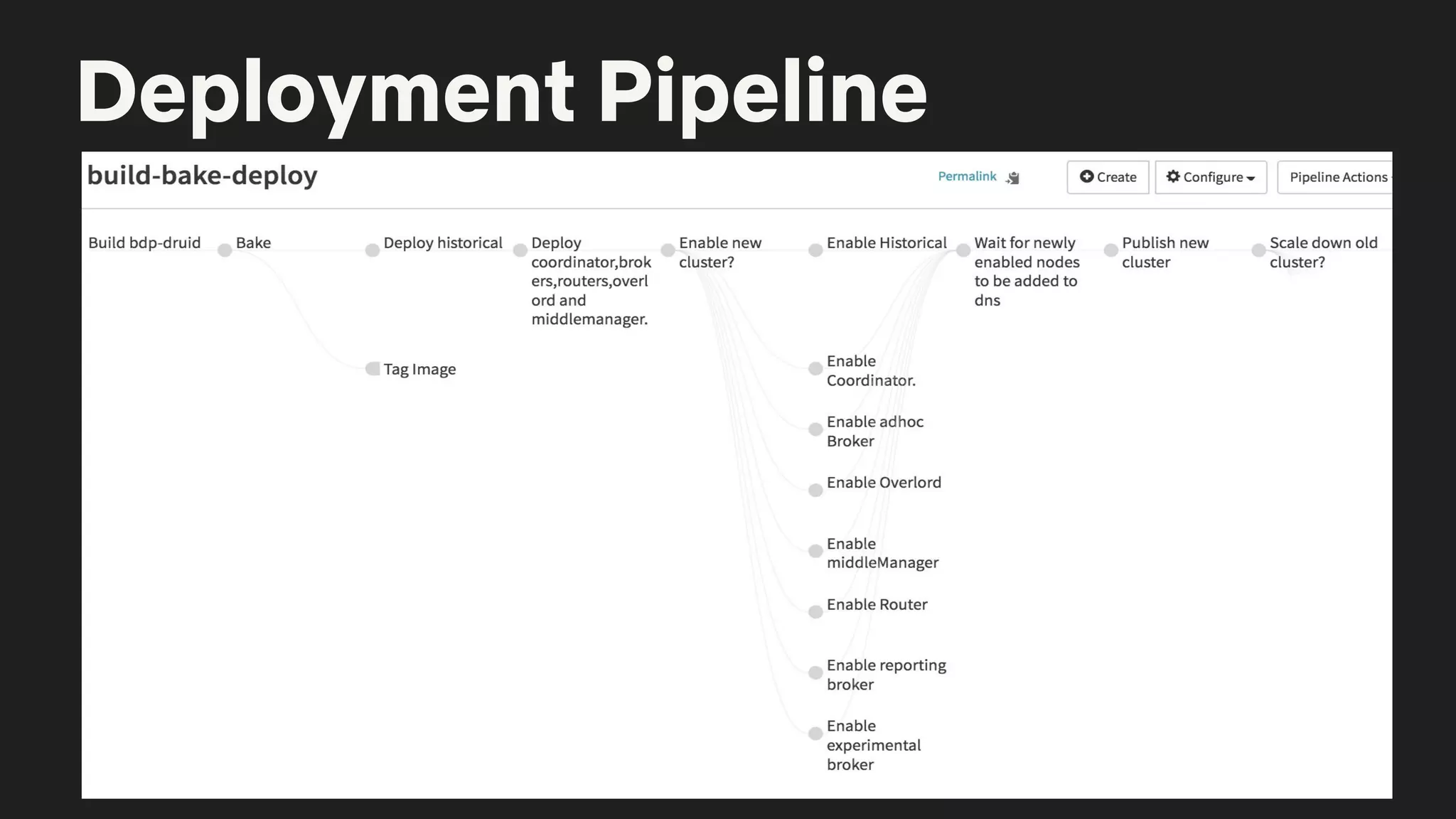
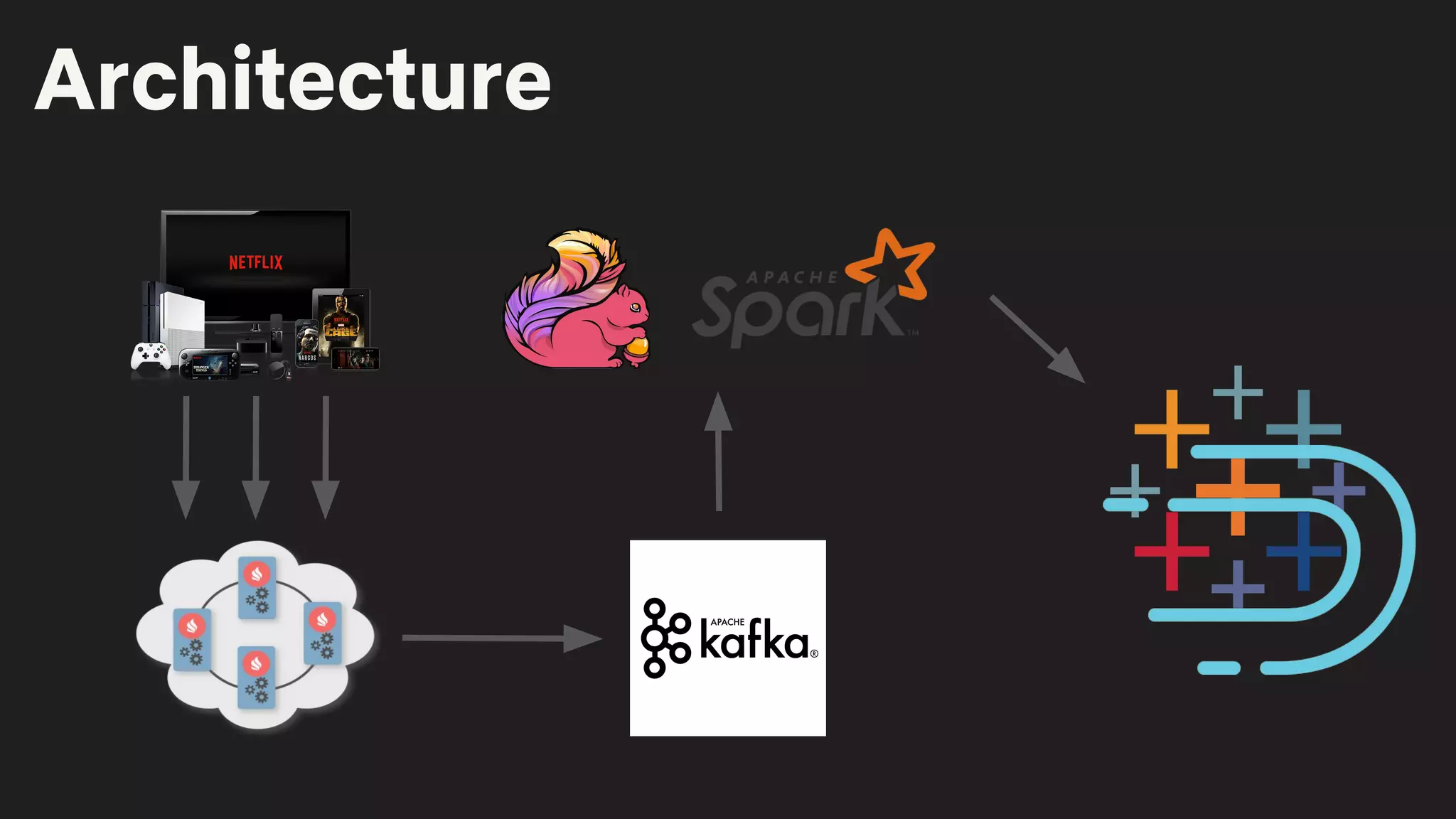
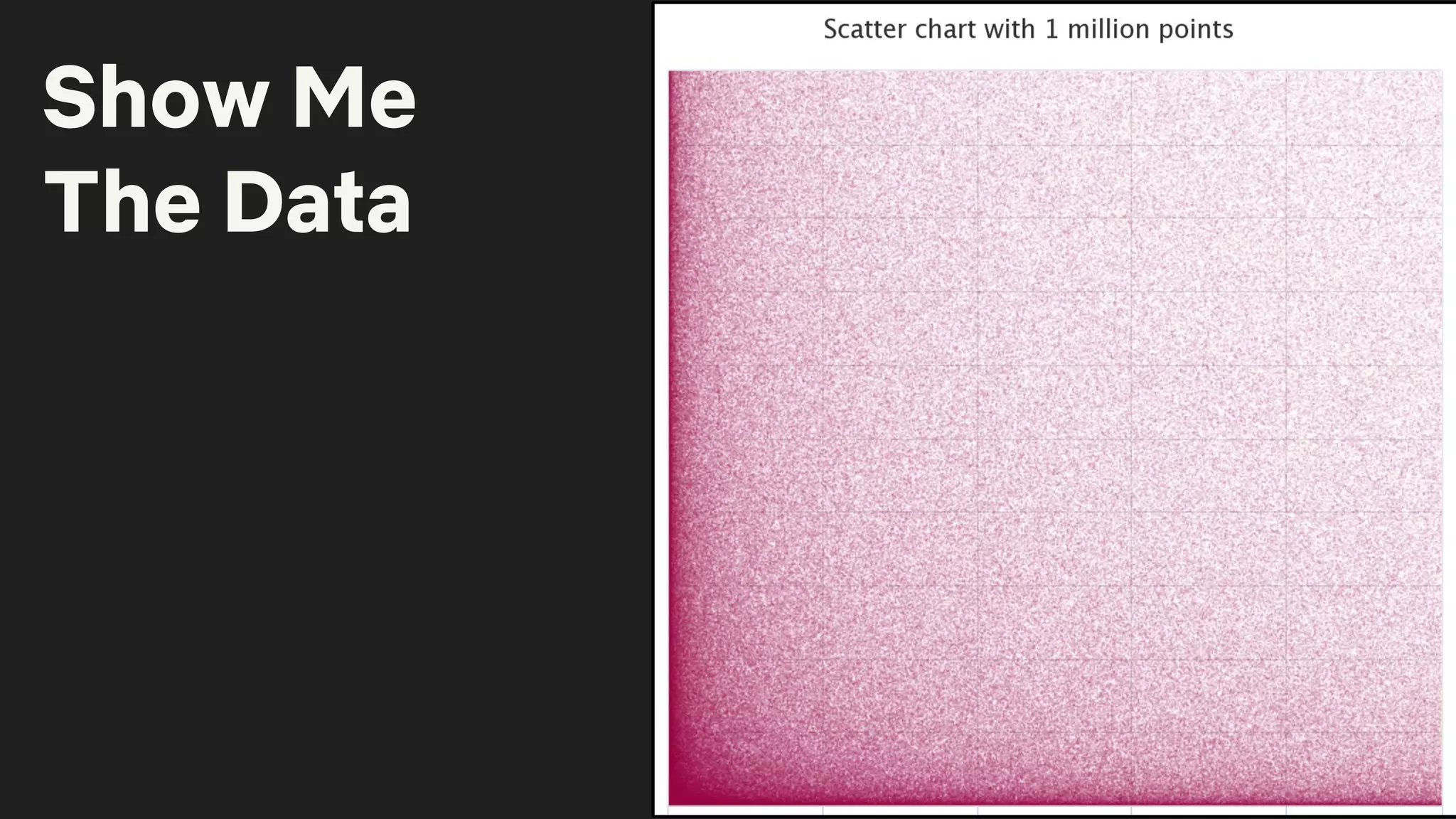
The document details a Druid meetup presentation focused on Druid deployment at Netflix, covering data ingestion, deployment strategies, and specific use cases like interactive dashboards and real-time processing. It highlights Netflix's capacity planning and how they manage 160 billion daily customer interactions while ensuring optimal client performance metrics. The Druid roadmap includes upcoming features and improvements, emphasizing community contributions and ongoing development goals.






























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)













































