7
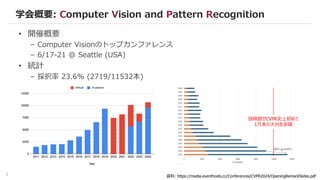
• タイトルに含まれる単語のなかで2023年比での増減を比較
Keyword増減比較
増加数 2024> 2023
+192 diffusion
+181 models
+101 generation
+99 3d
+81 model
+60 large
+46 multimodal
+45 human
+42 text-to-image
+40 language
減少数 2024 < 2023
-87 learning
-39 deep
-36 neural
-34 object
-32 masked
-30 contrastive
-29 self-supervised
-25 recognition
-23 detection
-22 transformer
生成AI / 3D / 基盤モデル関連が
ホットトピック
去年話題だったMasked Autoencoderなどの
自己教師あり学習がダウントレンド
9.
8
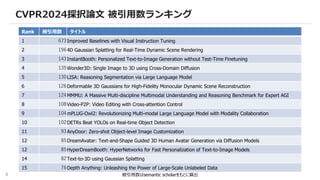
CVPR2024採択論文 被引用数ランキング
被引用数はsemantic scholarをもとに算出
Rank被引用数 タイトル
1 673Improved Baselines with Visual Instruction Tuning
2 1964D Gaussian Splatting for Real-Time Dynamic Scene Rendering
3 143InstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning
4 135Wonder3D: Single Image to 3D using Cross-Domain Diffusion
5 130LISA: Reasoning Segmentation via Large Language Model
6 126Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
7 124MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
8 108Video-P2P: Video Editing with Cross-attention Control
9 104mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
10 102DETRs Beat YOLOs on Real-time Object Detection
11 93AnyDoor: Zero-shot Object-level Image Customization
12 85DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models
12 85HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
14 82Text-to-3D using Gaussian Splatting
15 76Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
10.
9
CVPR2024採択論文 被引用数ランキング
被引用数はsemantic scholarをもとに算出
Rank被引用数 タイトル
1 673Improved Baselines with Visual Instruction Tuning
2 1964D Gaussian Splatting for Real-Time Dynamic Scene Rendering
3 143InstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning
4 135Wonder3D: Single Image to 3D using Cross-Domain Diffusion
5 130LISA: Reasoning Segmentation via Large Language Model
6 126Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
7 124MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
8 108Video-P2P: Video Editing with Cross-attention Control
9 104mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
10 102DETRs Beat YOLOs on Real-time Object Detection
11 93AnyDoor: Zero-shot Object-level Image Customization
12 85DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models
12 85HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
14 82Text-to-3D using Gaussian Splatting
15 76Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
認識系の基盤モデルについての論文が注目を集める
11.
10
CVPR2024採択論文 被引用数ランキング
被引用数はsemantic scholarをもとに算出
Rank被引用数 タイトル
1 673Improved Baselines with Visual Instruction Tuning
2 1964D Gaussian Splatting for Real-Time Dynamic Scene Rendering
3 143InstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning
4 135Wonder3D: Single Image to 3D using Cross-Domain Diffusion
5 130LISA: Reasoning Segmentation via Large Language Model
6 126Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
7 124MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
8 108Video-P2P: Video Editing with Cross-attention Control
9 104mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
10 102DETRs Beat YOLOs on Real-time Object Detection
11 93AnyDoor: Zero-shot Object-level Image Customization
12 85DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models
12 85HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
14 82Text-to-3D using Gaussian Splatting
15 76Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
早くも3D Gaussian Splattingの後継研究が活性化
12.
