Downloaded 25 times


![ILSVRC2012データセット
3
ImageNet Large Scale Visual Recognition
Challenge(ILSVRC)2012のためのデータセット
● ILSVRC2012の画像識別タスクでは
トロント大Hintonが率いるチームがAlexNet[1]で圧勝
● Deep Learningブームの立役者
● ILSVRC2012で学習した識別器etc.が世を席巻
画像識別タスクのデータセットは
1000クラス約140万枚の画像からなる
2020年現在も,CNNの事前学習モデルの
学習データとして広く利用
[1] Krizhevsky et al.. “Imagenet classification with deep convolutional neural networks” NuerIPS 2012.](https://image.slidesharecdn.com/interactionrethinkingandbeyondimagenet-200430151050/85/Rethinking-and-Beyond-ImageNet-3-320.jpg)





![ImageNet-trained CNNs are biased towards texture;
increasing shape bias improves accuracy and robustness
10
会議 : ICLR2019
著者 R, Geirhos[1,2], P. Rubisch[1,3], C. Michaelis[1,2], M. Bethge[1,3], F. A. Wichmann[1],
W. Brendel[1] ([1]University of Tubingen, [2] IMPRS-IS, [3] University of Edinburgh),
● ILSVRC2012で学習したCNNは,テクスチャに頼って判断していることを示す
● 形状を認識して学習するためのStyle-ImageNetを構築し,
Style-ImageNetで学習したモデルはテクスチャに過適合しないことを確認
ILSVRC2012で学習したCNNはテクスチャに過適合
形状に関わらず,像のテクスチャの画像は像と比較的高い事後確率で判断される](https://image.slidesharecdn.com/interactionrethinkingandbeyondimagenet-200430151050/85/Rethinking-and-Beyond-ImageNet-10-320.jpg)

![Towards Fairer Datasets: Filtering and Balancing
the Distribution of the People Subtree in the ImageNet Hierarchy
12
会議 : ACM FAT* 2020
著者 : K. Yang[1], K. Qinami[1], L. Fei-Fei[2], J. Deng[1], O. Russakovsky[1]
([1]Princeton University, [2]Stanford University)
● ILSVRC2012を含むImageNetの人物に関するラベルを持つ画像を調査し,
公平性の観点から適切なラベルは2,832カテゴリのうち158カテゴリのみであることを報告
● データセットの公平性を調査をクラウドソーシングを用いて行うための
Webインターフェースを公開
ジェンダー(男/女/不明),肌の色(明/暗/中間),年齢の割合をクラスごとに示したグラフ。
ImageNetの時点で人物に関するfairnessに問題あり](https://image.slidesharecdn.com/interactionrethinkingandbeyondimagenet-200430151050/85/Rethinking-and-Beyond-ImageNet-12-320.jpg)













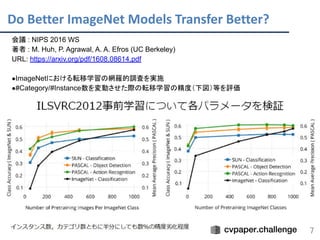
p7タイトル: "Do Better ImageNet Models Transfer Better? " -> "What makes ImageNet good for transfer learning?"の誤りでした。大変申し訳ございません。 cvpaper.challenge の メタサーベイ発表スライドです。 cvpaper.challengeはコンピュータビジョン分野の今を映し、トレンドを創り出す挑戦です。論文サマリ作成・アイディア考案・議論・実装・論文投稿に取り組み、凡ゆる知識を共有します。2020の目標は「トップ会議30+本投稿」することです。 http://xpaperchallenge.org/cv/



![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)

















![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)
