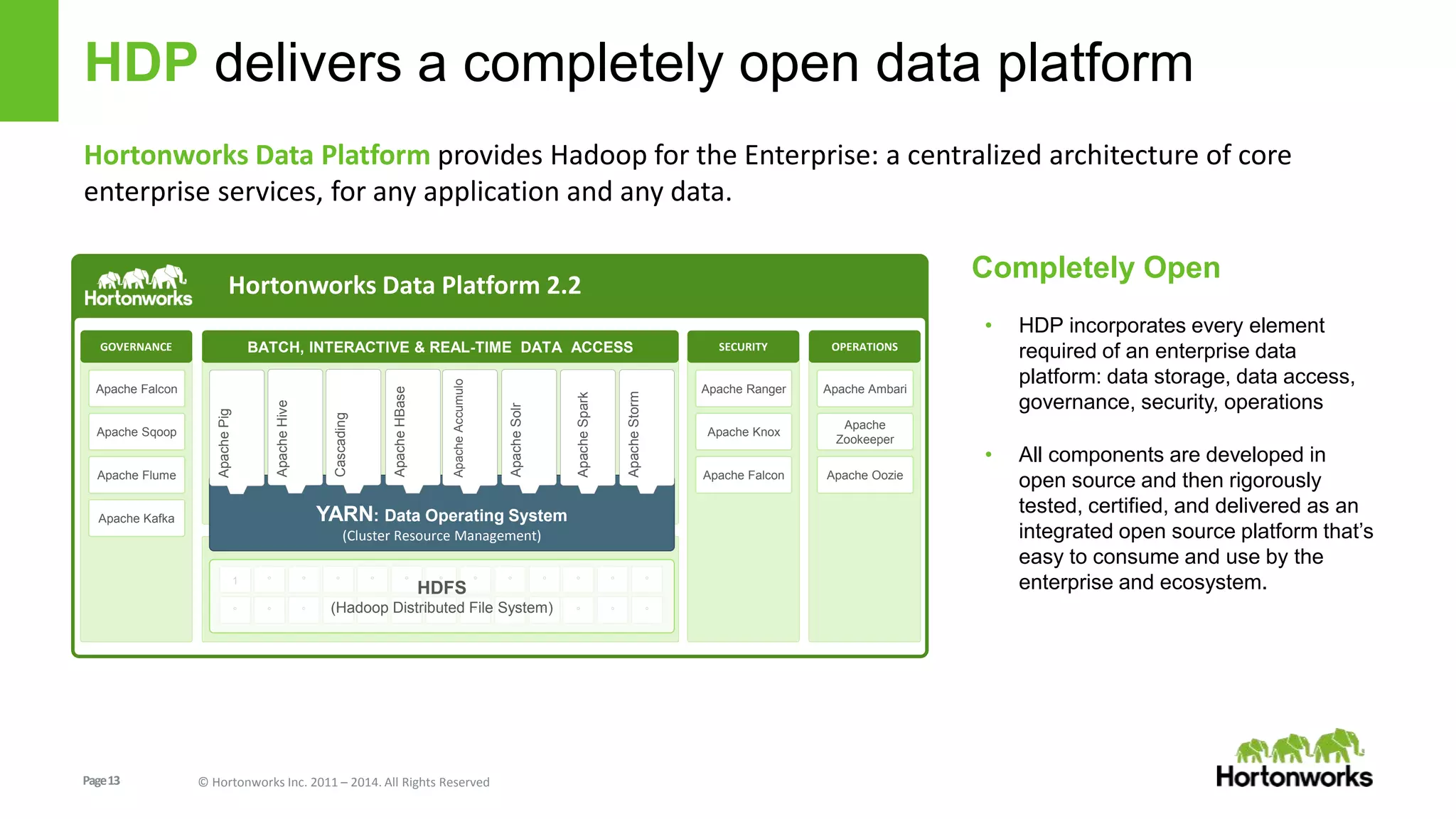
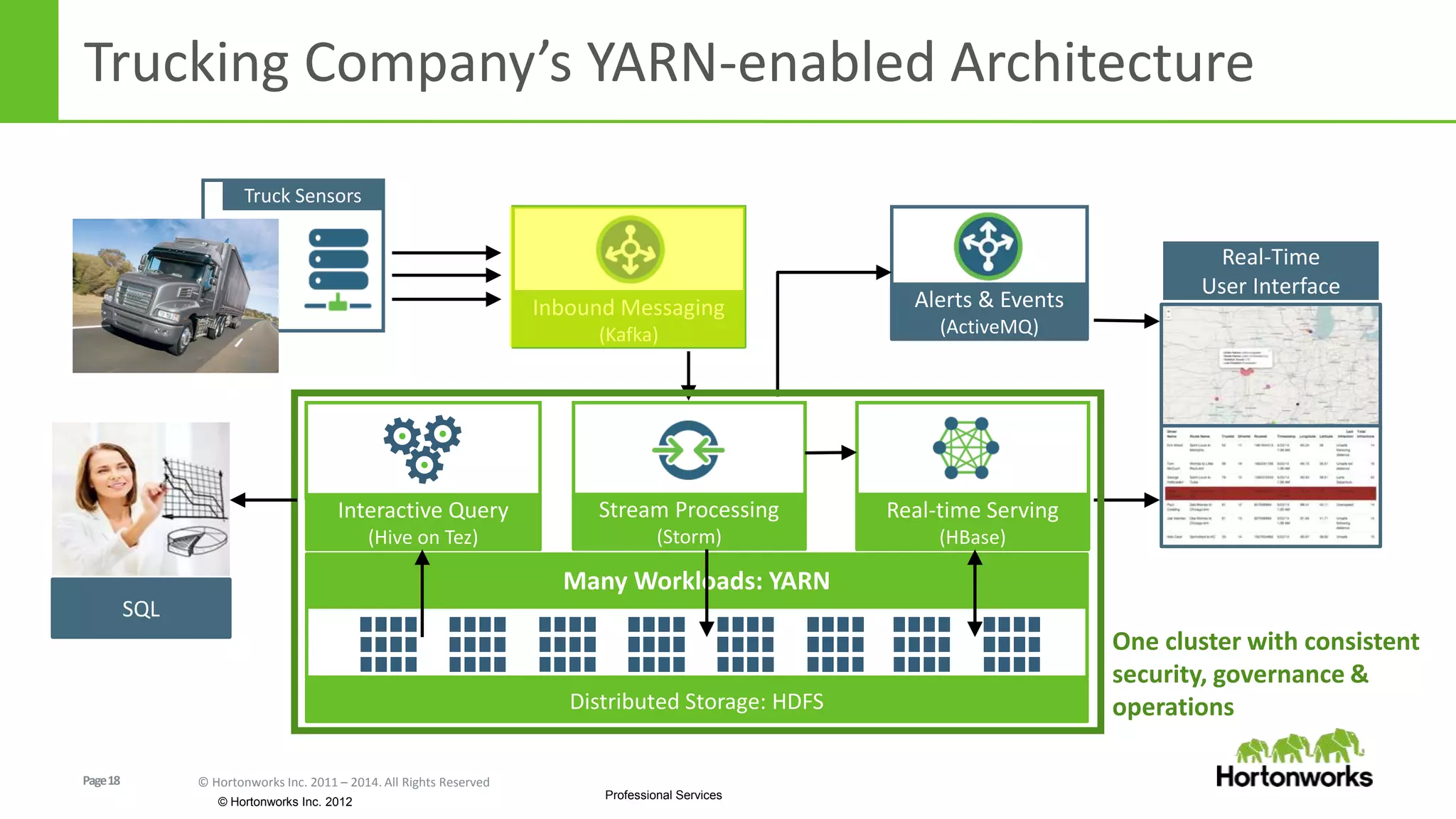
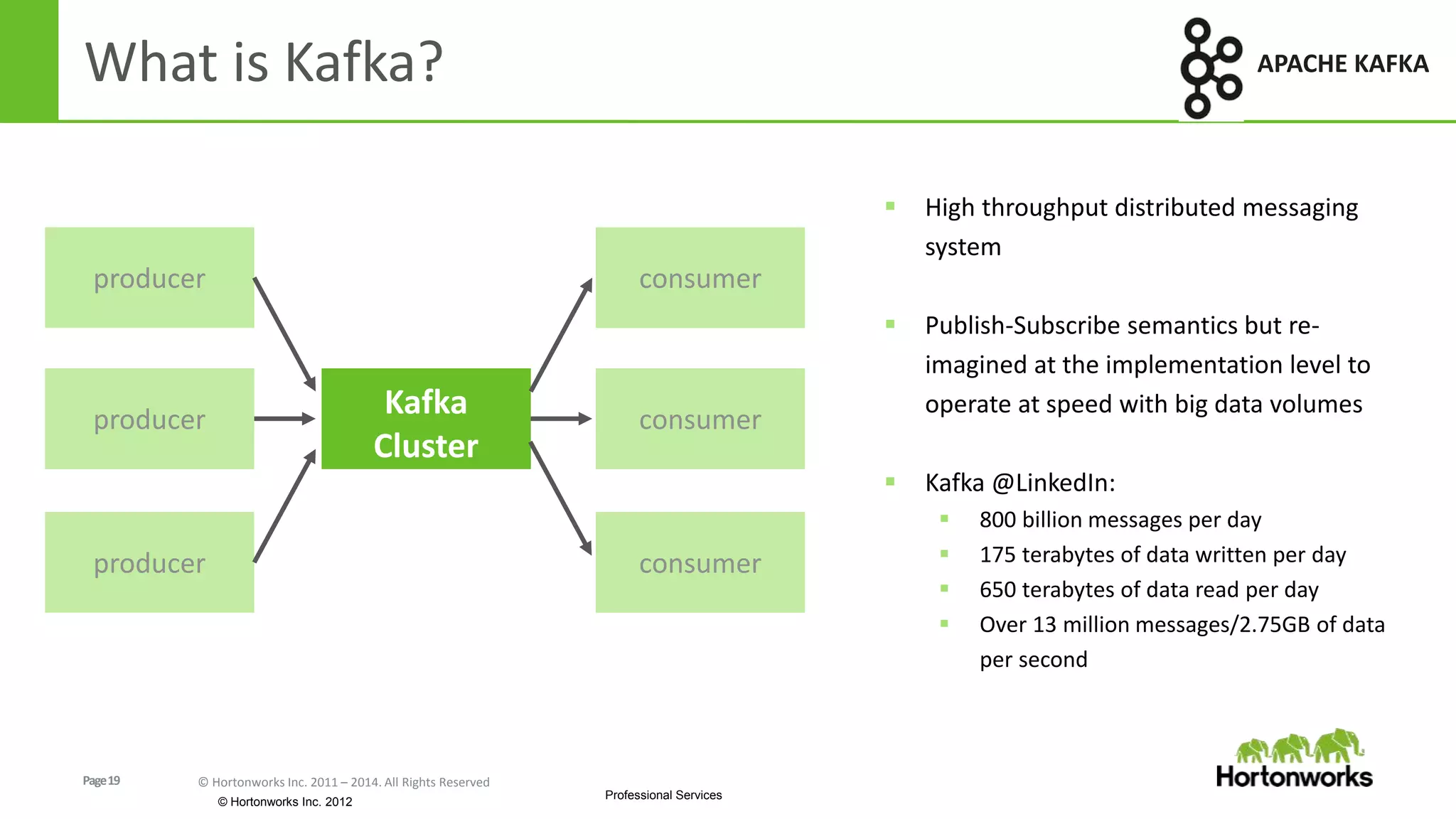
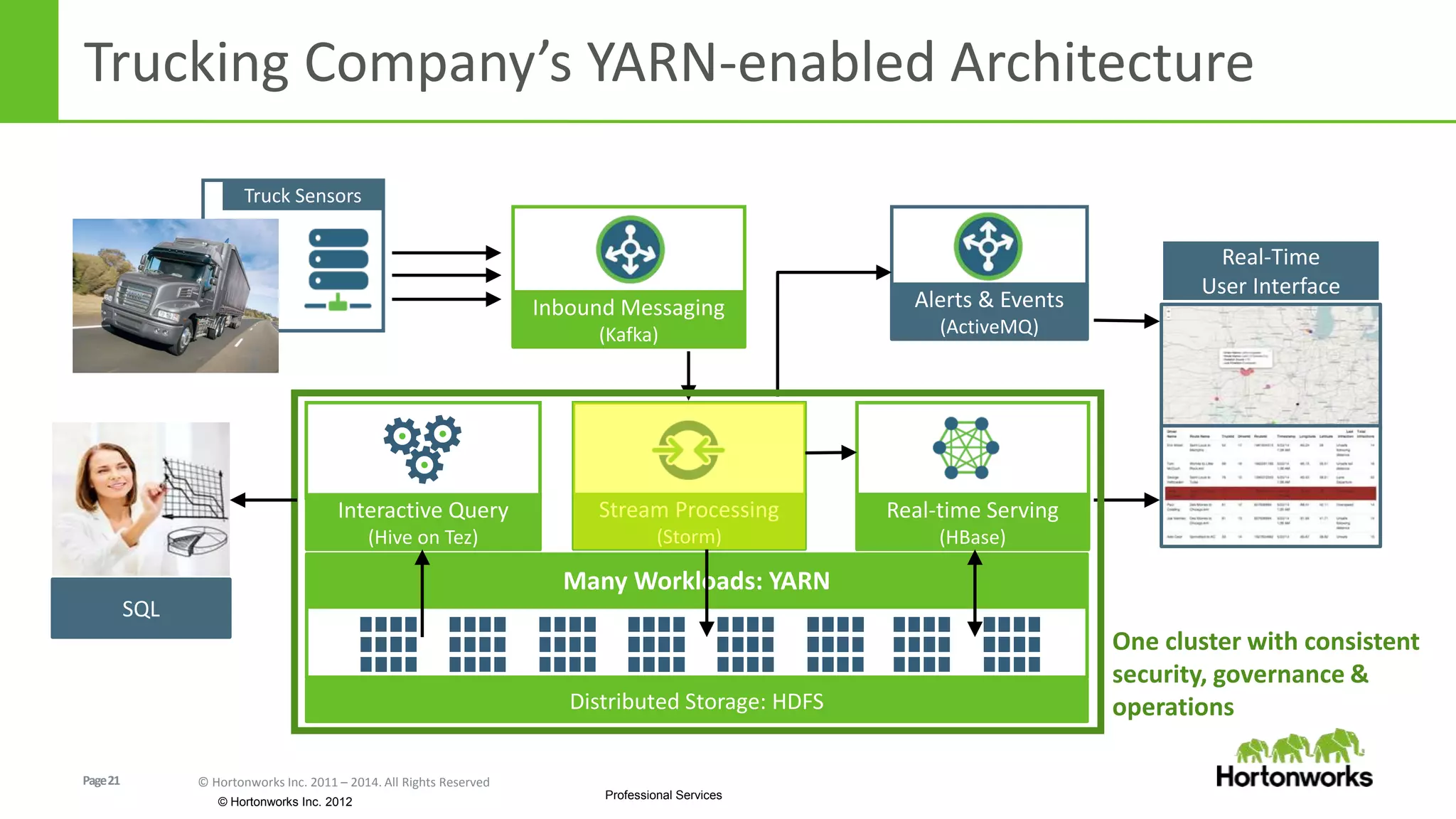
