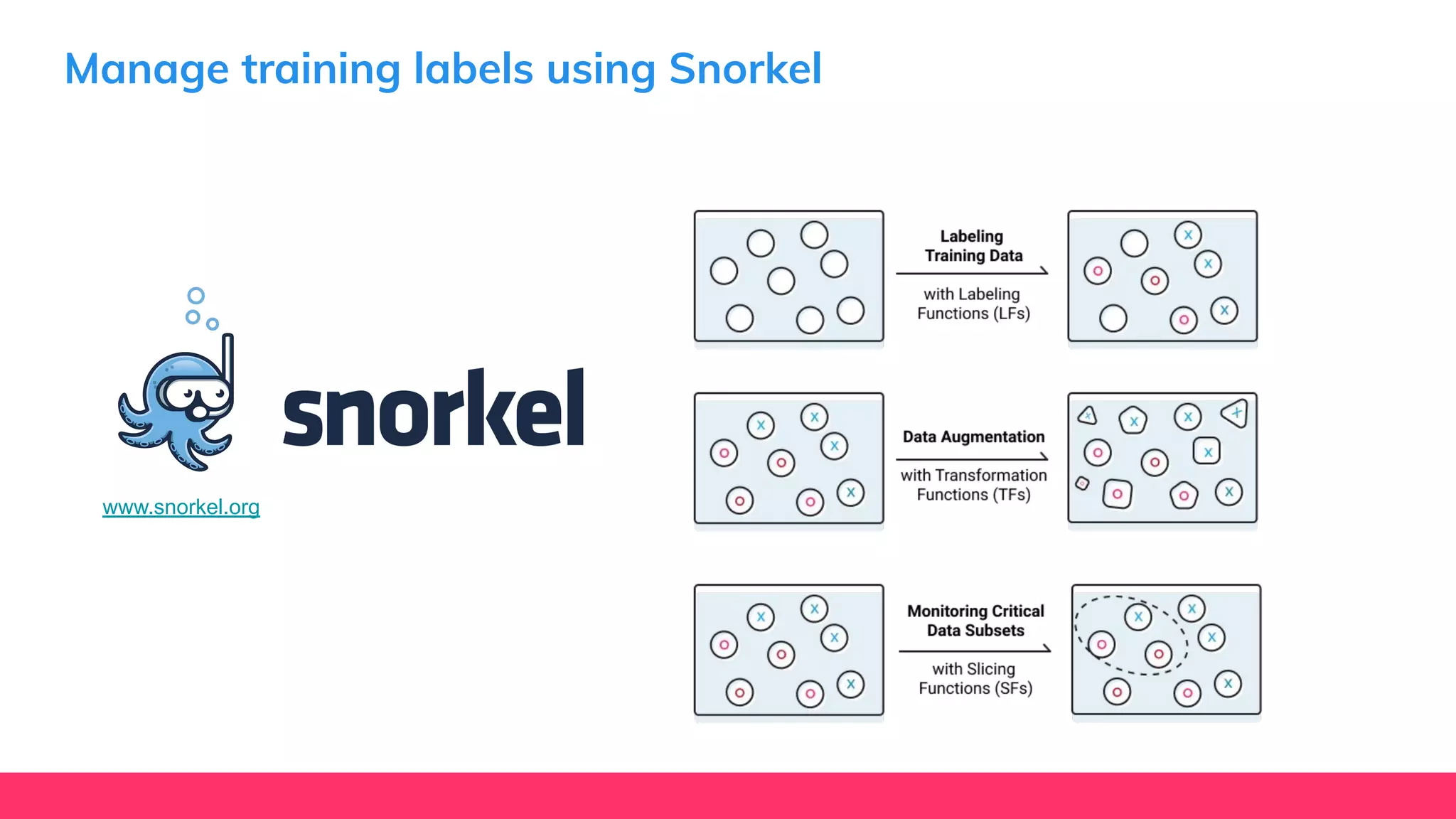
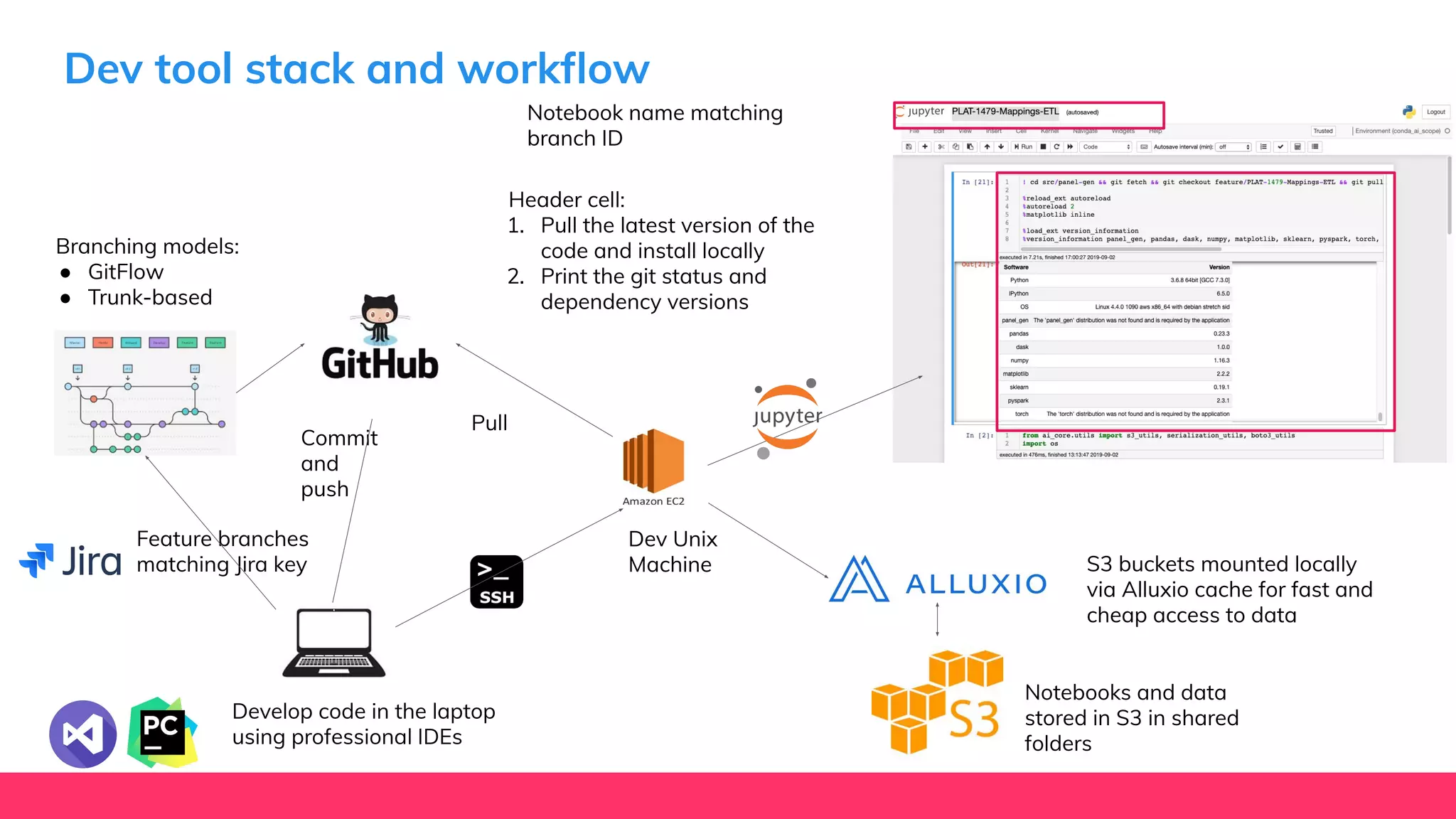




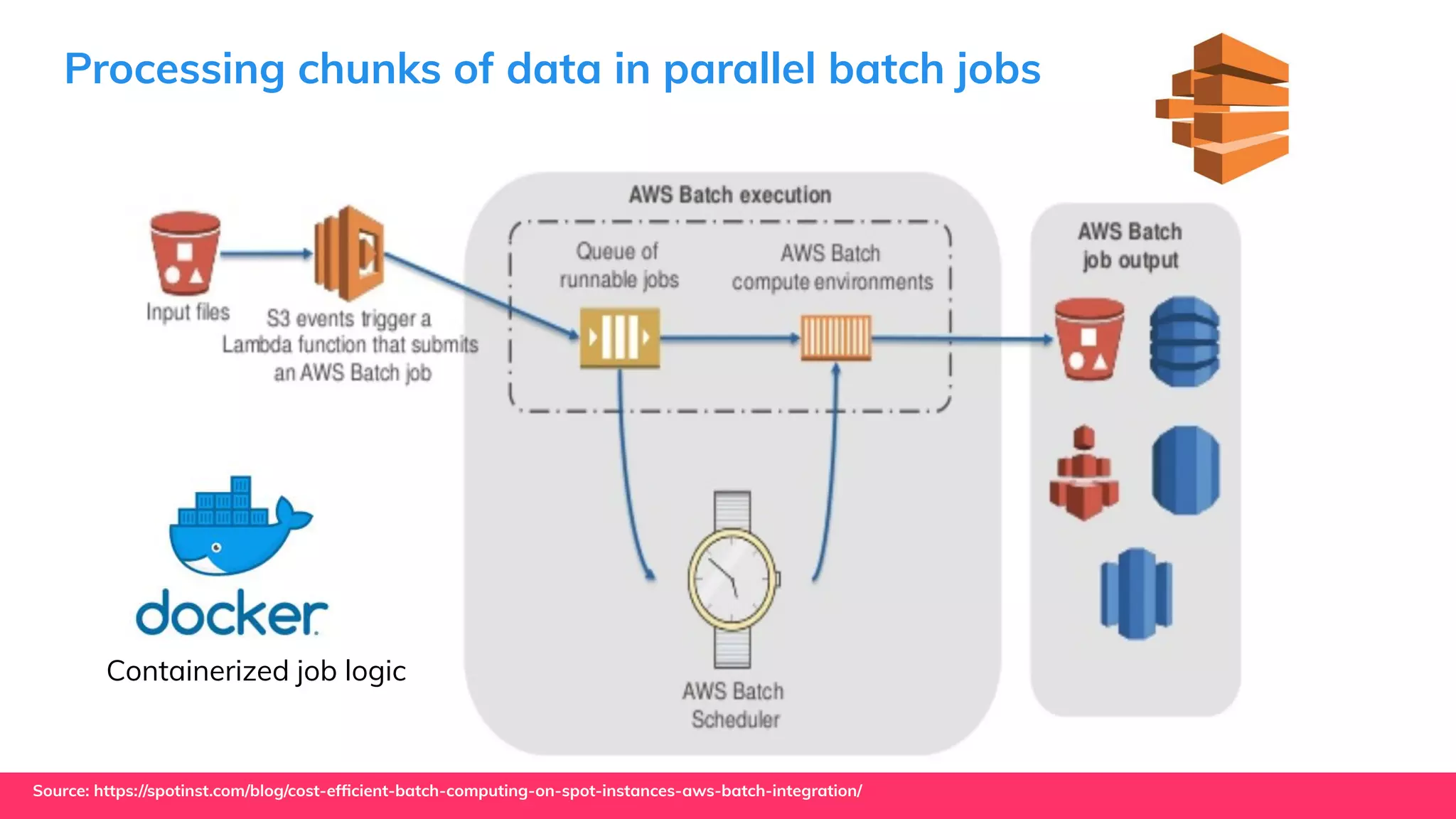
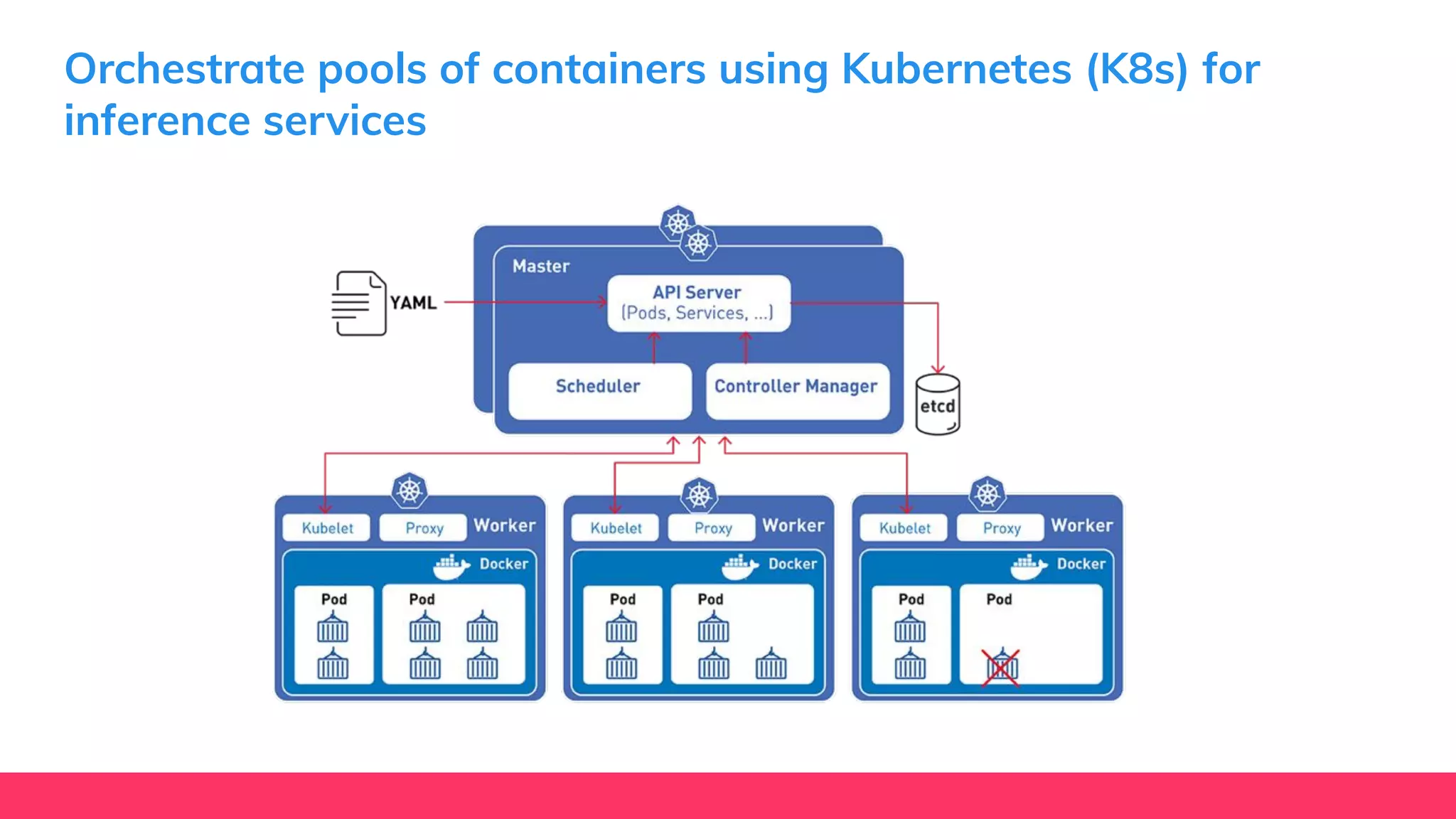

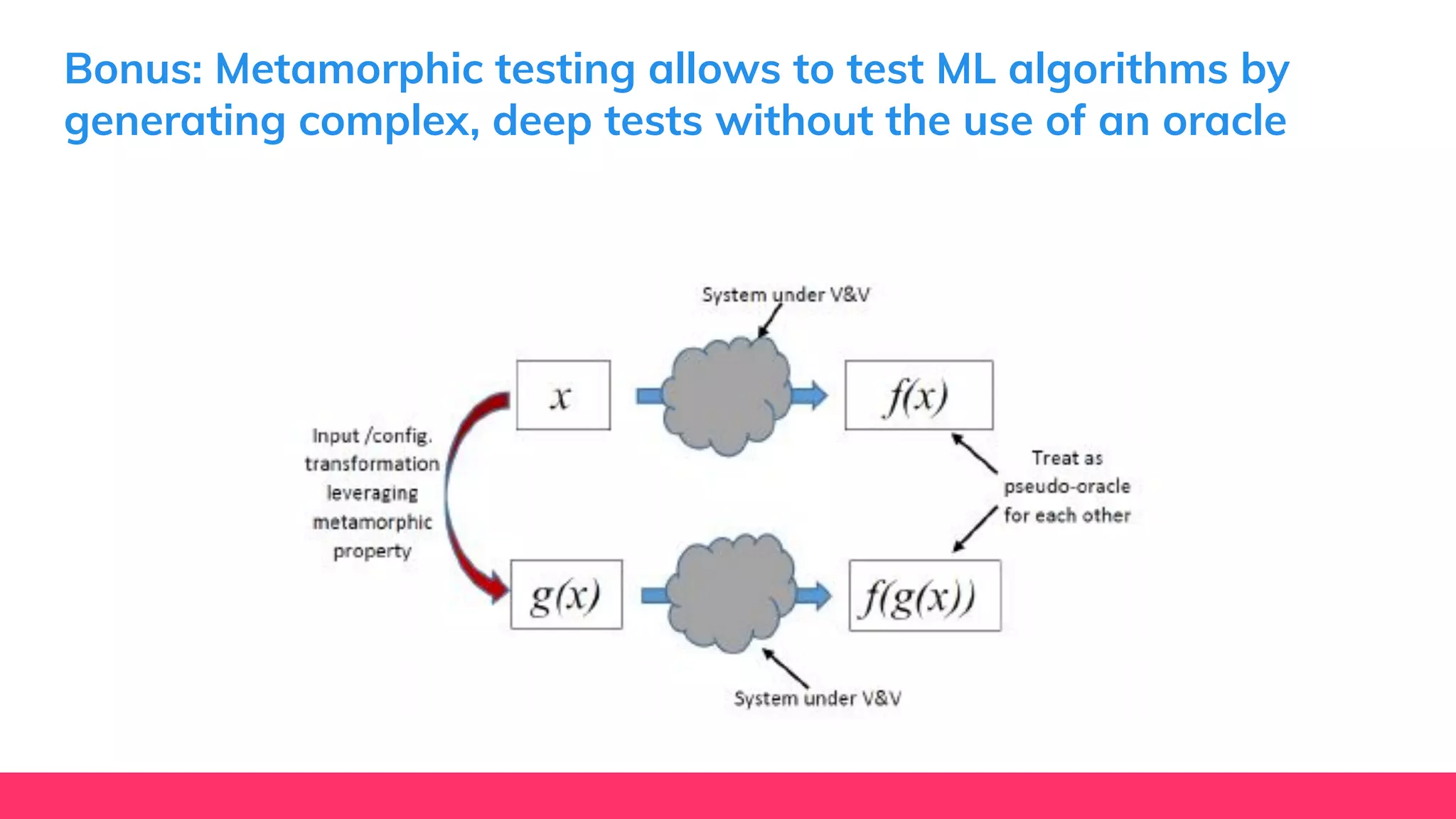