11
CVPR2024採択論文で引用された過去論文 被引用数ランキング
被引用数はsemantic scholarをもとに算出
Rank被引用数 タイトル
1 523 Learning Transferable Visual Models From Natural Language Supervision (2021)
2 385 High-Resolution Image Synthesis with Latent Diffusion Models (2021)
3 362 Deep Residual Learning for Image Recognition (2015)
4 312 Denoising Diffusion Probabilistic Models (2020)
5 309 Attention is All you Need (2017)
6 285 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020)
7 219 Microsoft COCO: Common Objects in Context (2014)
8 206 Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (2022)
9 201 Denoising Diffusion Implicit Models (2020)
10 191 Hierarchical Text-Conditional Image Generation with CLIP Latents (2022)
11 180 The Unreasonable Effectiveness of Deep Features as a Perceptual Metric (2018)
12 172 Adding Conditional Control to Text-to-Image Diffusion Models (2023)
13 156 NeRF (2020)
14 155 Diffusion Models Beat GANs on Image Synthesis (2021)
15 153 Segment Anything (2023)
13.
12
CVPR2024採択論文で引用された過去論文 被引用数ランキング
被引用数はsemantic scholarをもとに算出
Rank被引用数 タイトル
1 523 Learning Transferable Visual Models From Natural Language Supervision (2021)
2 385 High-Resolution Image Synthesis with Latent Diffusion Models (2021)
3 362 Deep Residual Learning for Image Recognition (2015)
4 312 Denoising Diffusion Probabilistic Models (2020)
5 309 Attention is All you Need (2017)
6 285 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020)
7 219 Microsoft COCO: Common Objects in Context (2014)
8 206 Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (2022)
9 201 Denoising Diffusion Implicit Models (2020)
10 191 Hierarchical Text-Conditional Image Generation with CLIP Latents (2022)
11 180 The Unreasonable Effectiveness of Deep Features as a Perceptual Metric (2018)
12 172 Adding Conditional Control to Text-to-Image Diffusion Models (2023)
13 156 NeRF (2020)
14 155 Diffusion Models Beat GANs on Image Synthesis (2021)
15 153 Segment Anything (2023)
引き続き生成AI系の論文が上位を占める
14.
13
CVPR2024採択論文で引用された過去論文 被引用数ランキング
被引用数はsemantic scholarをもとに算出
Rank被引用数 タイトル
1 523 Learning Transferable Visual Models From Natural Language Supervision (2021)
2 385 High-Resolution Image Synthesis with Latent Diffusion Models (2021)
3 362 Deep Residual Learning for Image Recognition (2015)
4 312 Denoising Diffusion Probabilistic Models (2020)
5 309 Attention is All you Need (2017)
6 285 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020)
7 219 Microsoft COCO: Common Objects in Context (2014)
8 206 Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (2022)
9 201 Denoising Diffusion Implicit Models (2020)
10 191 Hierarchical Text-Conditional Image Generation with CLIP Latents (2022)
11 180 The Unreasonable Effectiveness of Deep Features as a Perceptual Metric (2018)
12 172 Adding Conditional Control to Text-to-Image Diffusion Models (2023)
13 156 NeRF (2020)
14 155 Diffusion Models Beat GANs on Image Synthesis (2021)
15 153 Segment Anything (2023)
去年出たControlNet / SAMがすでに数多くの論文で引用されている
15.
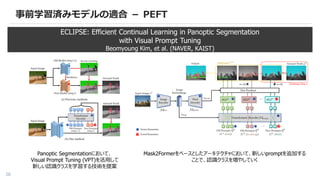
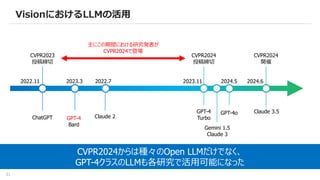
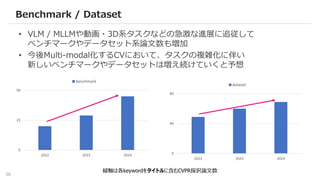
基盤モデル動向
– VLM /MLLM 系基盤モデル v2
– 事前学習済みモデルの活用 - CLIP / DINOv2 / SAM
– 事前学習済みモデルの適合 - PEFT / Training-free
– VisionにおけるLLMの活用
– Diffusion model for X
– Benchmark / Dataset
16.
15
VLM / MLLM系基盤モデル“v2”
去年大々的に登場した各企業・各大学の
Vision Language Model (VLM)やMulti-modal Large Language Model (MLLM)の
“version 2”が今年続々と登場
17.
