Downloaded 20 times






![What does OpenSeadragon need?
[07/Jun/2017 05:32:44] "GET /starfish/info.json HTTP/1.1”
[07/Jun/2017 05:32:44] "GET /starfish/full/375,/0/default.jpg HTTP/1.1”
[07/Jun/2017 05:32:44] "GET /starfish/full/750,/0/default.jpg HTTP/1.1”
[07/Jun/2017 05:33:31] "GET /starfish/0,0,2048,2048/1024,/0/default.jpg
HTTP/1.1”
[07/Jun/2017 05:33:31] "GET /starfish/0,2048,2048,1952/1024,/0/default.jpg
HTTP/1.1”
[07/Jun/2017 05:33:32] "GET /starfish/2048,0,952,2048/476,/0/default.jpg
HTTP/1.1”
[07/Jun/2017 05:33:32] "GET
/starfish/2048,2048,952,1952/476,/0/default.jpg HTTP/1.1”
[07/Jun/2017 05:33:32] "GET
/starfish/1024,1024,1024,1024/1024,/0/default.jpg HTTP/1.1”
[07/Jun/2017 05:33:32] "GET
/starfish/1024,2048,1024,1024/1024,/0/default.jpg HTTP/1.1”
[07/Jun/2017 05:34:17] "GET /starfish/0,1024,1024,1024/1024,/0/default.jpg
info.json
small full
tiles](https://image.slidesharecdn.com/2017-06iiifvaticanstatictiles-170608170015/85/IIIF-without-an-image-server-No-problem-7-320.jpg)







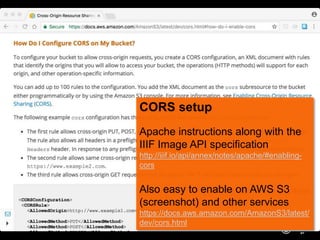
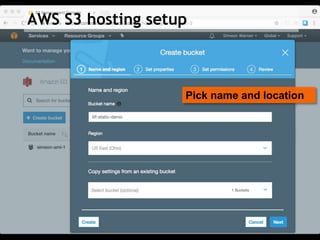

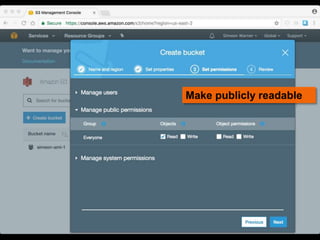
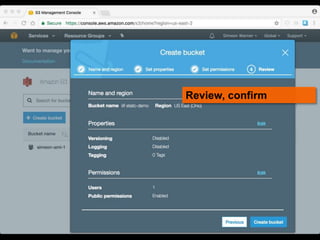
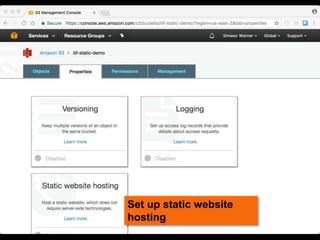
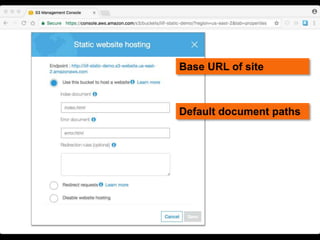




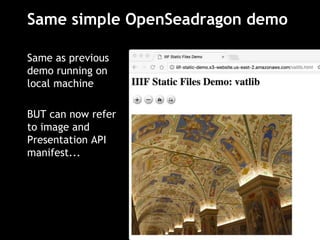








This document discusses how to implement the IIIF Image API using only static files on a web server, without a full image server. It describes how to generate tiles from an image that can be requested by IIIF viewers like OpenSeadragon. The tiles and other files like info.json are hosted using Amazon S3, enabling pan and zoom of the image in Universal Viewer and Mirador. The document emphasizes the importance of using HTTPS for security and avoiding mixed content issues.

![[오픈소스컨설팅]스카우터엑스 소개](https://cdn.slidesharecdn.com/ss_thumbnails/scouter-170208020005-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NHN_NEXT] 게임 휴먼 프로젝트 CI + GitHub 세팅 방법](https://cdn.slidesharecdn.com/ss_thumbnails/ci-140315010841-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[오픈소스컨설팅] 스카우터 사용자 가이드 2020](https://cdn.slidesharecdn.com/ss_thumbnails/2020scouteruserguide-200122014357-thumbnail.jpg?width=640&height=640&fit=bounds)
![[수정본] 우아한 객체지향](https://cdn.slidesharecdn.com/ss_thumbnails/woowahan-oo-190624161343-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DevGround] 린하게 구축하는 스타트업 데이터파이프라인](https://cdn.slidesharecdn.com/ss_thumbnails/devgroundkmongrevisedcraig190627finalscriptformatted-190828020444-thumbnail.jpg?width=640&height=640&fit=bounds)































