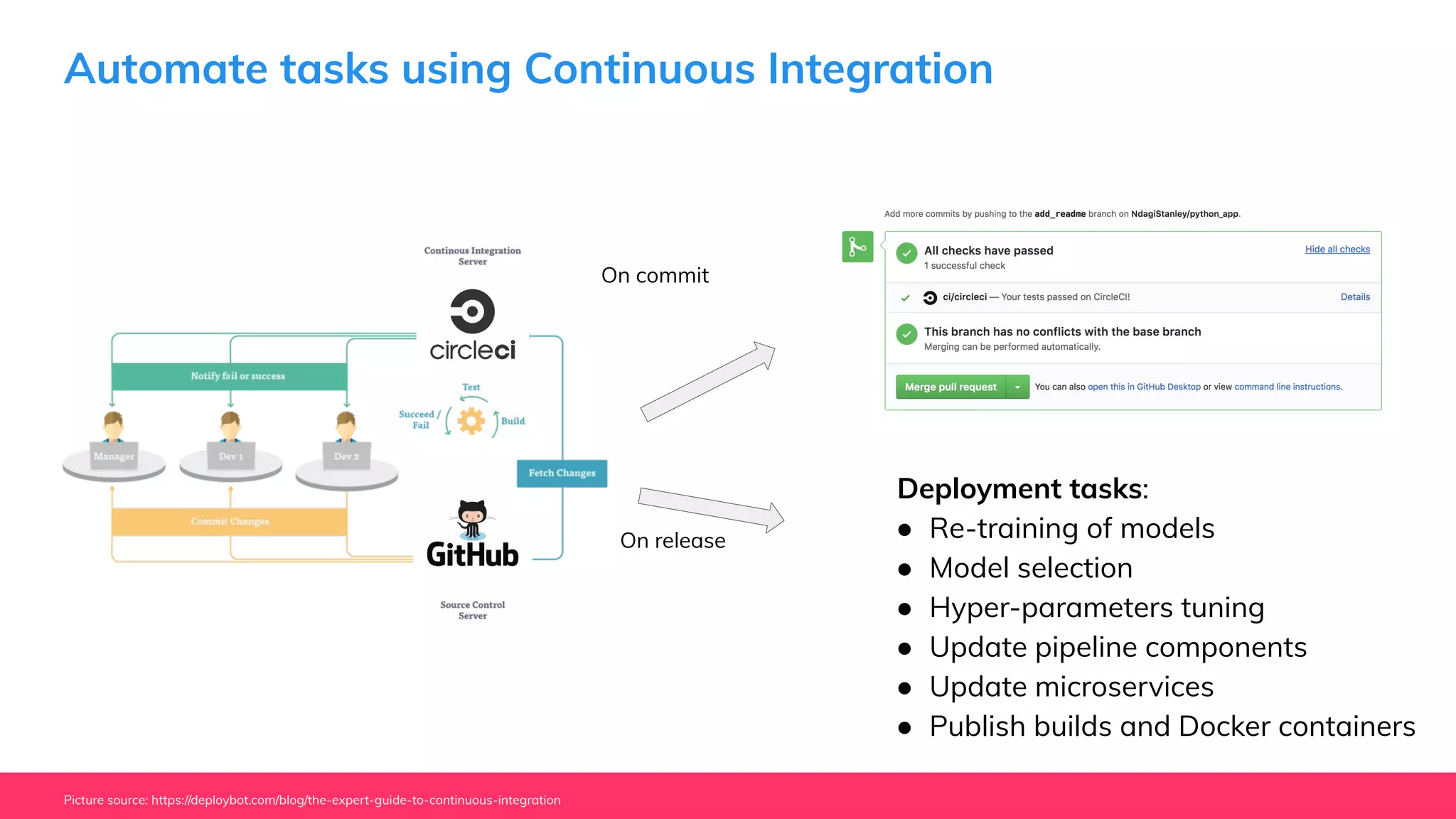
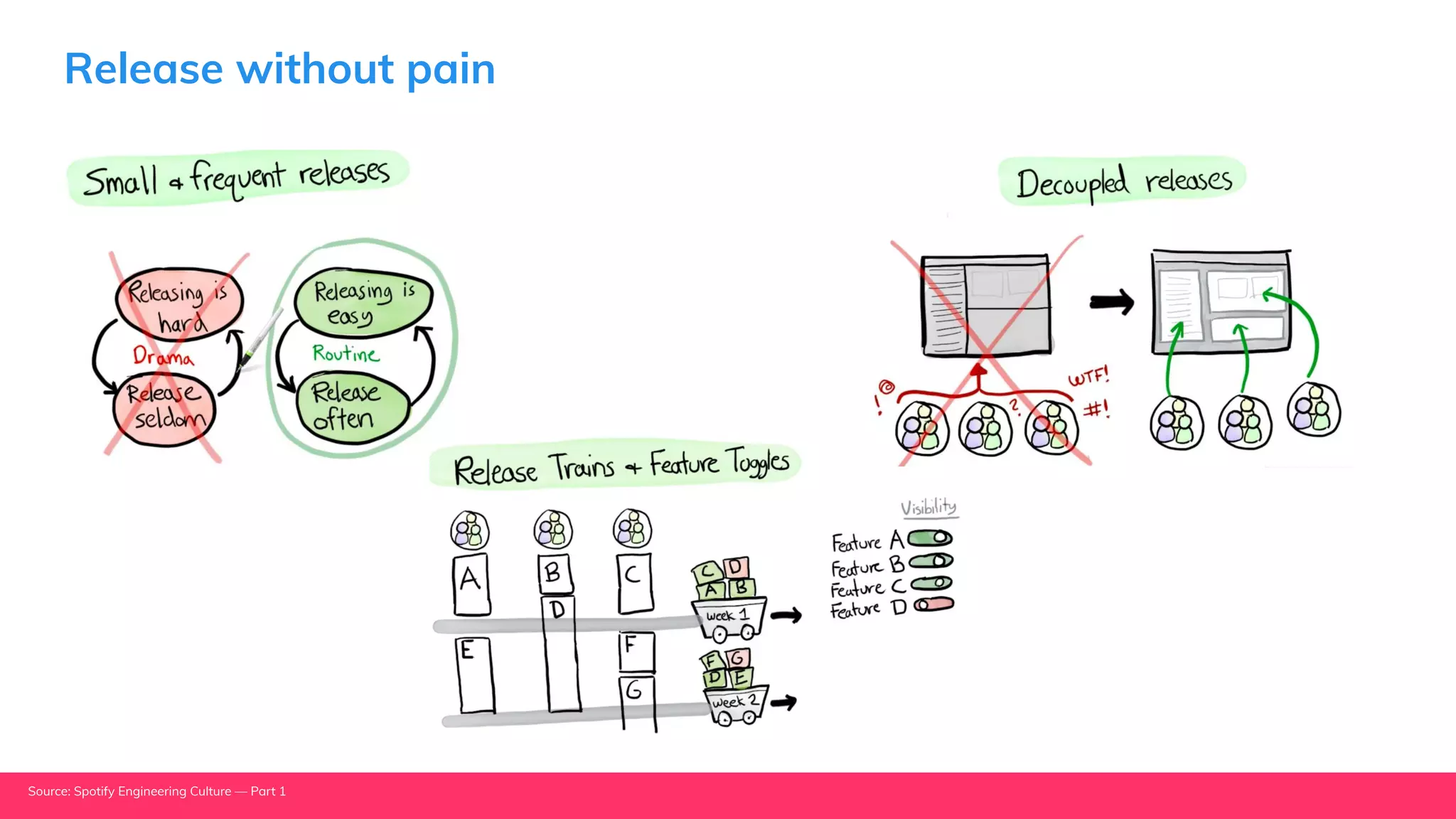
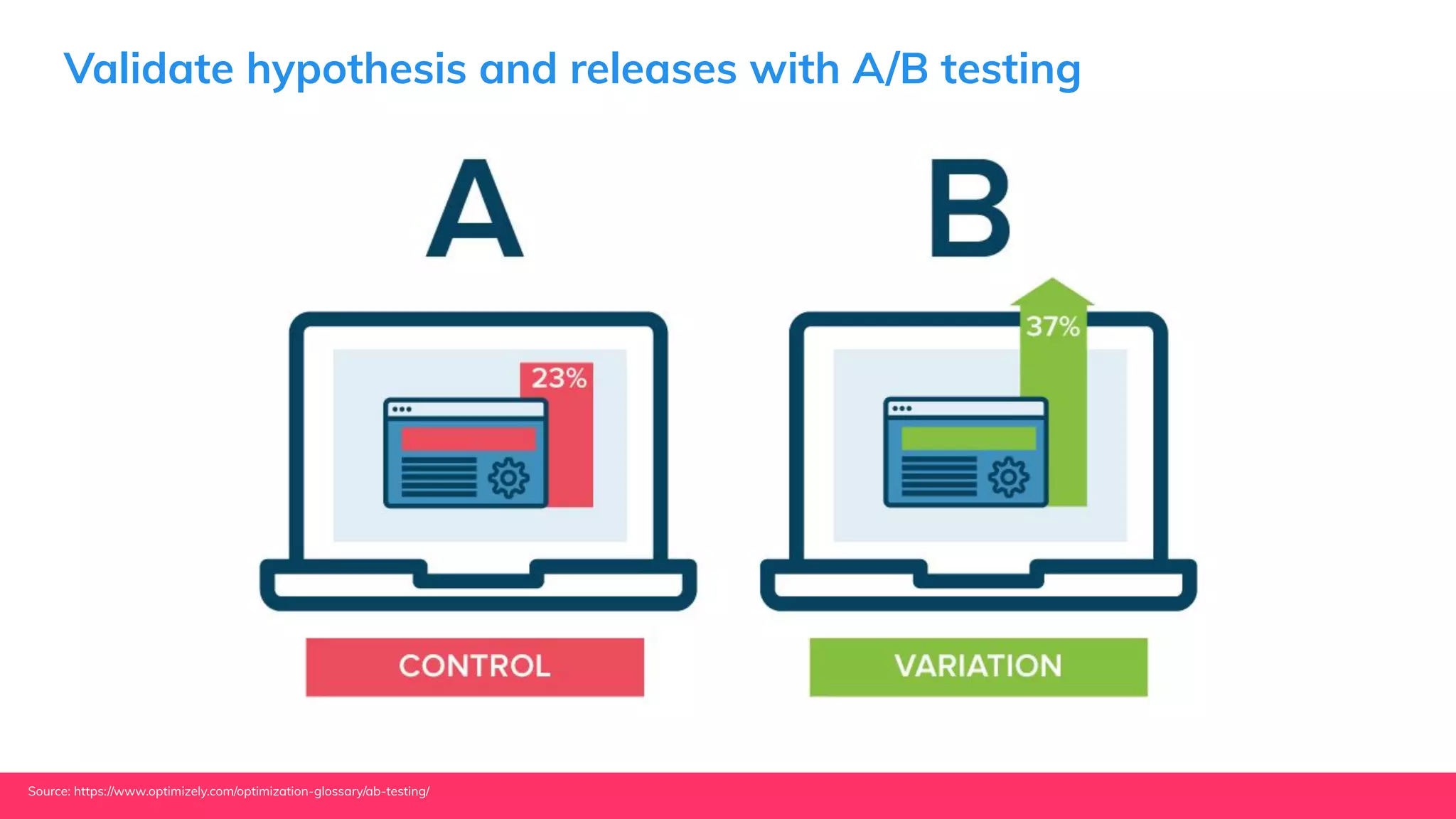
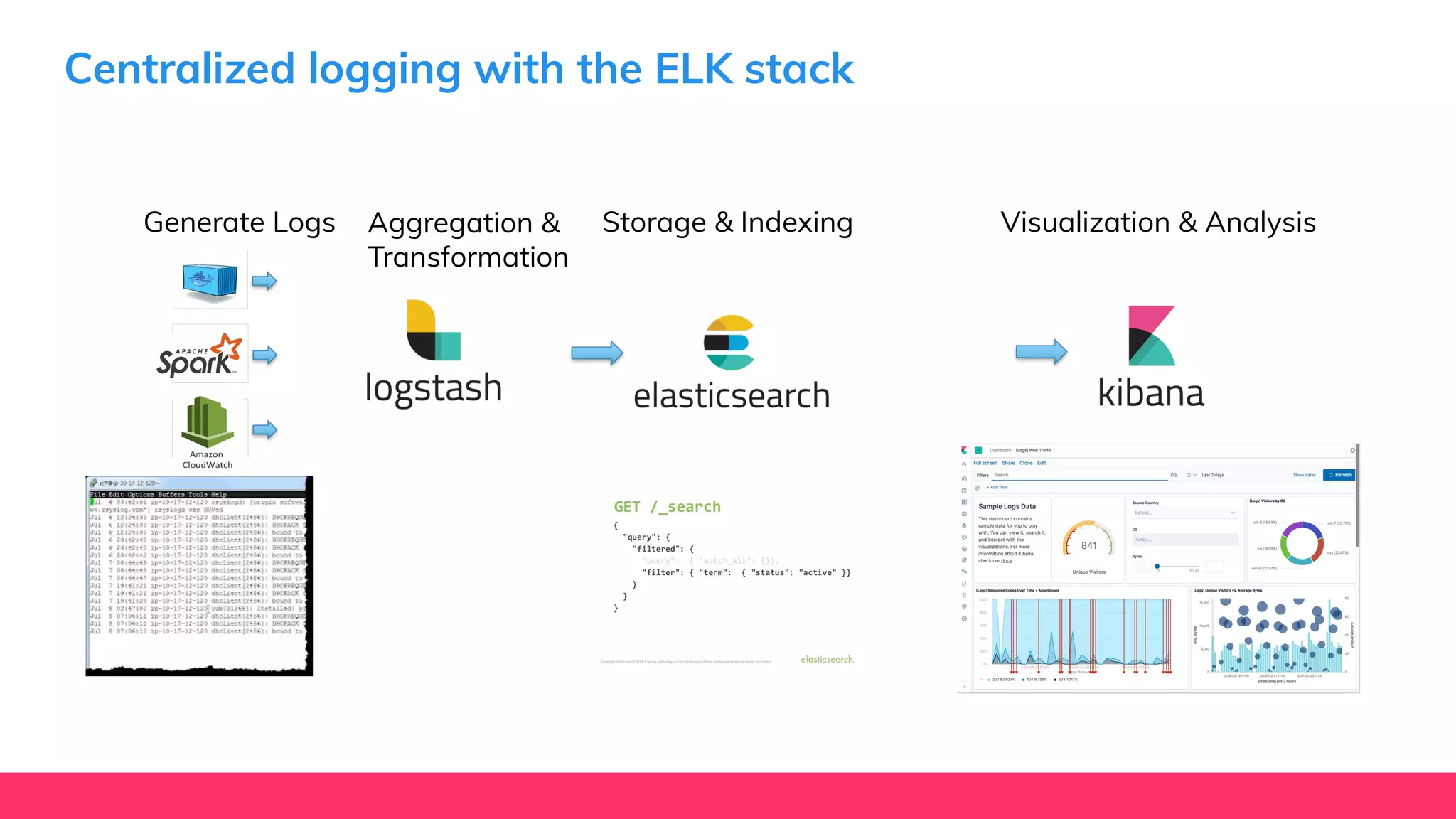