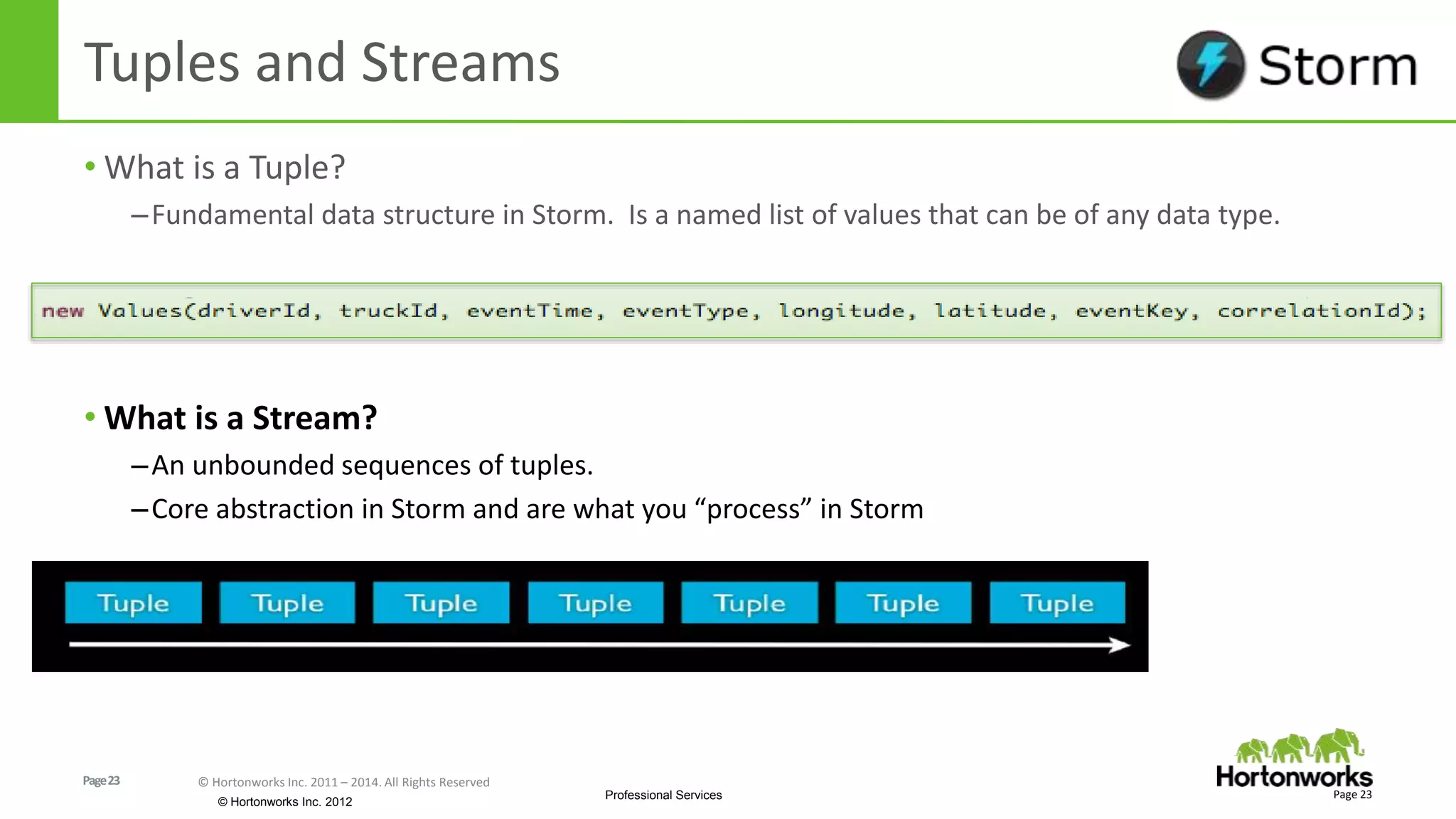
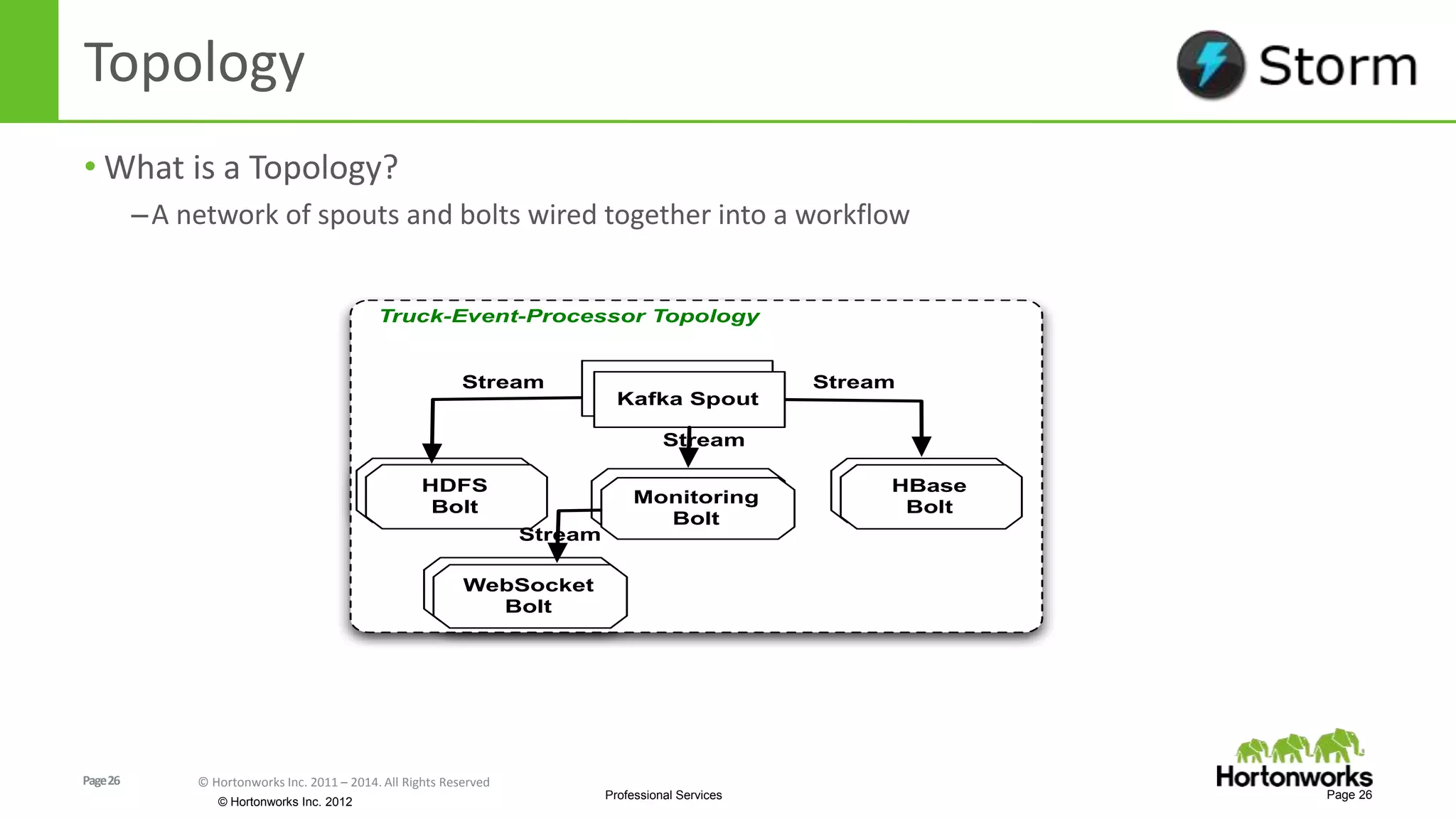
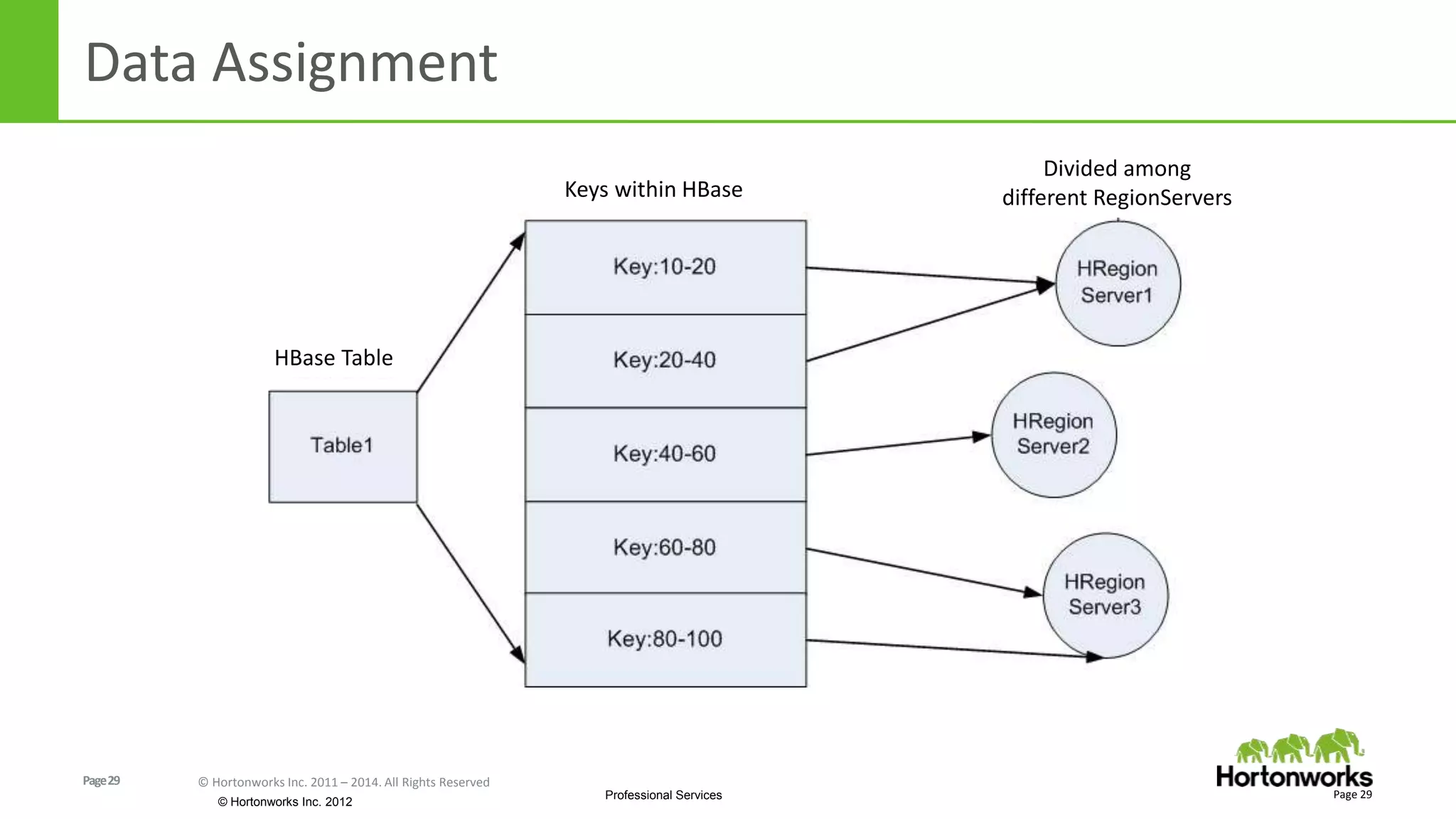
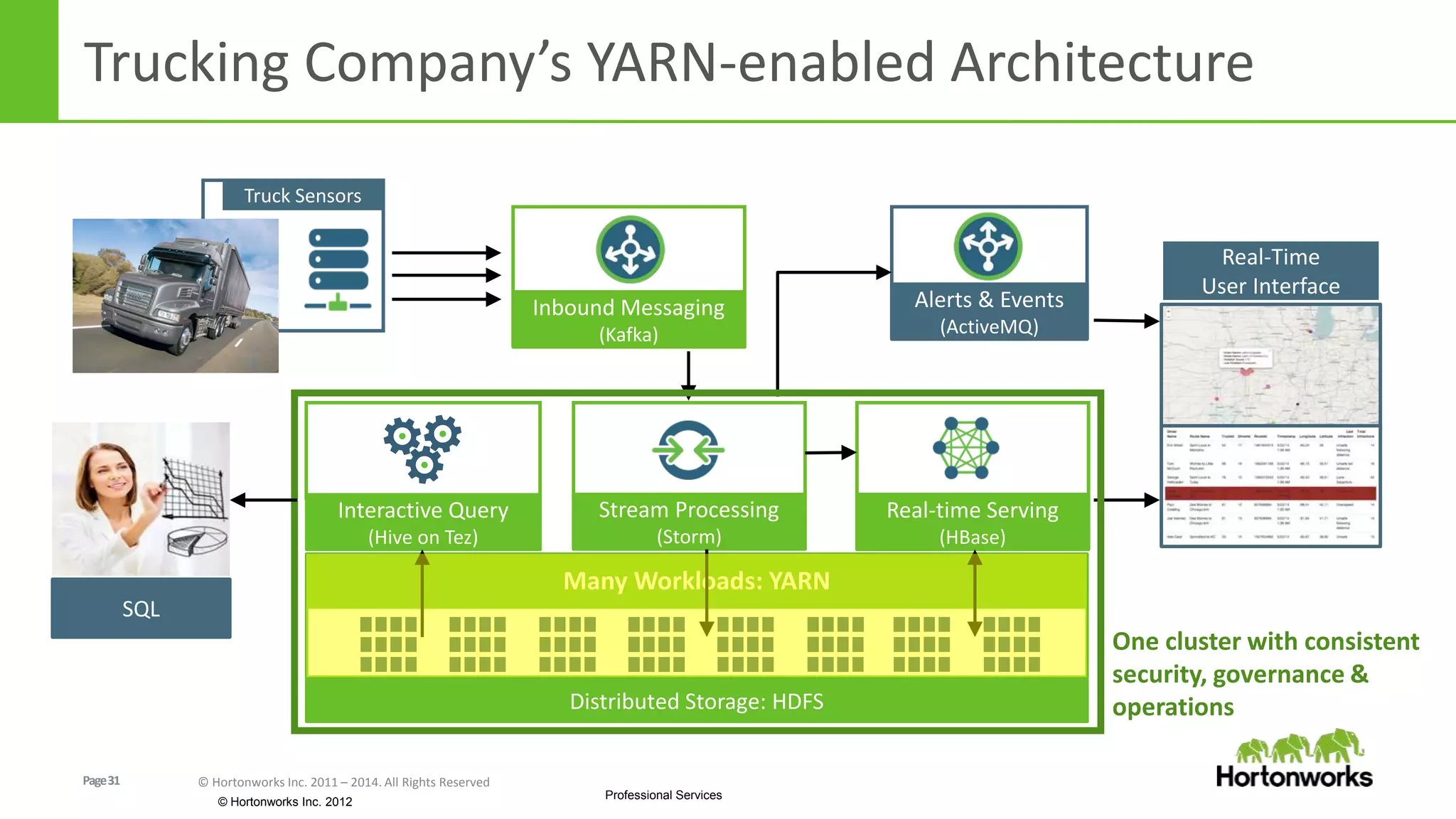
