Download to read offline





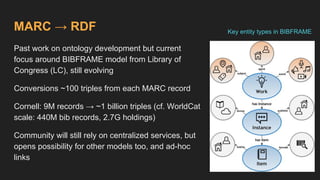
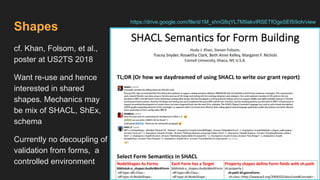


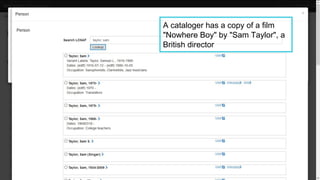
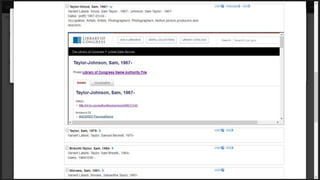
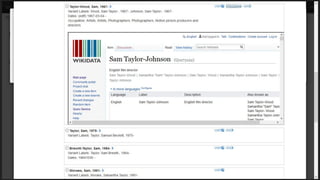
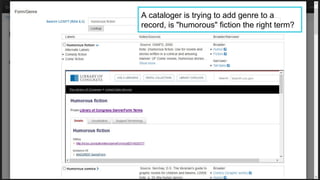

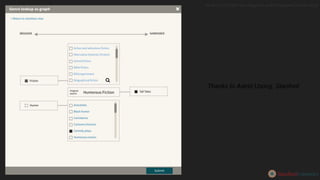
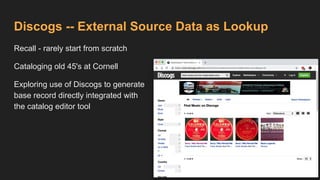




This document provides an overview of the development of a library knowledge graph editor as part of the ld4p2 project, showcasing contributions from various academic institutions. It discusses the transition from traditional MARC to RDF formats for better resource management and discovery, along with challenges in cataloging and lookup usability. Key focuses include enhancing entity linking, improving user interface experiences, and the necessity of contextual information for effective cataloging processes.























































