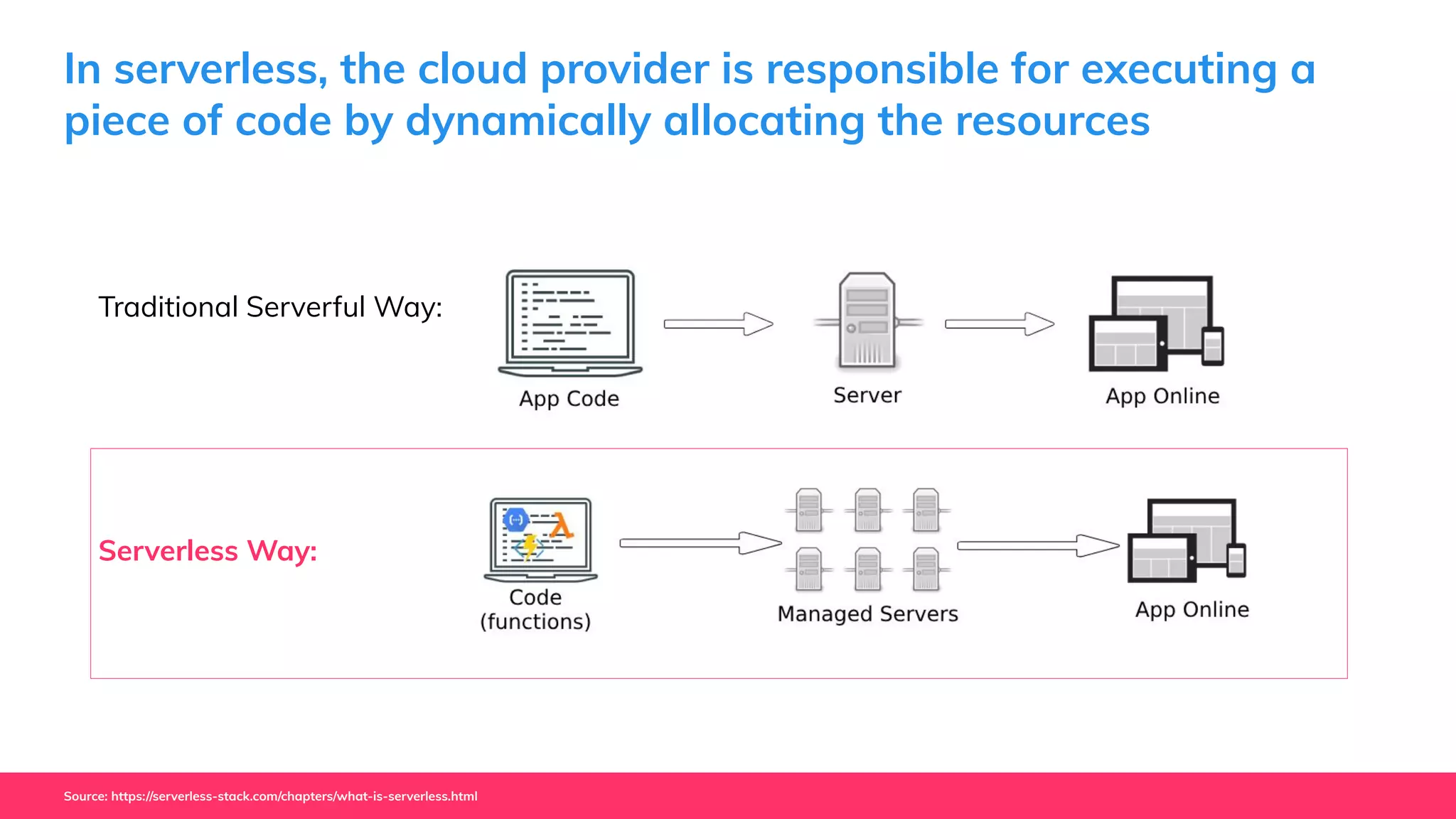


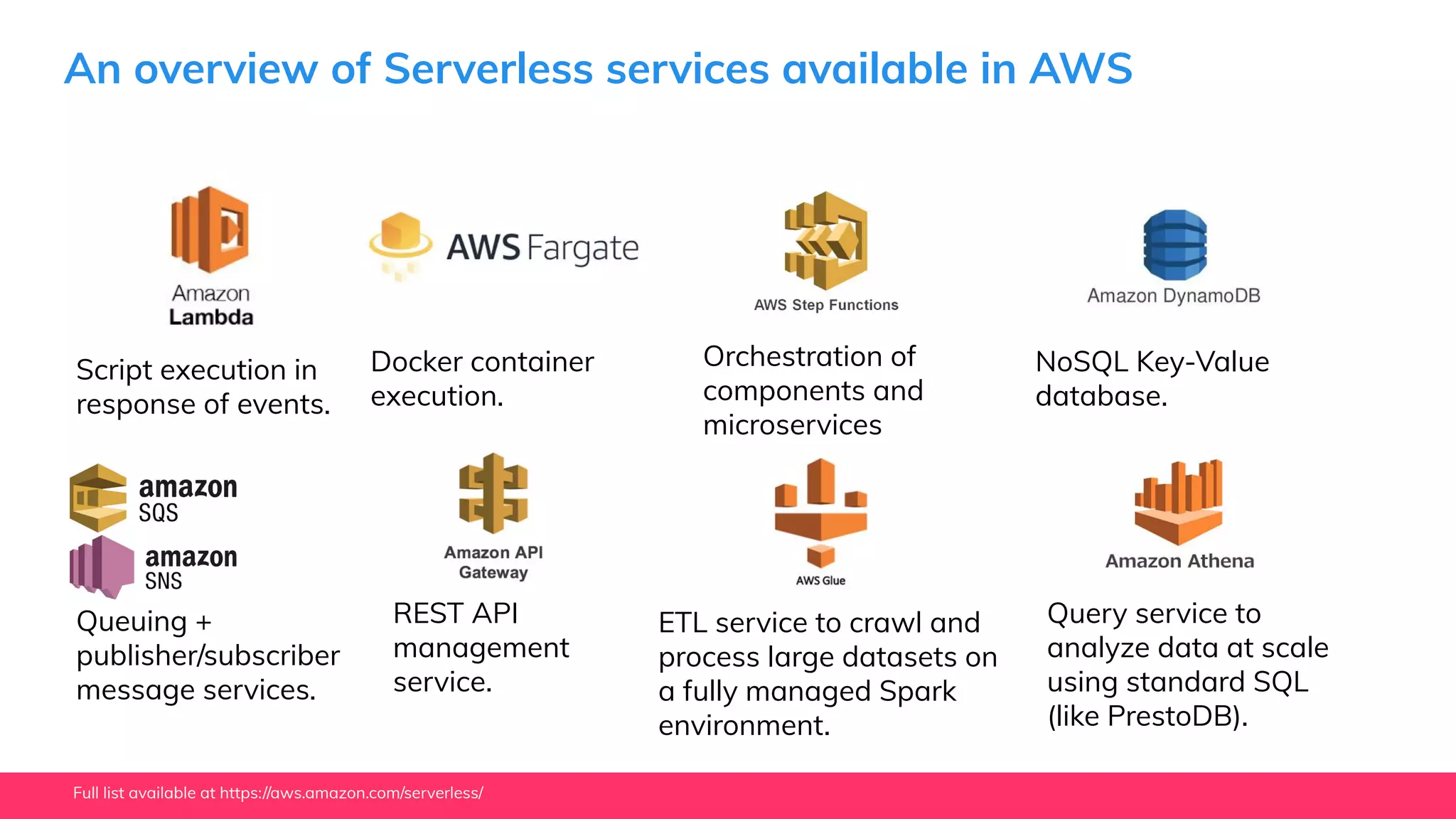
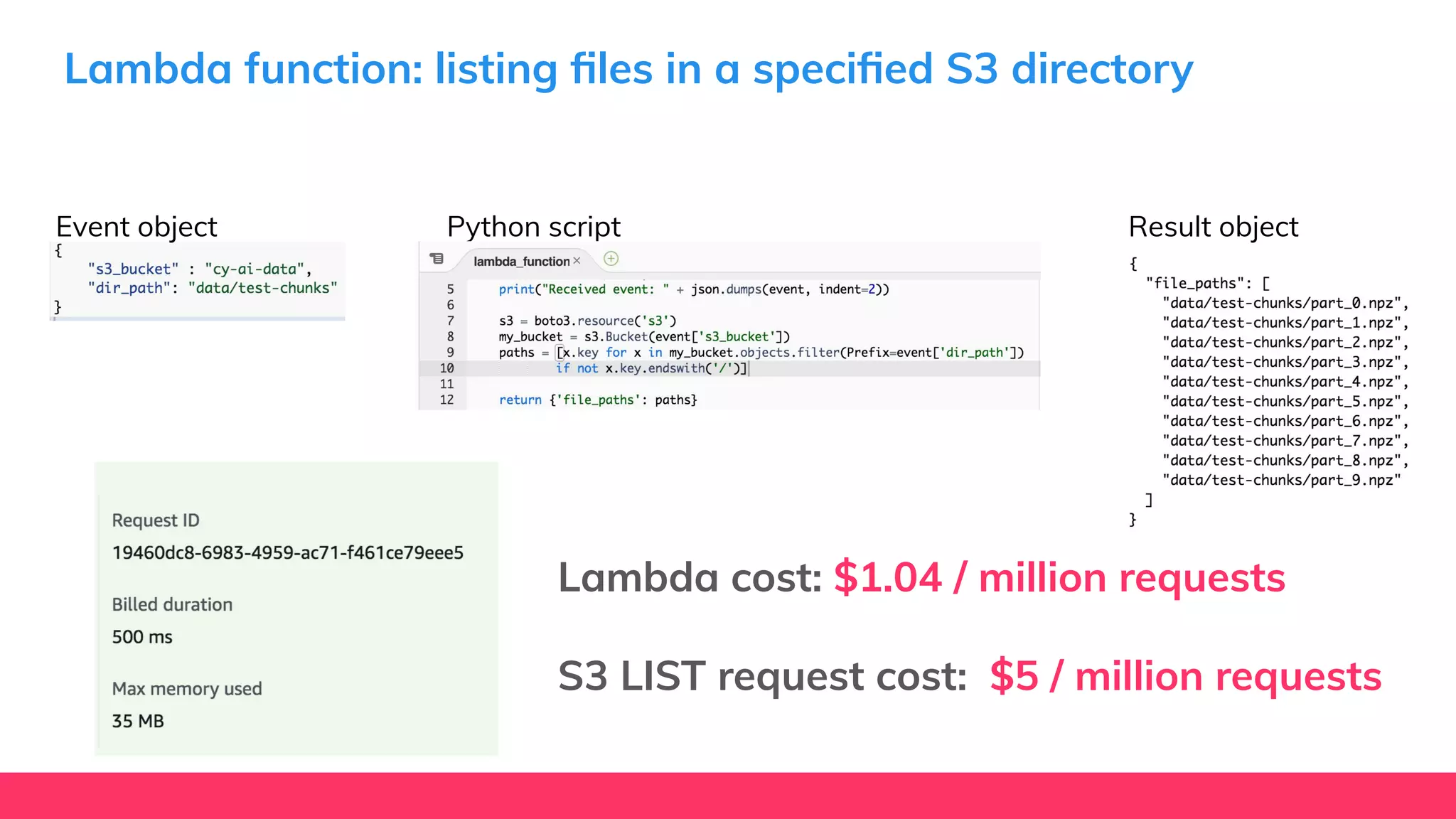

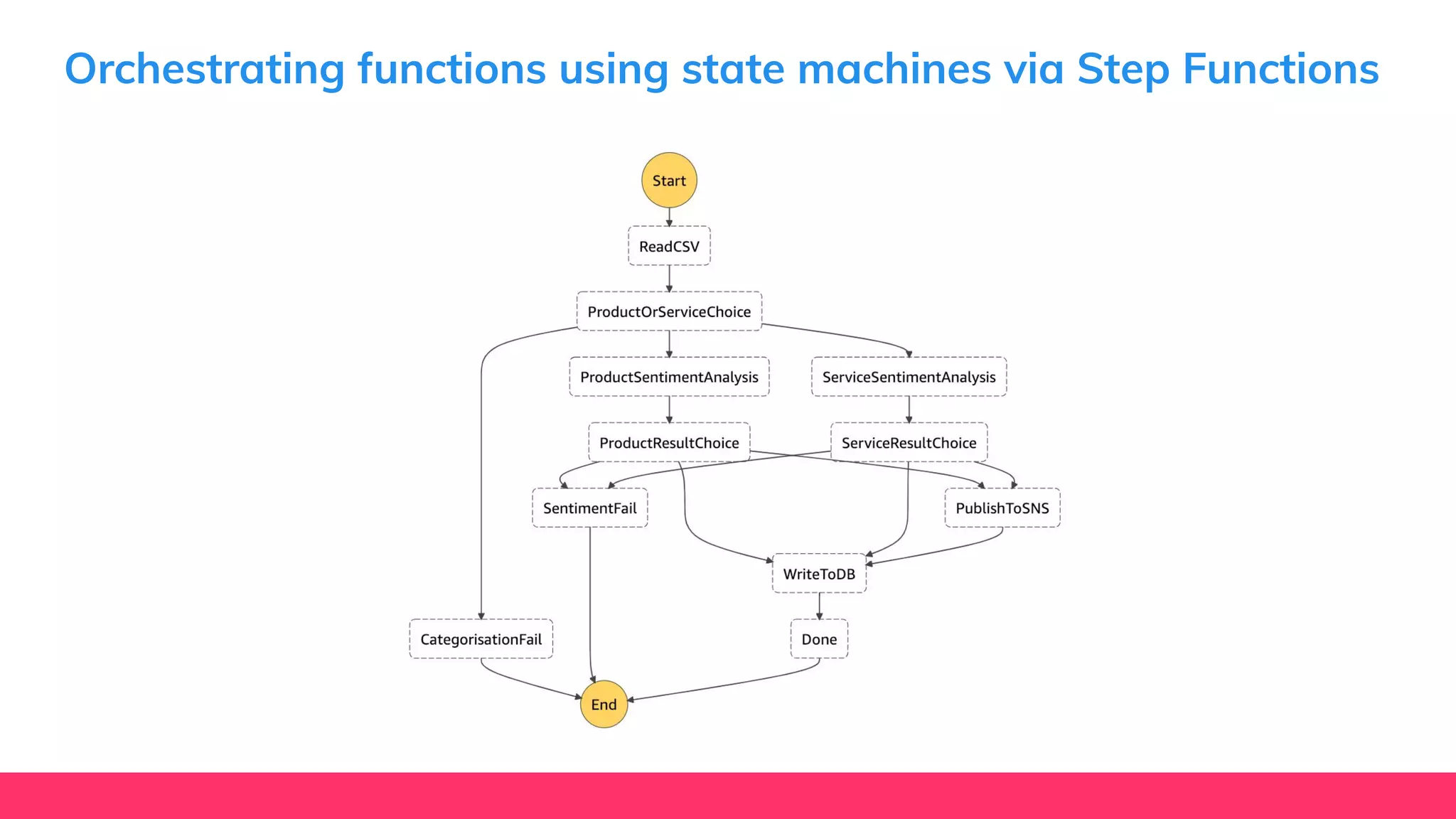
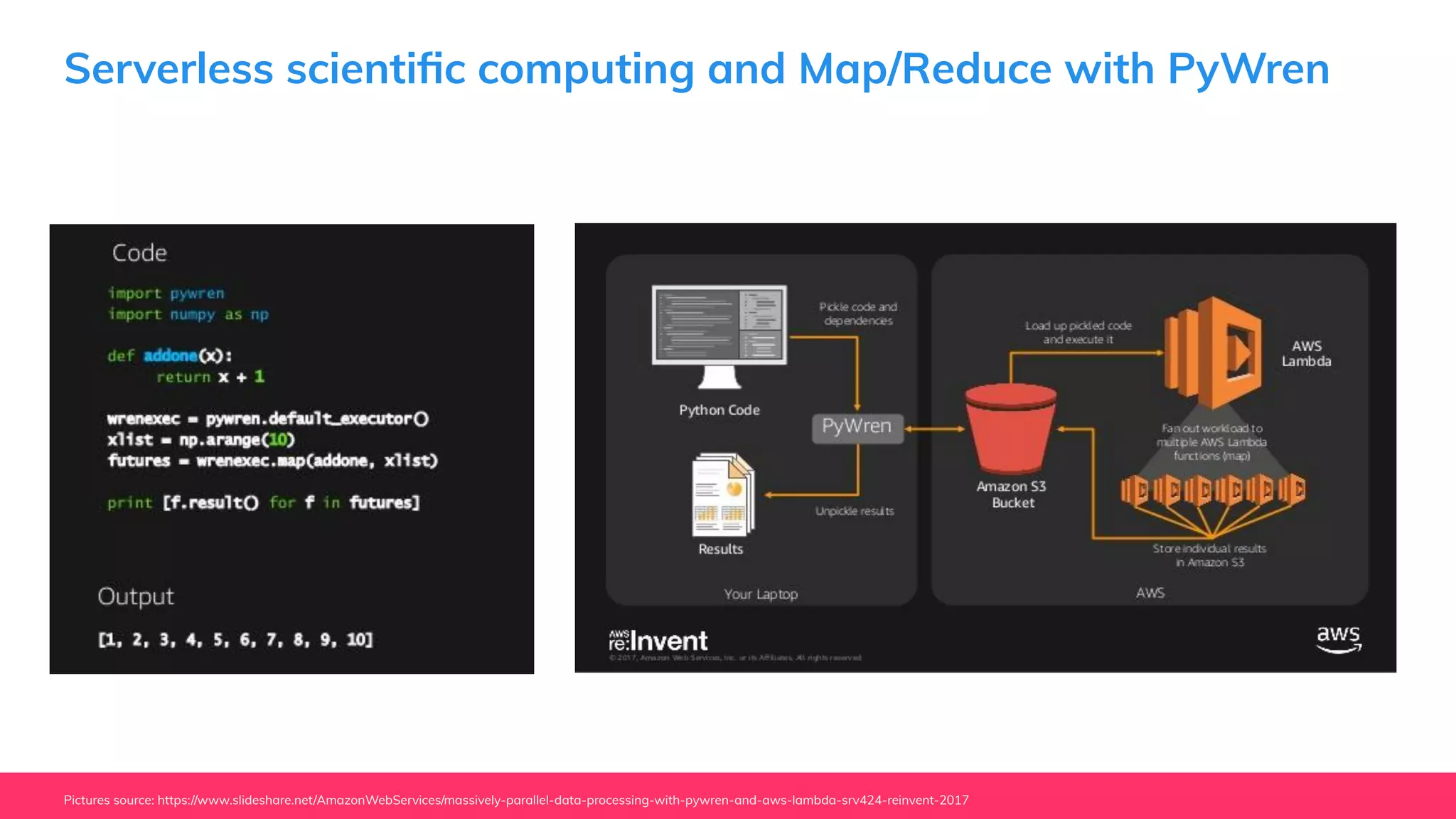


