Download as PDF, PPTX





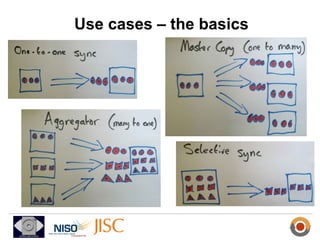
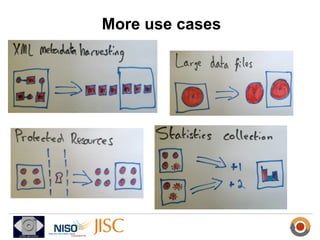








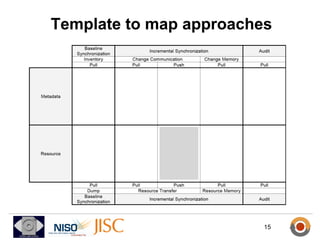
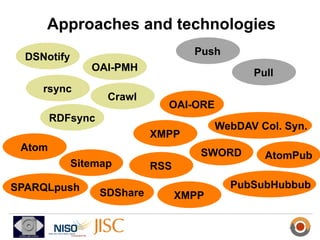






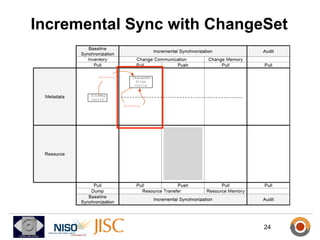


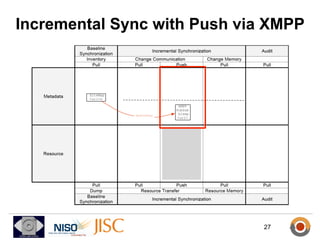



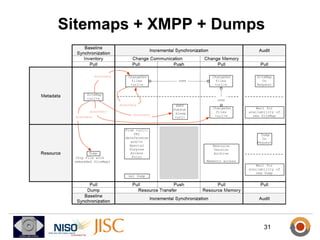



ResourceSync is a framework for synchronizing web resources between systems. The core team is developing standards for baseline synchronization using inventories, incremental synchronization using changesets, and push notifications using XMPP. The framework is based on reusing and extending existing sitemap formats to describe resources and changes in a modular way. Experiments show it can scale to synchronize large datasets like DBpedia and arXiv. Feedback is being solicited throughout 2012 to finalize the specifications.






















































