16
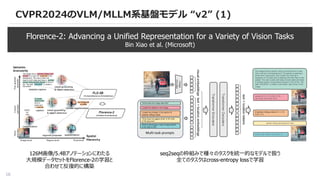
CVPR2024のVLM/MLLM系基盤モデル “v2” (1)
Florence-2:Advancing a Unified Representation for a Variety of Vision Tasks
Bin Xiao et al. (Microsoft)
126M画像/5.4Bアノテーションにわたる
大規模データセットをFlorence-2の学習と
合わせて反復的に構築
seq2seqの枠組みで種々のタスクを統一的なモデルで扱う
全てのタスクはcross-entropy lossで学習
18.
17
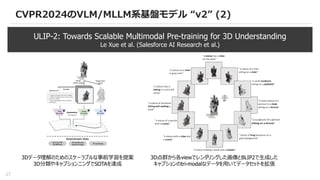
CVPR2024のVLM/MLLM系基盤モデル “v2” (2)
ULIP-2:Towards Scalable Multimodal Pre-training for 3D Understanding
Le Xue et al. (Salesforce AI Research et al.)
3Dデータ理解のためのスケーラブルな事前学習を提案
3D分類やキャプションニングでSOTAを達成
3D点群から各viewでレンダリングした画像とBLIP2で生成した
キャプションのtri-modalなデータを用いてデータセットを拡張
19.
18
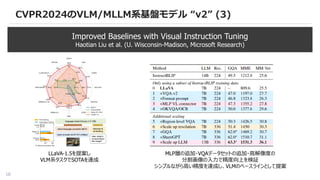
CVPR2024のVLM/MLLM系基盤モデル “v2” (3)
ImprovedBaselines with Visual Instruction Tuning
Haotian Liu et al. (U. Wisconsin-Madison, Microsoft Research)
LLaVA-1.5を提案し
VLM系タスクでSOTAを達成
MLP層の追加・VQAデータセットの追加・高解像度の
分割画像の入力で精度向上を検証
シンプルながら高い精度を達成し、VLMのベースラインとして提案
20.
19
• VizWiz workshopにて
–GPT4Vの説明 / GPT-4oのデモが実施された
https://x.com/ai_for_success/status/1803234410835361903
• Workshop on Transformers for Visionにて
– キャパ200%の会場でSoraの説明が実施された
https://x.com/Mascobot/status/1802754729942057068
OpenAIからの発表 in workshop
Lesson from LLMs (抜粋)
To adapt models for specific tasks, use data not architecture changes
(特定のタスクに適応するために、アーキの変更ではなくデータを使え)
21.
20
事前学習済みモデルの活用 - CLIP/ DINOv2 / SAM
[1] Alec Radford et al., “Learning Transferable Visual Models From Natural Language Supervision”, ICML, 2021.
[2] Maxime Oquab et al., “DINOv2: Learning Robust Visual Features without Supervision”, TMLR, 2024.
[3] Alexander Kirillov et al., “Segment Anything”, ICCV, 2023.
CLIP (1位/523本) DINOv2 (59位/67本) SAM (15位/153本)
Vision-Languageの統合
タスクのopen-vocabulary化
Semantic Alignされた
見えの変化に頑健な画像特徴量
セグメンテーションタスクの
ベースモデル
※ ()内はCVPR2024論文内での引用ランク/引用数
22.
21
事前学習済みモデルの活用 - CLIP(1)
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
Zeyi Sun, et al. (Shanghai Jiao Tong University et al.)
CLIPにalphaチャンネルを入力できるように拡張して、
RGBA-textペアの画像で学習
推論時にユーザが前景などの領域を指定できるようになり、
背景に惑わされない頑健な認識を実現
既存のデータセットに対してSAMやBLIPでマスクやキャプションを
付与することで、RGBA-textペア画像を生成して学習する
23.
