Download to read offline












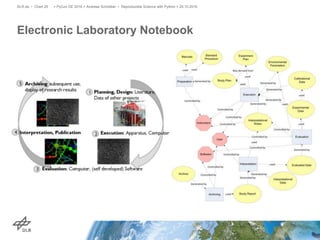
![Query „Who worked on experiment X?“
> PyCon DE 2016 > Andreas Schreiber • Reproducible Science with Python > 29.10.2016DLR.de • Chart 26
$experiment = g.key($_g, 'identifier', X)
$user = $experiment/inE/inV/outE[@label = controlled_by]](https://image.slidesharecdn.com/20161039reproduciblesciencewithpython-4zu3-161115155413/85/Reproducible-Science-with-Python-26-320.jpg)
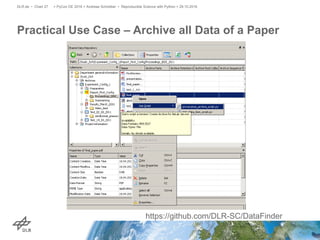



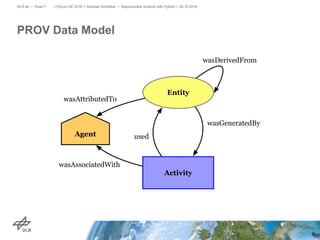
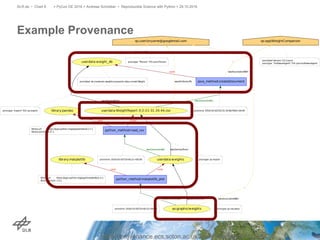
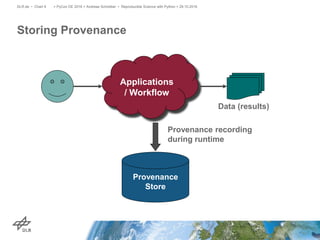
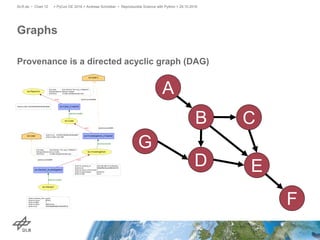
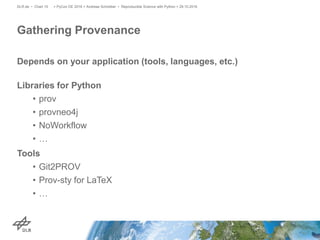
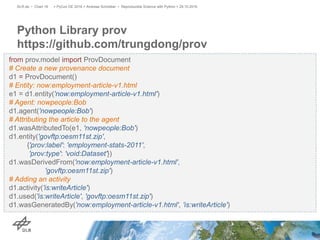
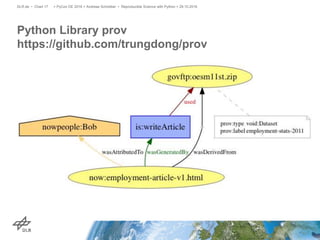
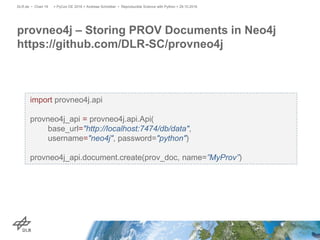
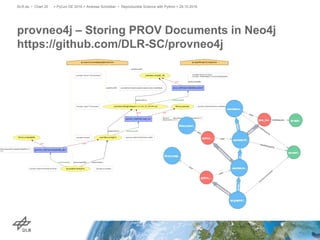
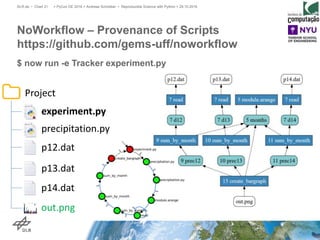
The document discusses making science more reproducible through provenance. It introduces the W3C PROV standard for representing provenance which describes entities, activities, and agents. Python libraries like prov can be used to capture provenance which can be stored in graph databases like Neo4j that are suitable for provenance graphs. Capturing provenance allows researchers to understand the origins and process that led to results and to verify or reproduce scientific findings.











































































