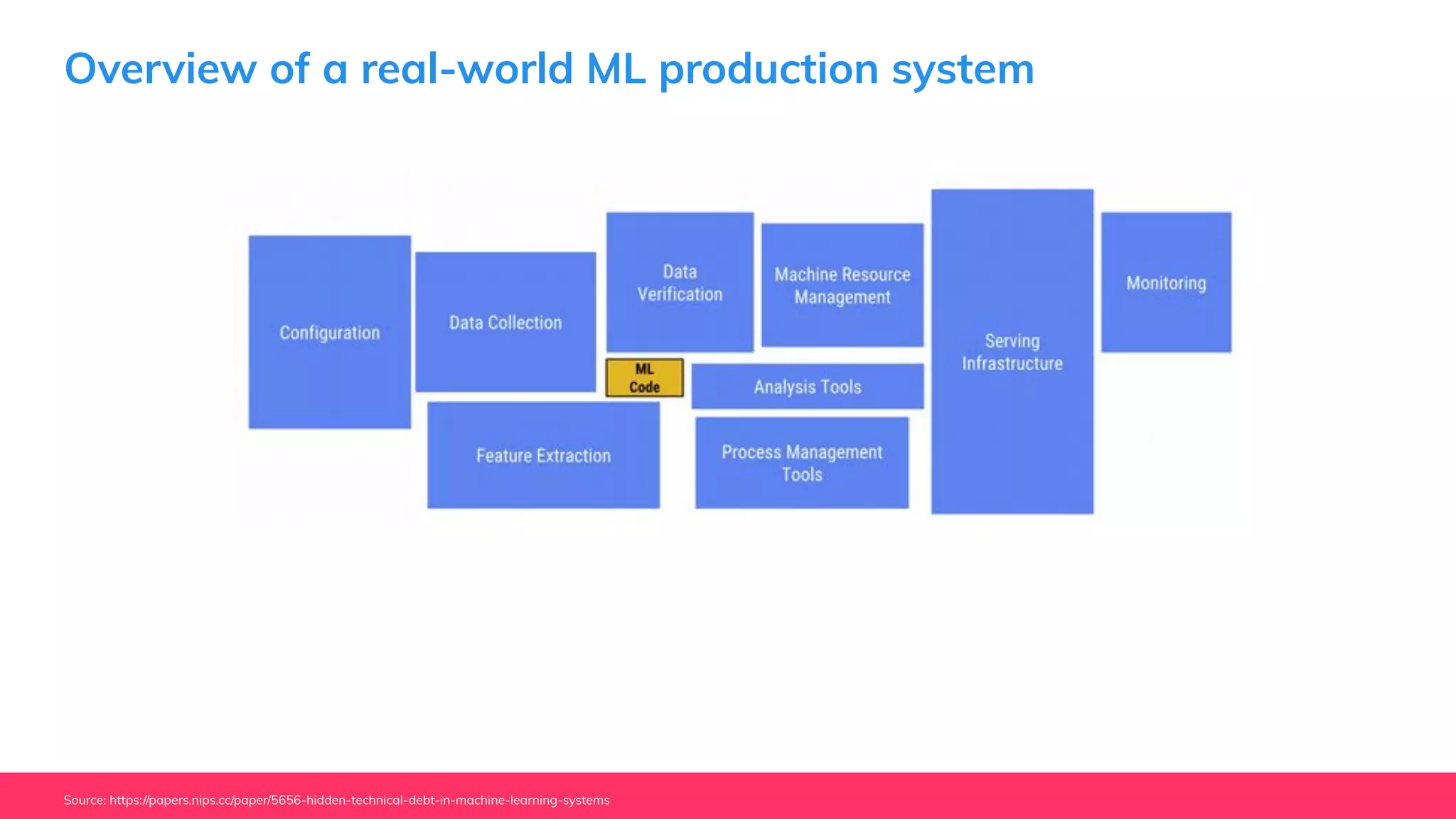
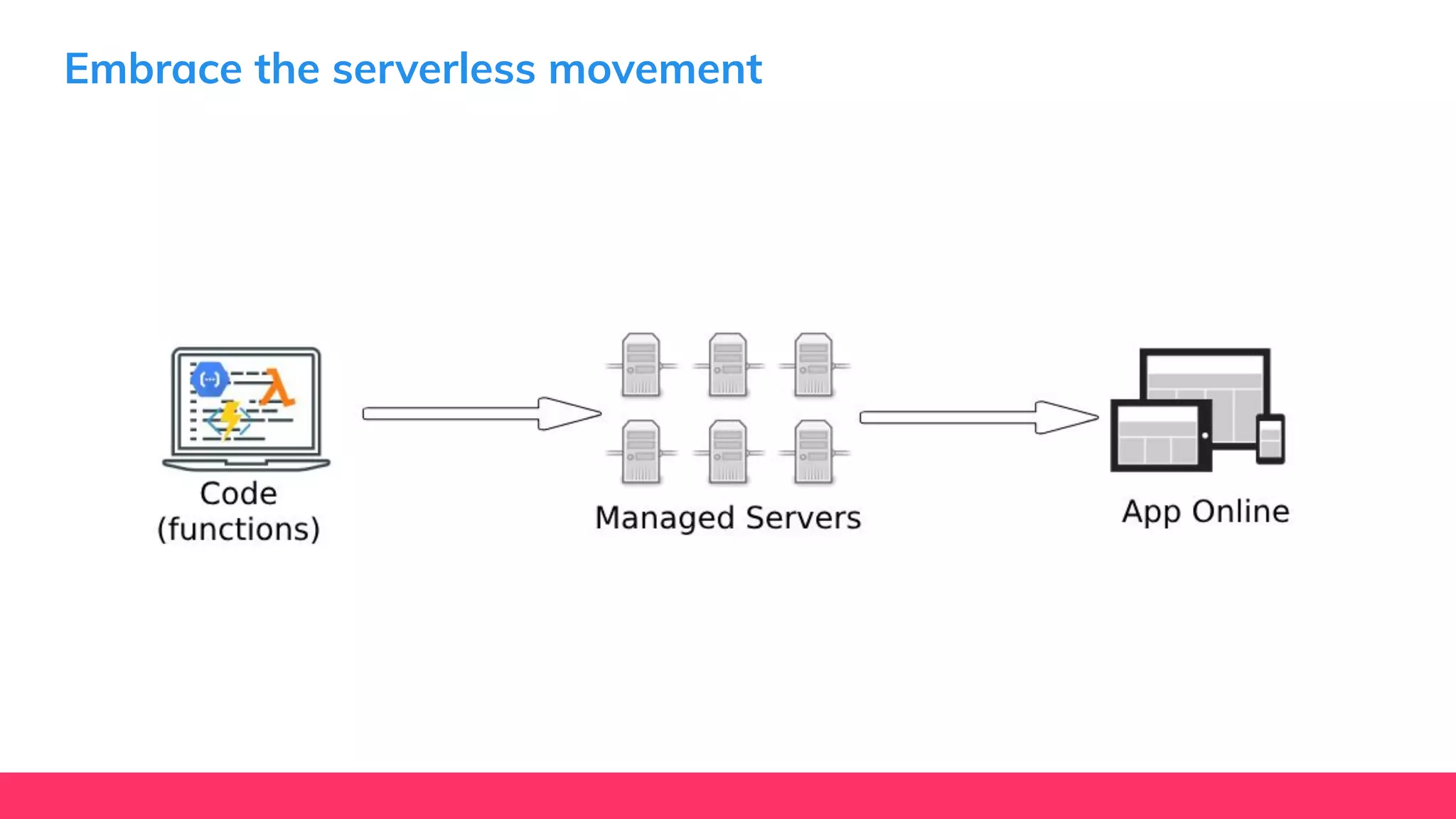







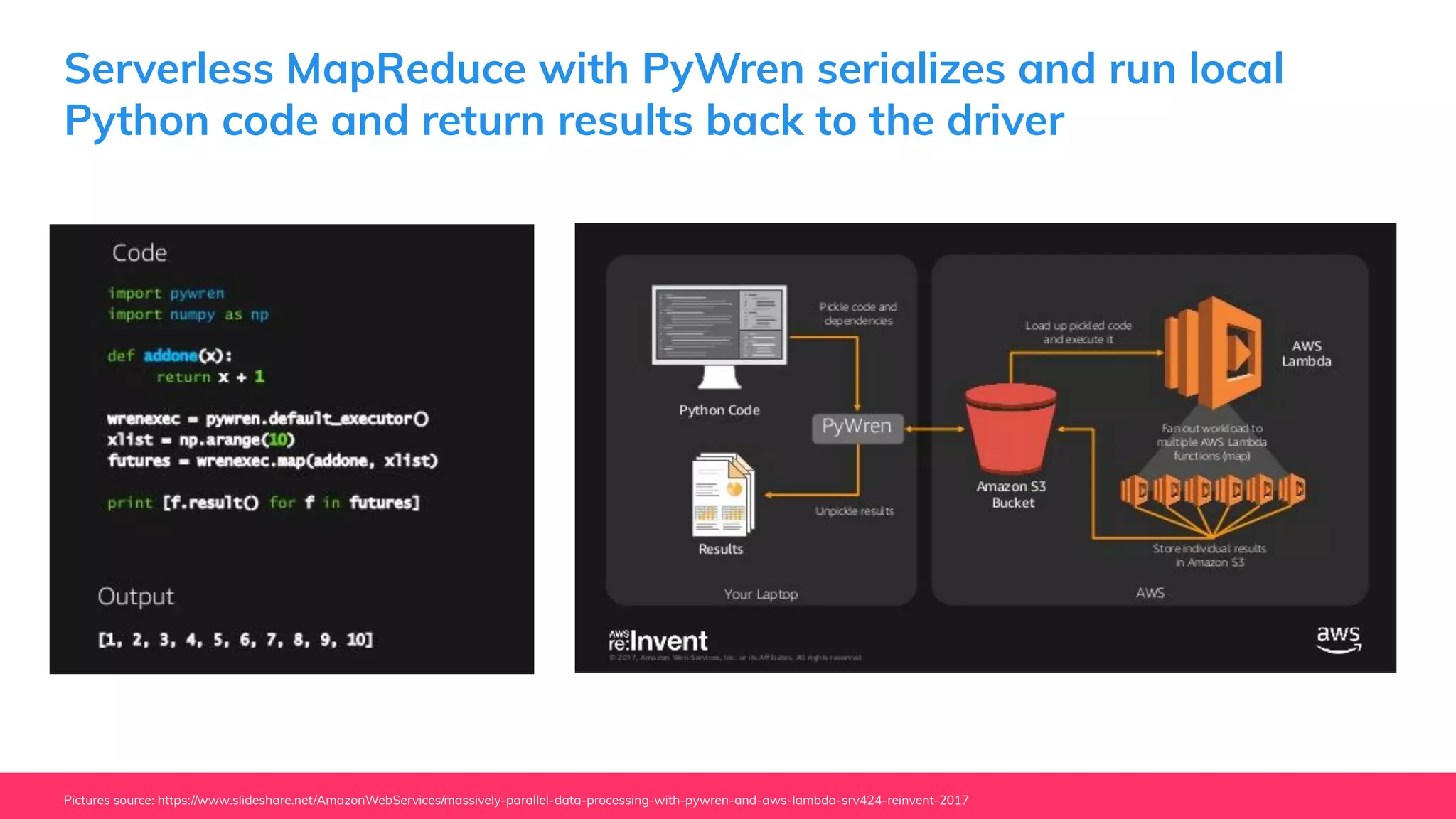
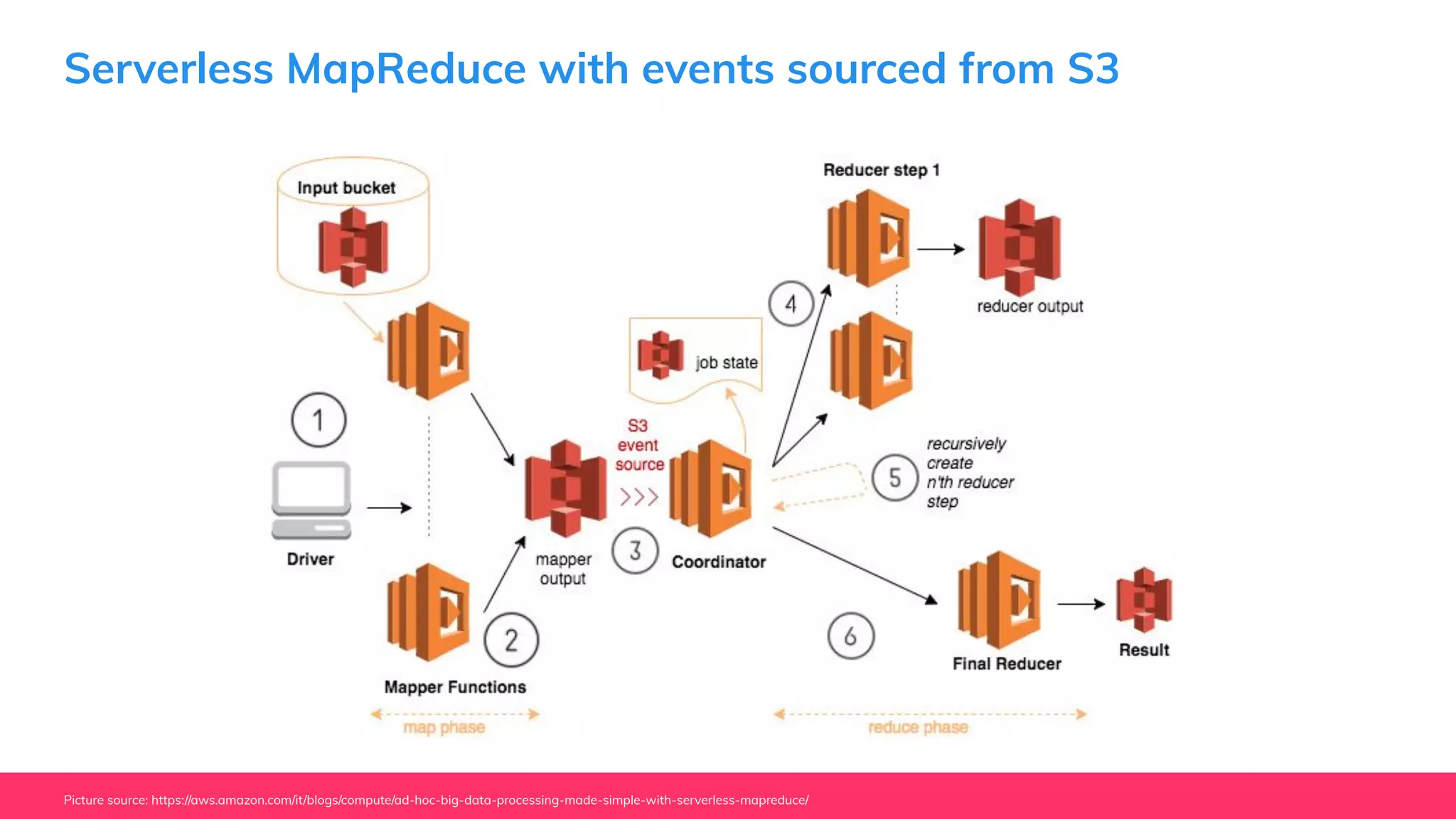