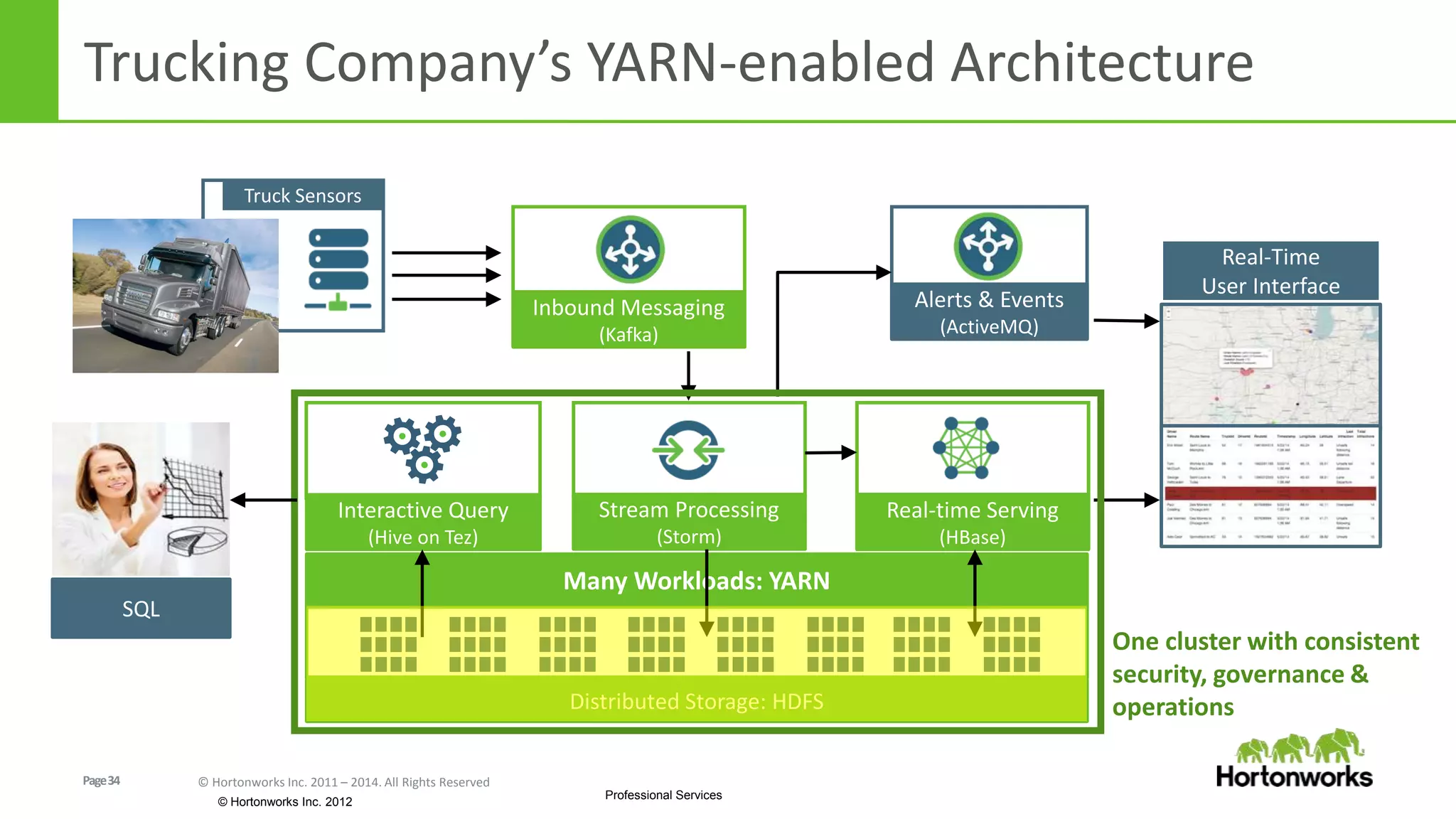
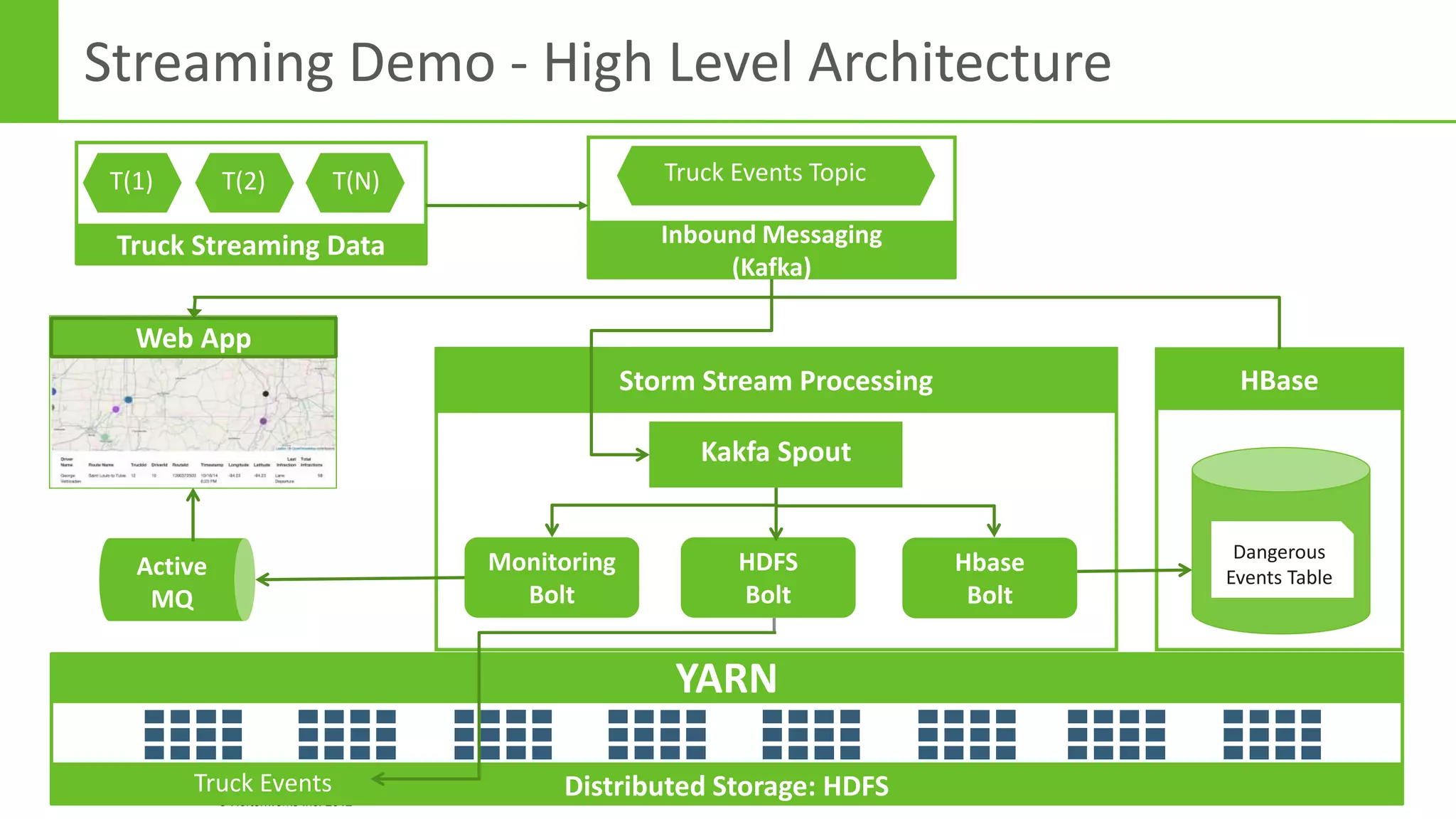
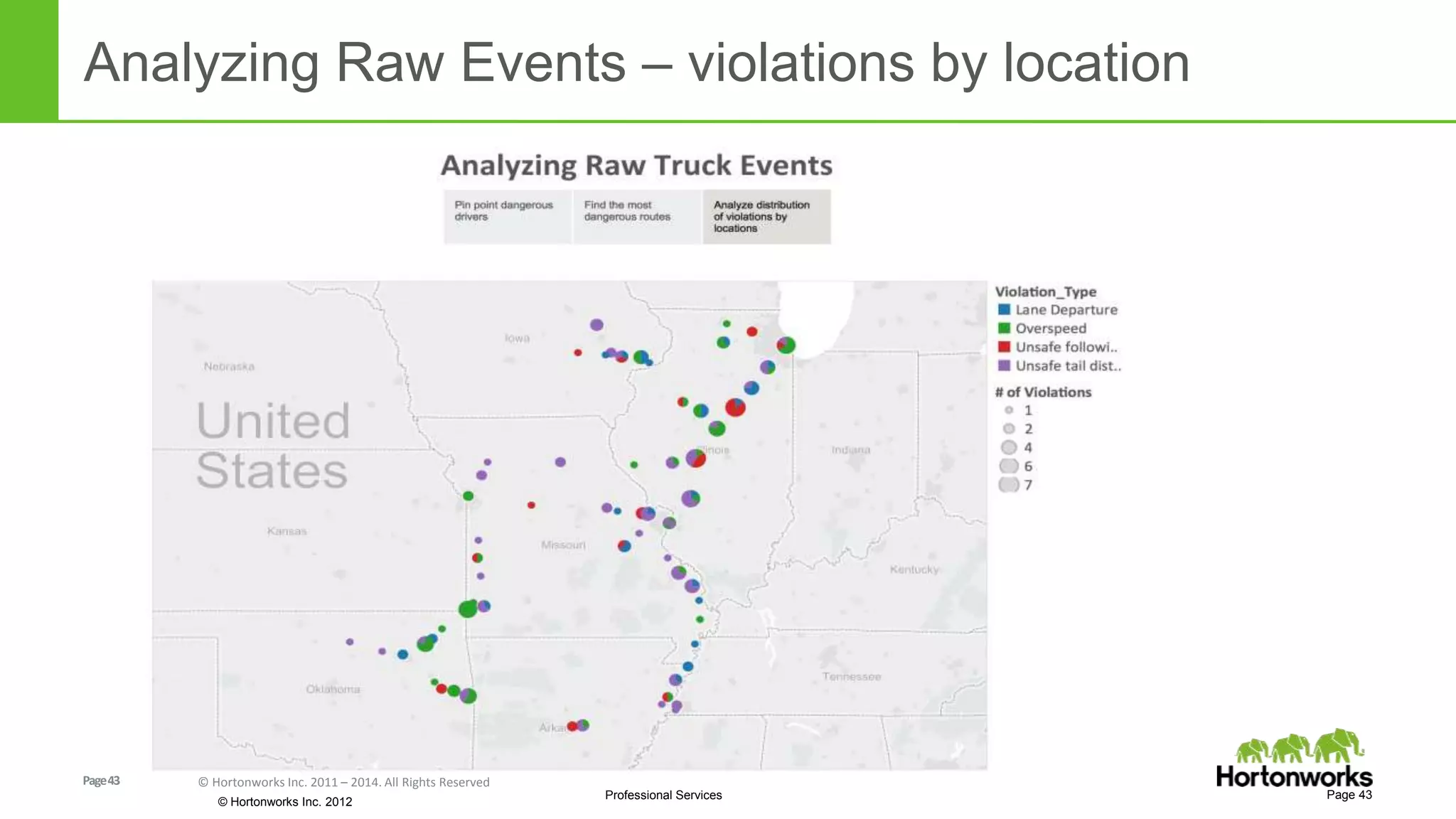
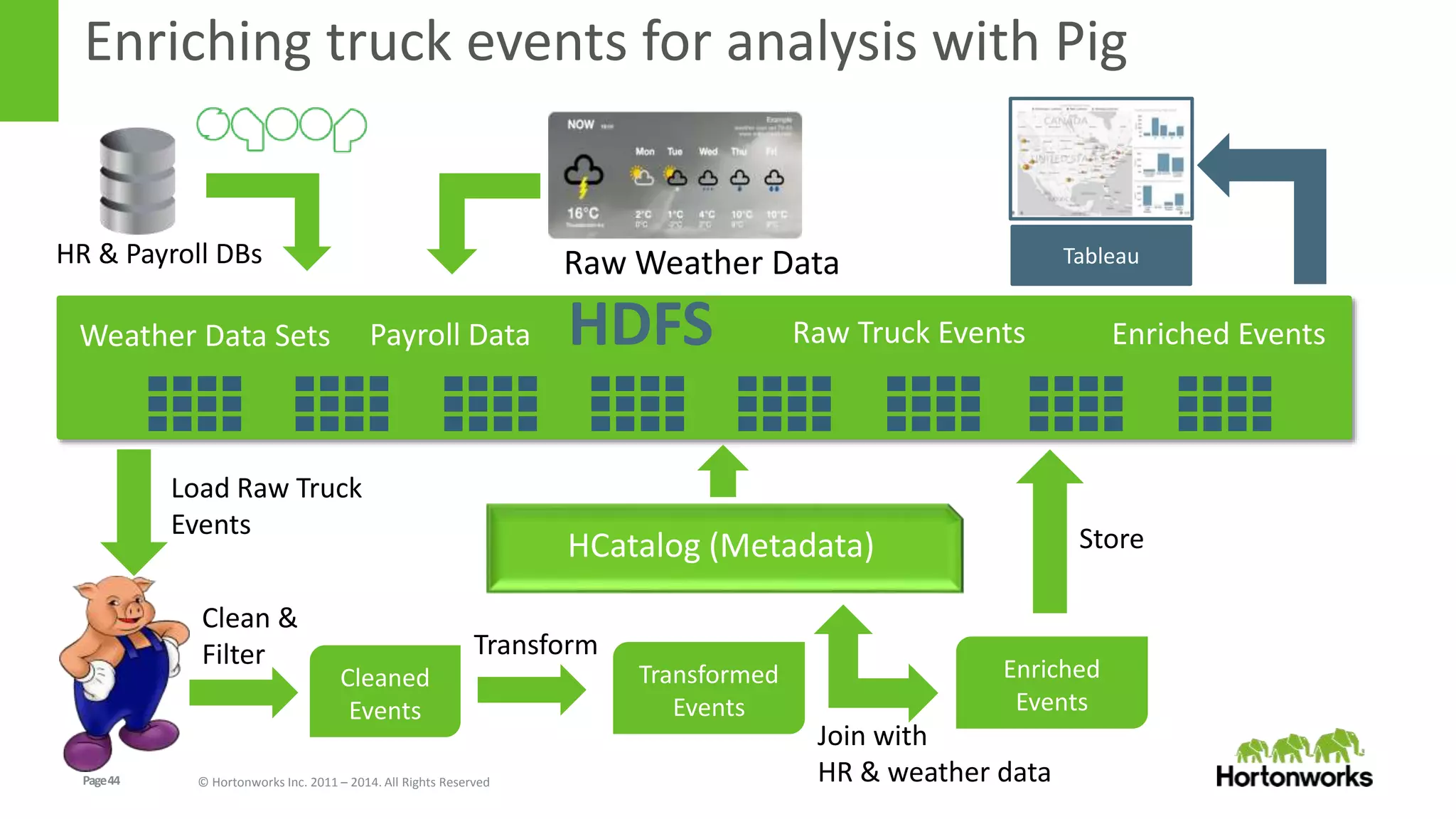
