
Download to read offline


































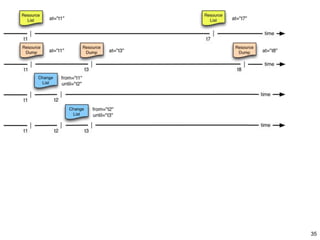














![Resource List
• Describe Source’s resources that are subject to synchronization
• At one point in time (snapshot)
• Creation can take some time – duration can be conveyed
• Typical Destination use: Baseline Synchronization, Audit
• Each URI typically listed only once
• Might be expensive to generate
• Destinations use @at to determine freshness
• [@at, @completed] – interval of uncertainty
• Destination issues GETs against URIs to obtain resources
• Very similar to current Sitemaps
ResourceSync Webinar
December 3 2013
50](https://image.slidesharecdn.com/slideshareresourcesynctraining12032013-131203131314-phpapp01/85/NISO-ResourceSync-Training-Session-50-320.jpg)


![Resource Dump
• A Resource Dump points to packages (ZIP files) that contain
representations of the Source’s resources
• At one point in time (snapshot)
• Resource Dump is mandatory, even if there is only one ZIP file
• ZIP package contains manifest, listing contained bitstreams
• Typical Destination use: Baseline Synchronization, bulk
download
• Each URI typically listed only once
• Might be expensive to generate
• Destinations use @at to determine freshness
• [@at, @completed] – interval of uncertainty
• GETs against individual URIs from Resource List achieves the
same result (ignoring varying freshness)
ResourceSync Webinar
December 3 2013
53](https://image.slidesharecdn.com/slideshareresourcesynctraining12032013-131203131314-phpapp01/85/NISO-ResourceSync-Training-Session-53-320.jpg)





















This document summarizes a webinar on ResourceSync, a framework for synchronizing web resources between systems. It provides an overview of the webinar agenda, which includes explaining the problem perspective and conceptual approach of ResourceSync, reviewing motivation and use cases, walking through the framework, and discussing technical details and implementation. The webinar presenters then take questions from the audience.























































































