Download to read offline






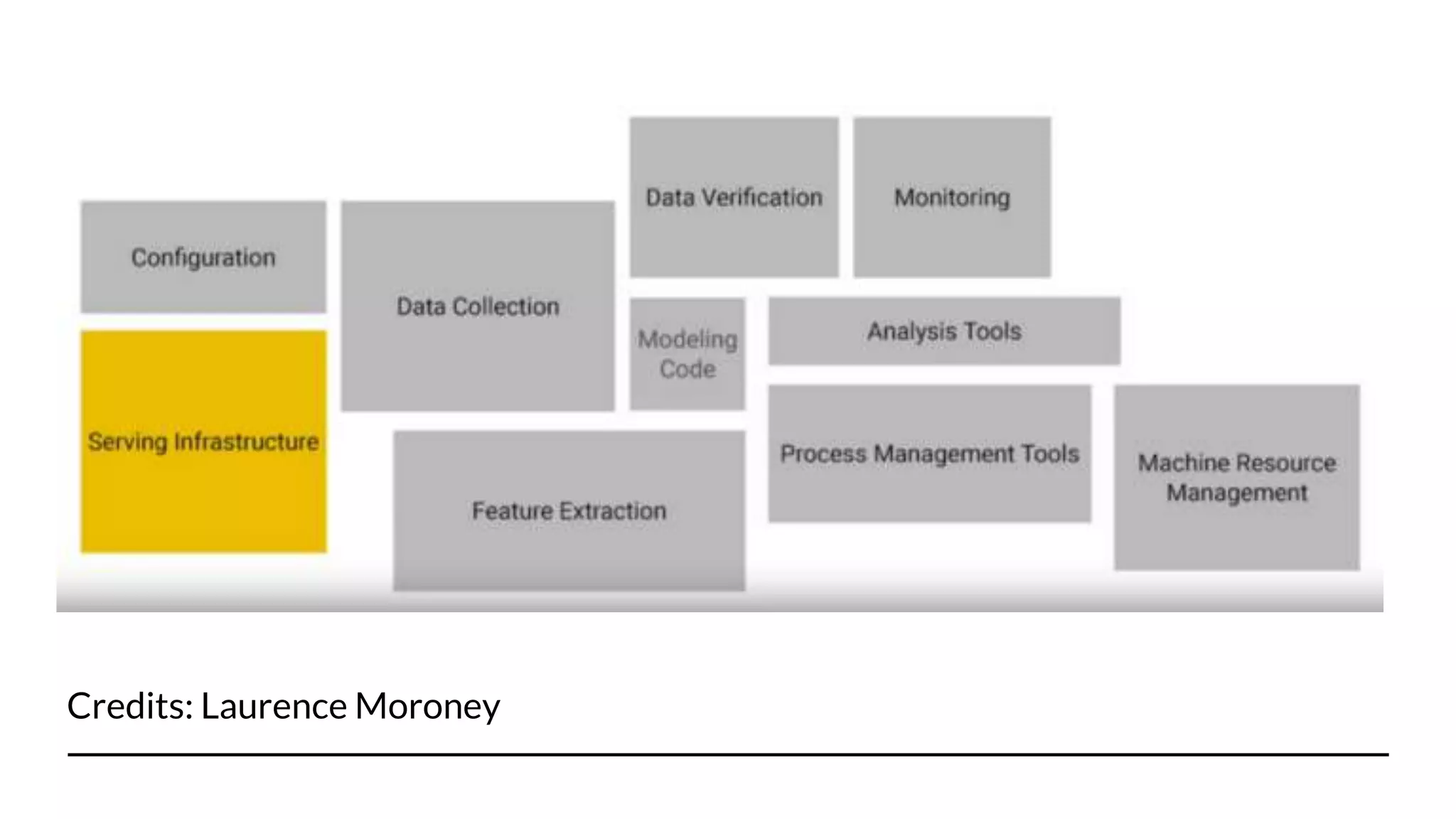



















This document discusses model drift monitoring using TensorFlow Model Analysis (TFMA). It begins with an introduction to the presenter and an overview of monitoring machine learning models in production. It then defines model drift as changes in the statistical structure of data over time which can degrade a model's performance. The production point of view for model monitoring is discussed as defining thresholds, detecting violations, and safeguarding systems. TFMA is introduced as a library for evaluating models on large datasets in a distributed manner and comparing metrics over time and across data slices for monitoring model quality and performance. The presentation concludes with a code demo and Q&A.











































