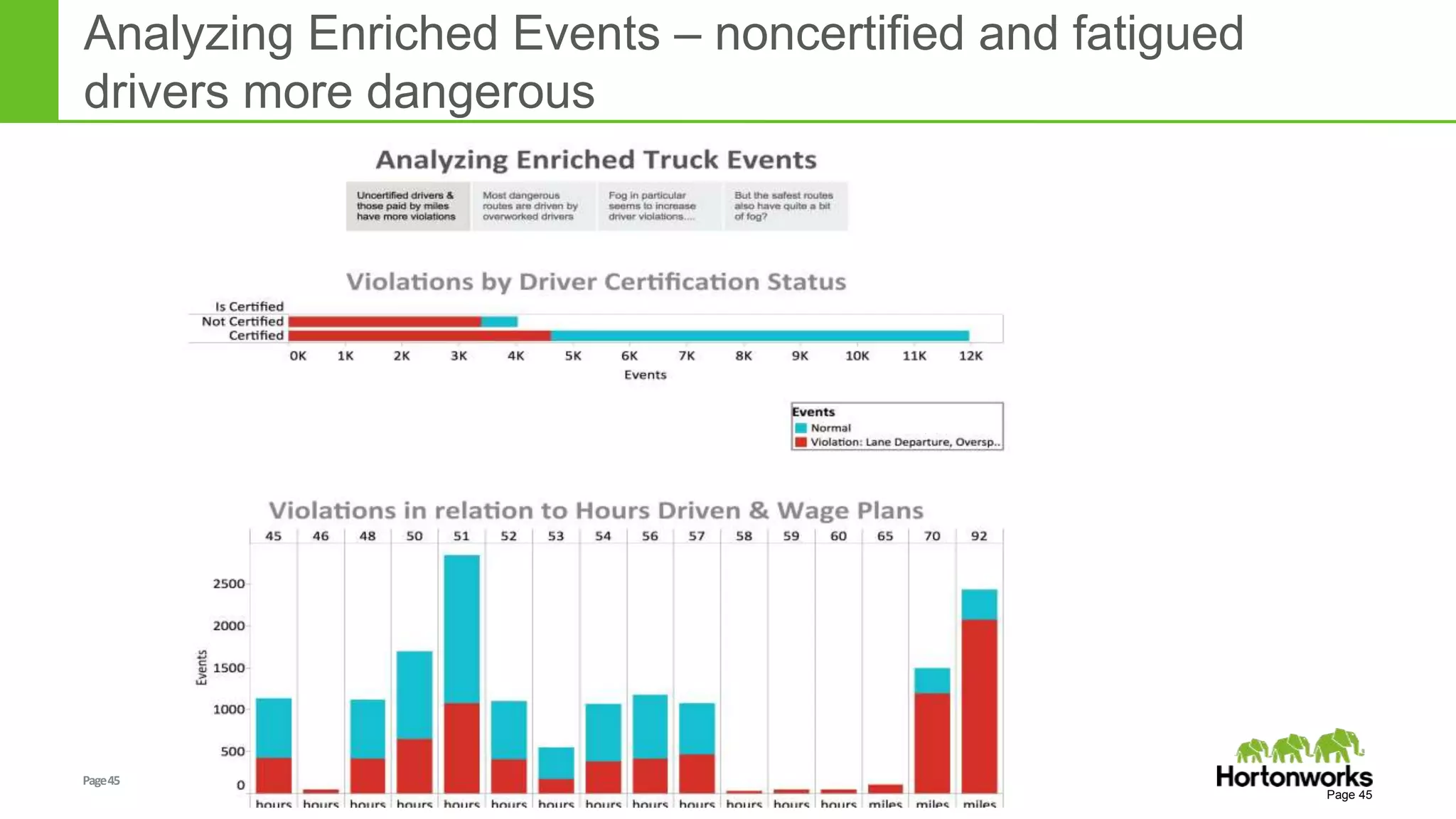
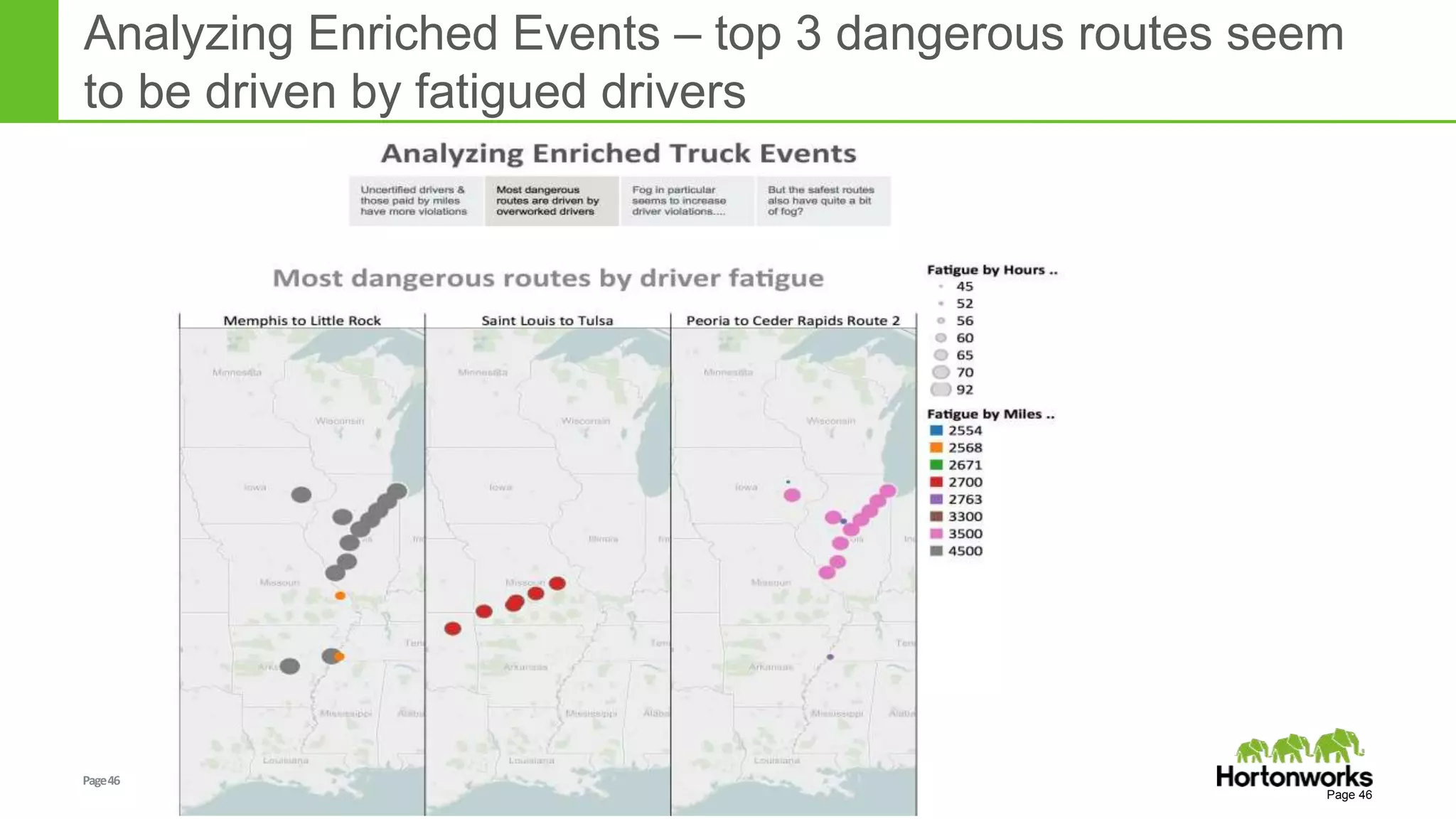
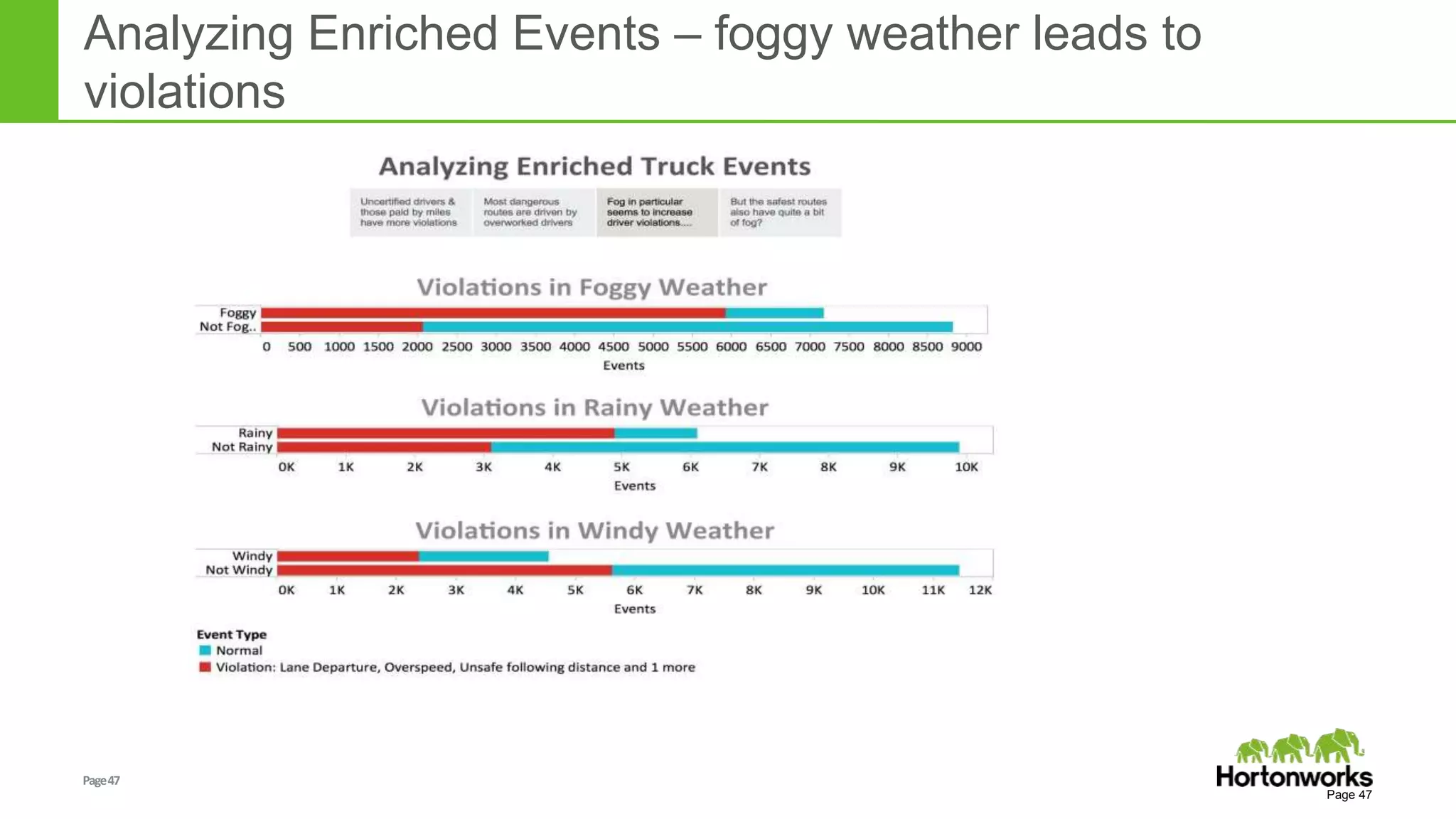
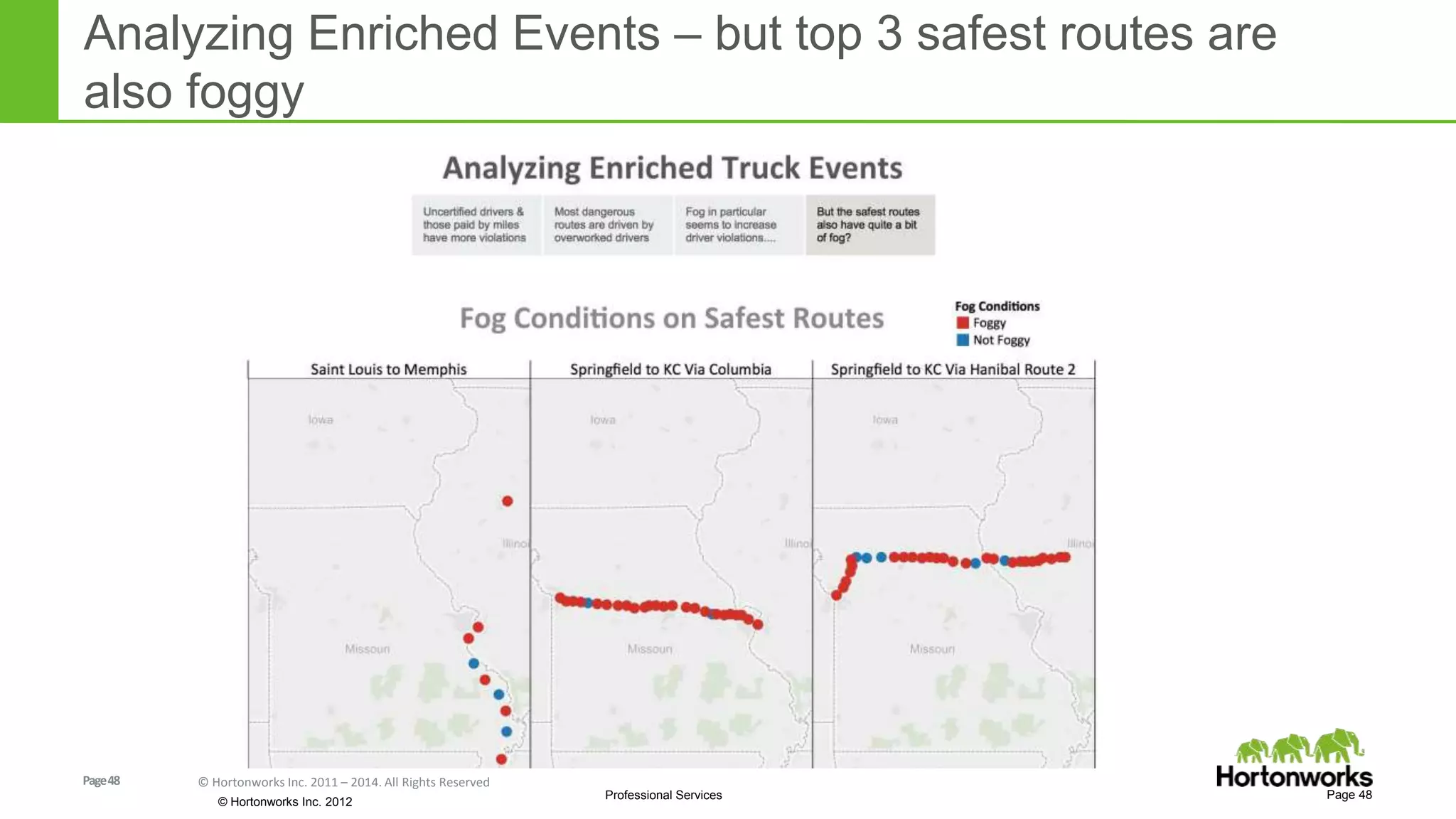
