This document provides an introduction and overview of StatsD, including:
- A brief history of StatsD and how it was originally created by Flickr and implemented by Etsy.
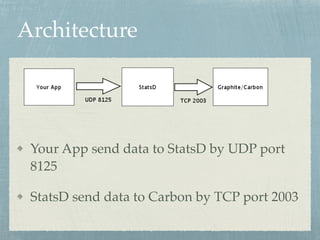
- An overview of the StatsD architecture which involves sending metrics from applications over UDP to the StatsD server, which then sends the data to Carbon over TCP.
- An explanation of the different metric types StatsD supports - counters, gauges, sets, and timings - and examples of common use cases.
- Instructions for installing and running a StatsD server as well as examples of using StatsD clients in Node.js and Java applications.




![Metric Types
Count [key]:[value]|c!
sample.counter:1|c!
At each flush the current count is sent and reset to 0!
Sampling!
sample.counter:1|c@0.1!
sent sampled every 1/10th of the time!
Scenarios!
View count
Reference: https://github.com/etsy/statsd/blob/master/docs/metric_types.md](https://image.slidesharecdn.com/statsdintroduction-141029082016-conversion-gate02/85/Statsd-introduction-6-320.jpg)
![Metric Types
Gauge [key]:[value]|g!
sample.gauge:75|g!
If the gauge is not updated at the next flush,
it will send the previous value.!
Scenarios!
Resource number](https://image.slidesharecdn.com/statsdintroduction-141029082016-conversion-gate02/85/Statsd-introduction-7-320.jpg)
![Metric Types
Set [key]:[value]|s!
sapmle.set:4219|s!
Counting unique occurrences of events between
flushes, using a Set to store all occurring events.!
Scenarios!
Unique user count](https://image.slidesharecdn.com/statsdintroduction-141029082016-conversion-gate02/85/Statsd-introduction-8-320.jpg)
![Metric Types
Timing [key]:[value]|ms!
sample.timer:10000|ms!
Scenarios!
To calculate the difference time!
Response time calculation](https://image.slidesharecdn.com/statsdintroduction-141029082016-conversion-gate02/85/Statsd-introduction-9-320.jpg)


![config.js!
Statsd UDP port: 8125!
Backends: [ "./backends/
console", "./backends/
graphite" ]
{
graphitePort: 2003,
graphiteHost: "graphite.hostname",
address: "127.0.0.1",
port: 8125,
mgmt_address: "127.0.0.1",
mgmt_port: 8126,
backends: [ "./backends/
graphite" ],
graphite: {
legacyNamespace: false,
globalPrefix: "stats",
prefixCounter: "counters",
prefixTimer: "timers",
prefixGauge: "gauges",
prefixSet: "sets"
}
}
StatsD Server](https://image.slidesharecdn.com/statsdintroduction-141029082016-conversion-gate02/85/Statsd-introduction-12-320.jpg)



![Java Client
public
class
Foo
{
private
static
final
StatsDClient
statsd
=
new
NonBlockingStatsDClient("my.prefix",
"statsd-‐host",
8125);
!
public
static
final
void
main(String[]
args)
{
statsd.incrementCounter("bar");
statsd.recordGaugeValue("baz",
100);
statsd.recordExecutionTime("bag",
25);
statsd.recordSetEvent("qux",
"one");
}](https://image.slidesharecdn.com/statsdintroduction-141029082016-conversion-gate02/85/Statsd-introduction-16-320.jpg)





































