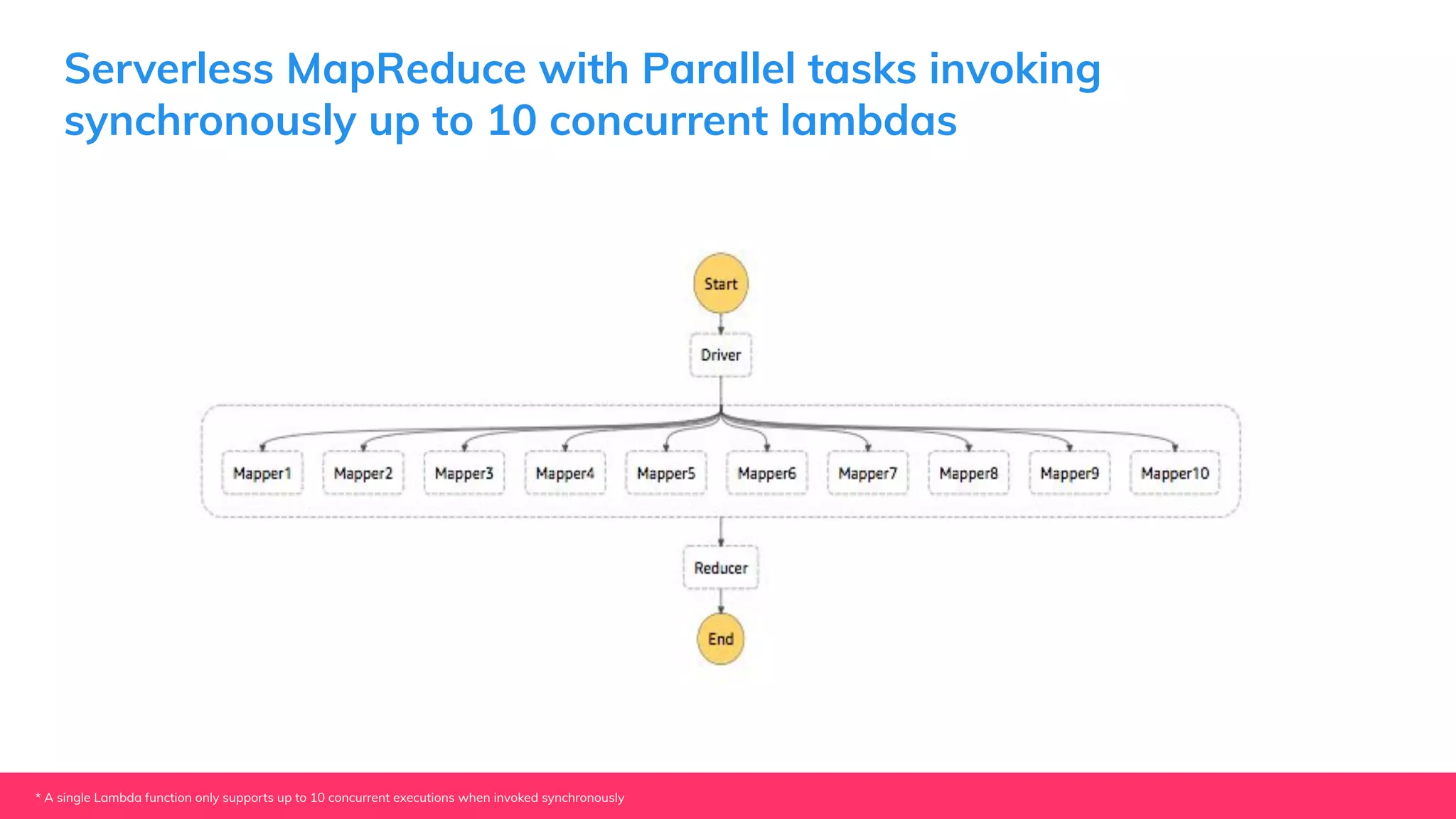
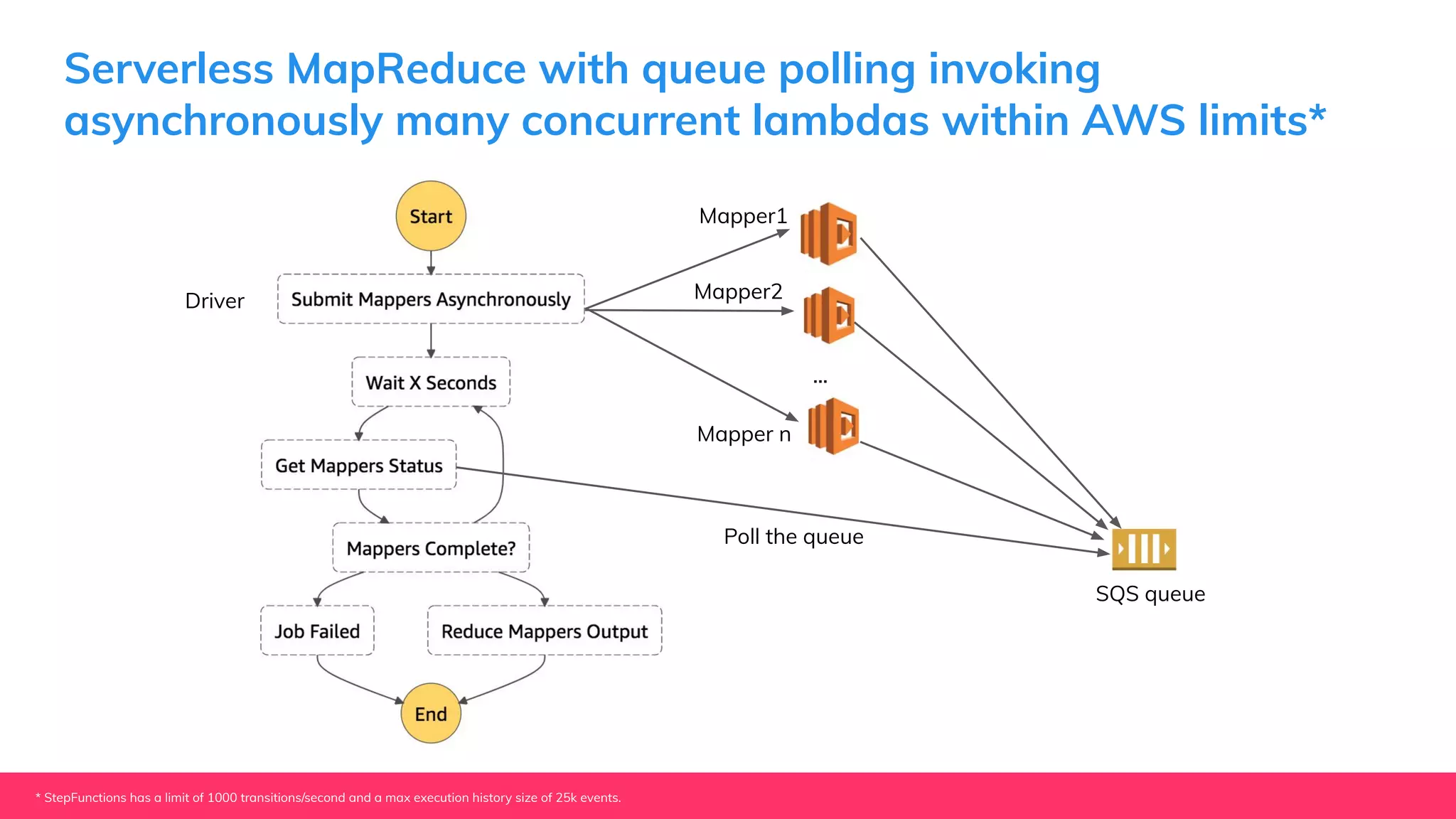
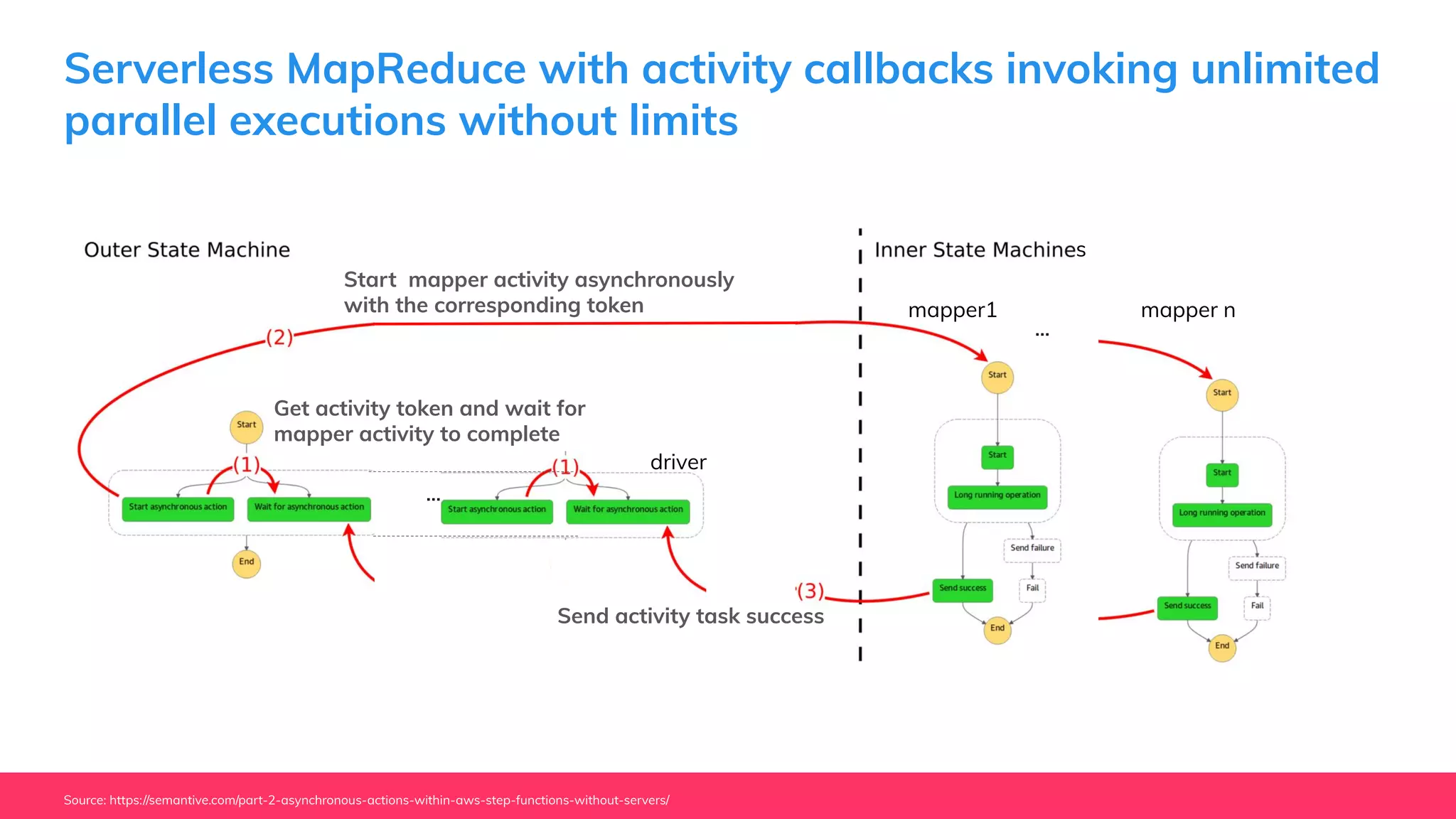

This document provides guidance for machine learning product managers and technical leaders on building effective ML products. It discusses introducing ML in enterprises, defining product specifications, planning under uncertainty, and building balanced ML teams. It also covers the ML product lifecycle, including tracking experiments, centralized data storage, automated testing, continuous integration, and serverless architectures. Serverless computing can help simplify deployments, improve scalability, and reduce costs.








































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