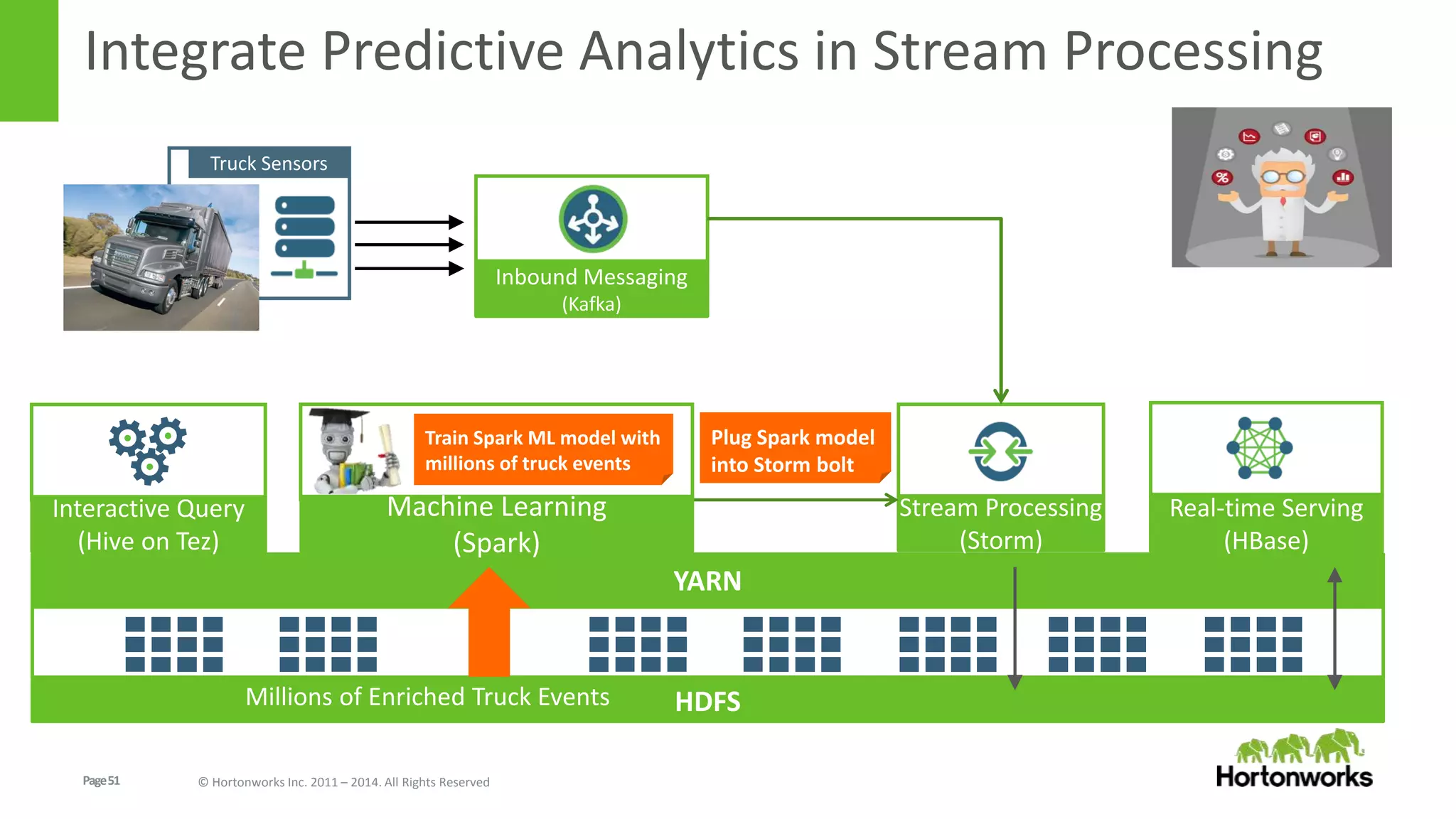
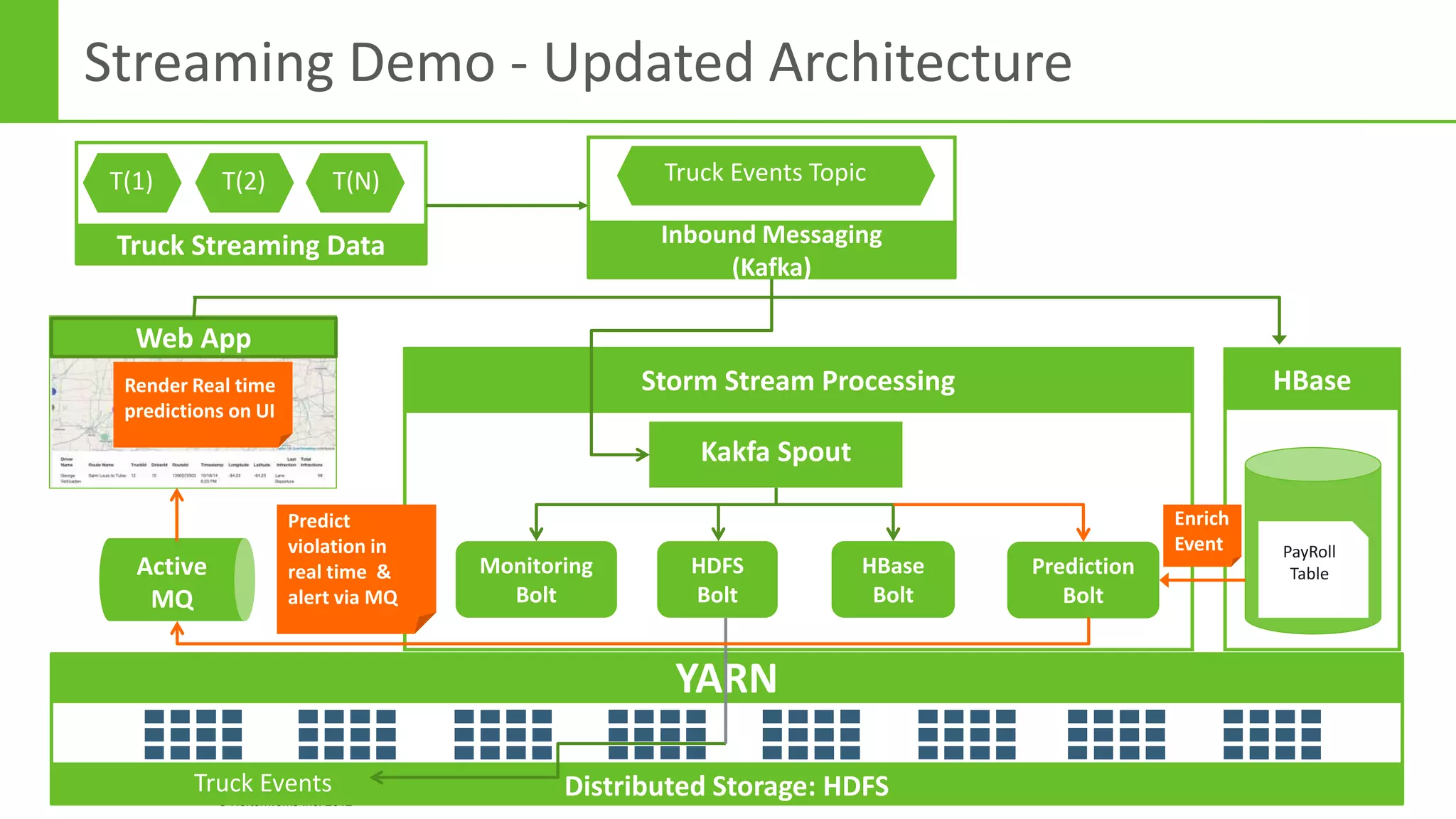
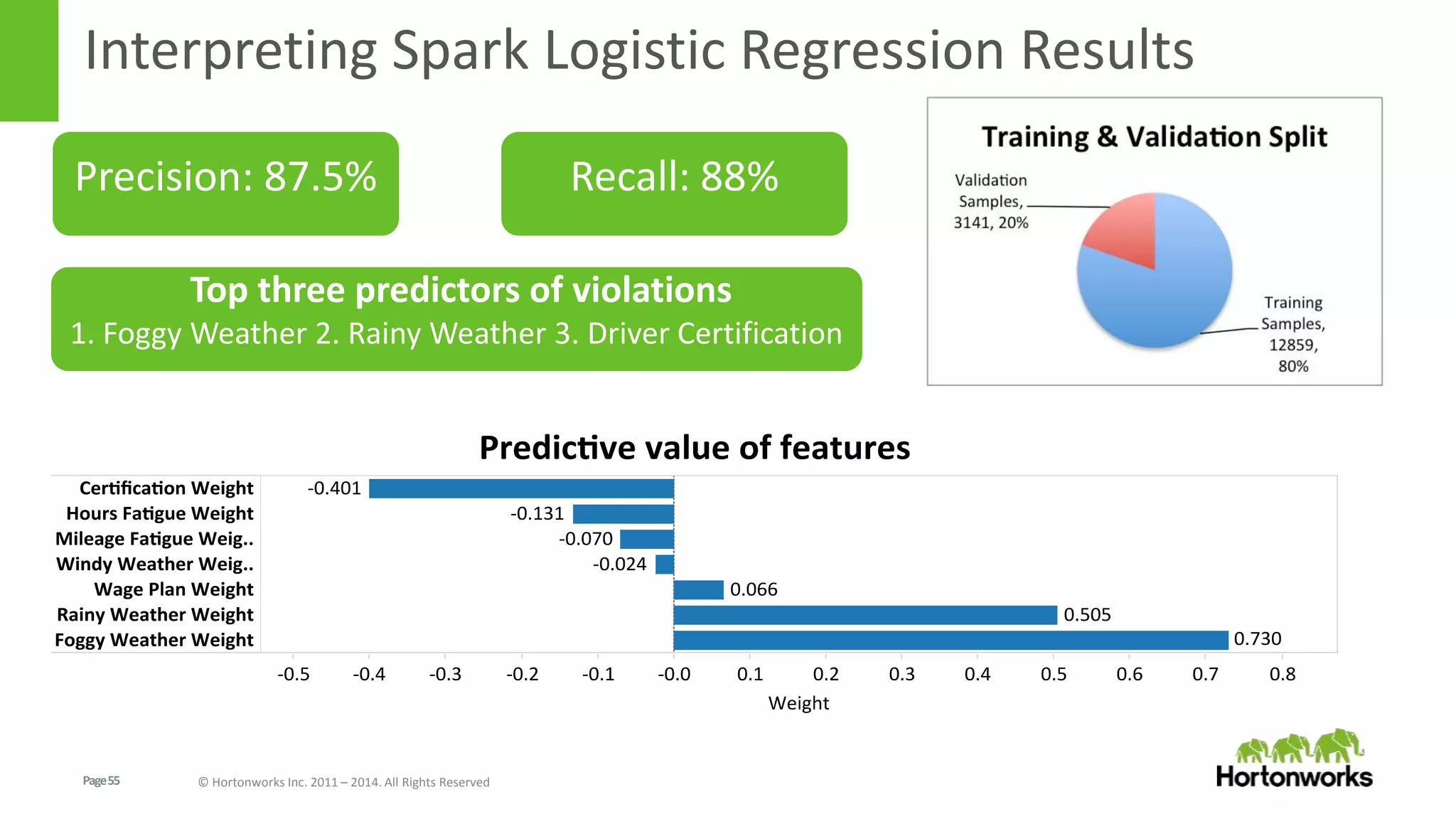
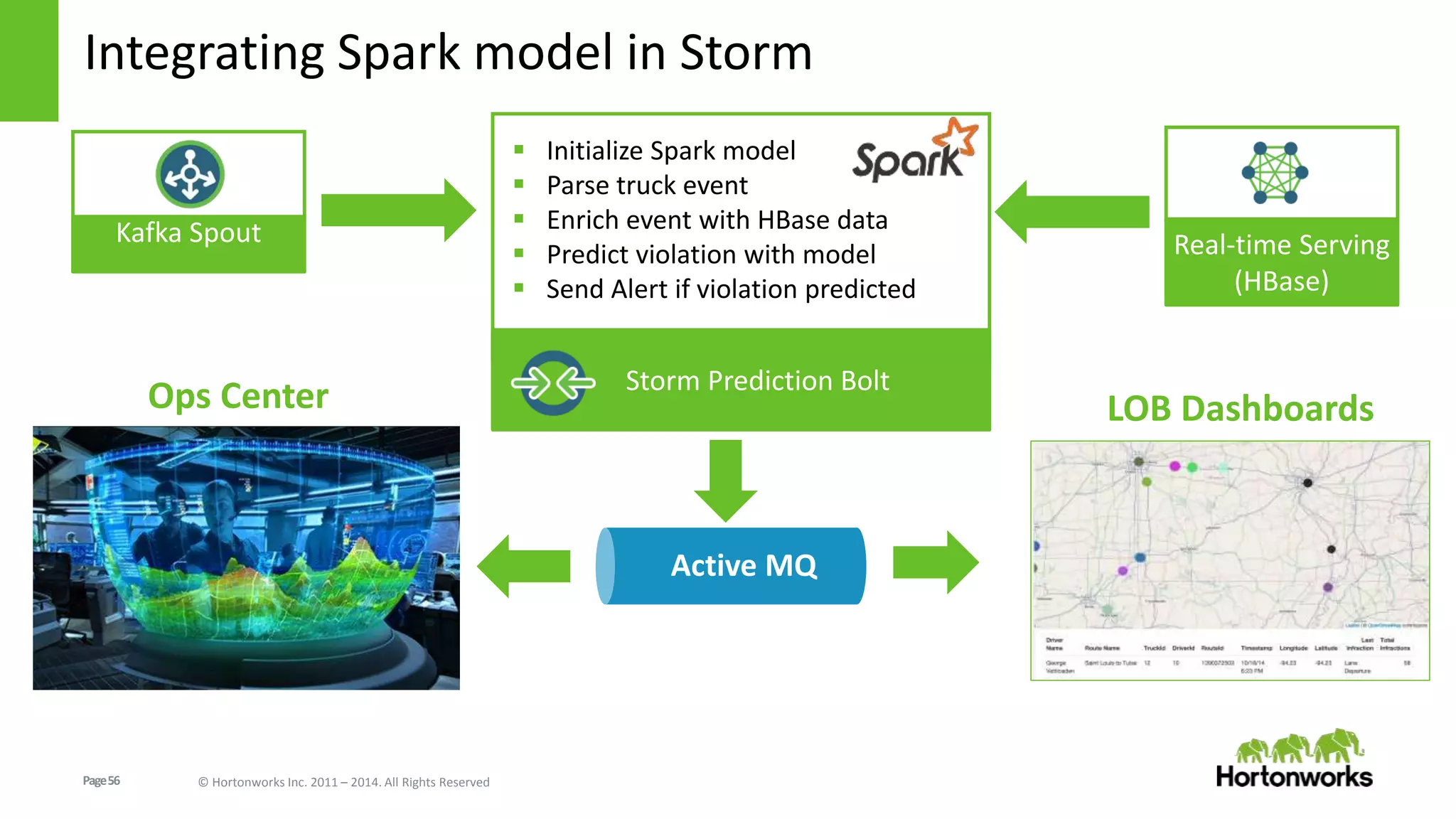
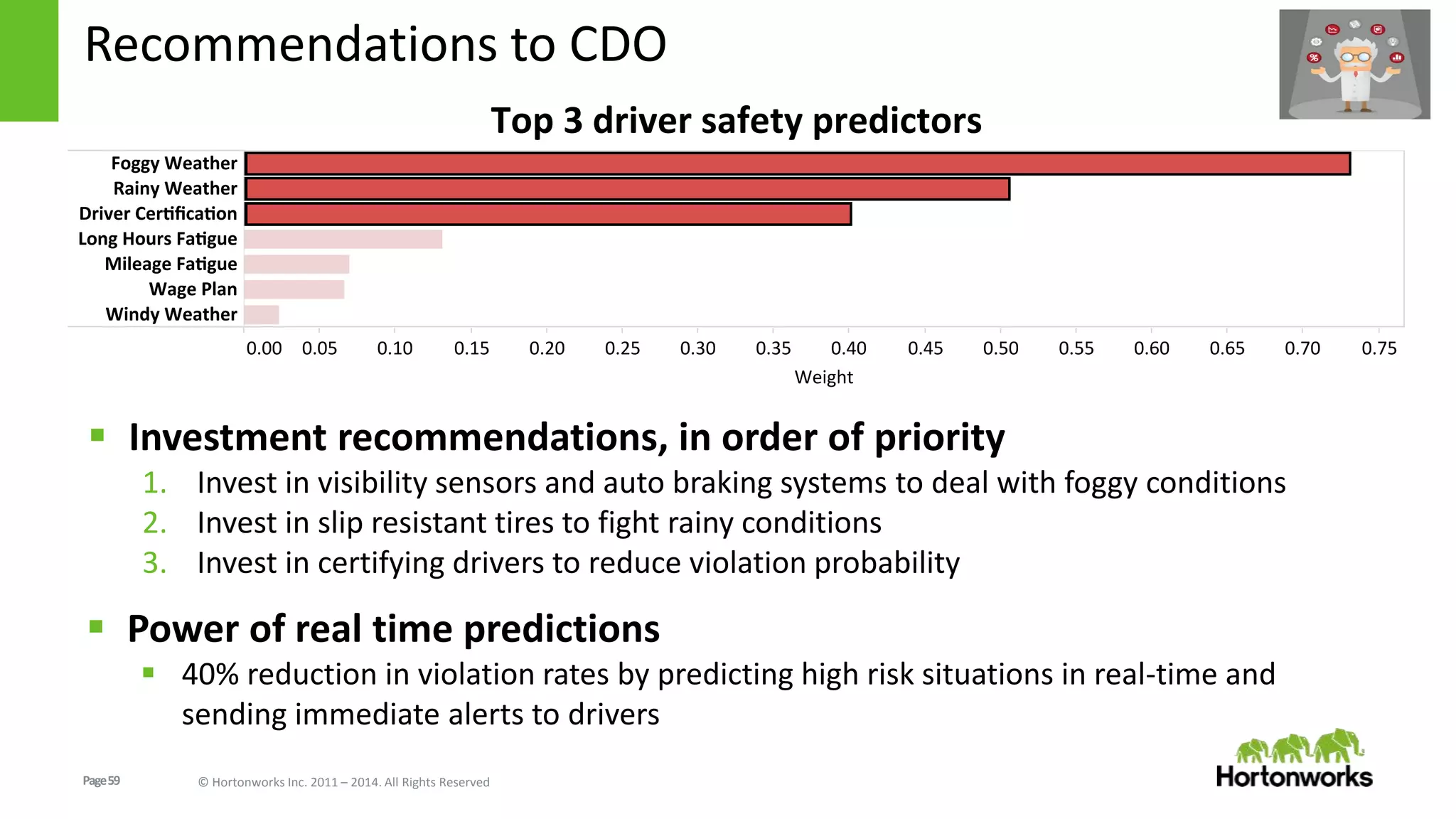
The document discusses real-time processing in Hadoop using the Hortonworks Data Platform (HDP). It provides an overview of using HDP for real-time streaming analytics in a logistics scenario. Example applications and architectures are presented, including using Kafka for ingesting sensor data, Storm for stream processing, and HBase for real-time querying. Demos will also illustrate integrating predictive analytics into streaming scenarios.