22
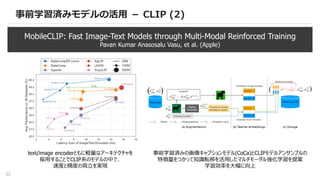
事前学習済みモデルの活用 - CLIP(2)
MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
Pavan Kumar Anasosalu Vasu, et al. (Apple)
text/image encoderともに軽量なアーキテクチャを
採用することでCLIP系のモデルの中で、
速度と精度の両立を実現
事前学習済みの画像キャプションモデル(CoCa)とCLIPモデルアンサンブルの
特徴量をつかって知識転移を活用したマルチモーダル強化学習を提案
学習効率を大幅に向上
24.
23
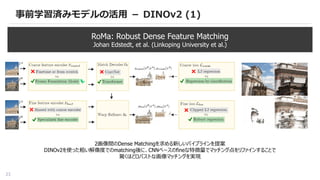
事前学習済みモデルの活用 - DINOv2(1)
RoMa: Robust Dense Feature Matching
Johan Edstedt, et al. (Linkoping University et al.)
2画像間のDense Matchingを求める新しいパイプラインを提案
DINOv2を使った粗い解像度でのmatching後に、CNNベースのfineな特徴量でマッチング点をリファインすることで
驚くほどロバストな画像マッチングを実現
25.
24
事前学習済みモデルの活用 - DINOv2(2)
NeRF On-the-go: Exploiting Uncertainty for Distractor-free NeRFs in the Wild
Weining Ren, et al. (ETH Zurich et al.)
動物体や影などの外乱要素が映るシーンでも
NeRFでロバストにView合成ができる手法を提案
DINOv2は異なるviewでも空間・時間的に一貫した特徴を捉えるため、
撮影対象なのか、外乱要素なのかを区別できる
DINOv2特徴量を用いて、画像の不確からしさを予測
その予測に基づいてNeRFを学習することで、外乱領域を
効果的に無視することができる
26.
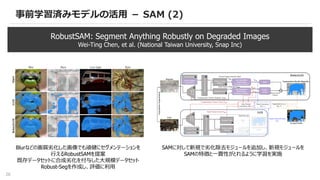
25
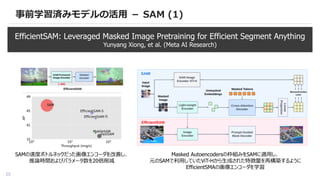
事前学習済みモデルの活用 - SAM(1)
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Yunyang Xiong, et al. (Meta AI Research)
SAMの速度ボトルネックだった画像エンコーダを改善し、
推論時間およびパラメータ数を20倍削減
Masked Autoencodersの枠組みをSAMに適用し、
元のSAMで利用していたViT-Hから生成された特徴量を再構築するように
EfficientSMAの画像エンコーダを学習
32
CVPR2024におけるVisionにおけるLLMの活用 (1)
Language Modelsas Black-Box Optimizers for Vision-Language Models
Shihong Liu, et al. (Carnegie Mellon University)
ChatベースのLLM (GPT3.5/4)に初期のプロンプトとその評価結果を
与えて、よりよいプロンプトをLLMに想起させる
画像分類タスクにおいて、通常のプロンプトなどよりも高い精度を達成
T2Iタスクにおいては、GPT4Vを利用して、生成した画像が
適切かどうかを判定し、プロンプトの改善を実施する
34.
33
CVPR2024におけるVisionにおけるLLMの活用 (2)
LocLLM: ExploitingGeneralizable Human Keypoint Localization
via Large Language Model
Dongkai Wang, et al. (Peking University)
LLM (vicuna-7B)に対して、画像特徴量をプロンプトとして追加し、LoRAでfinetuneすることで、
textベースで人のkeypointsを予測させることに成功
35.
34
Diffusion Model forX
画像出力系タスク[3] Downstreamタスク[4] 学習データ生成[5]
text-to-image[1] text/image-to-3D[2]
[1] Jing Shi Ke et al., “InstantBooth: Personalized Text-to-Image
Generation without Test-Time Finetuning”, CVPR, 2024.
[2] Minghua Liu et al., “One-2-3-45++: Fast Single Image to 3D Objects
with Consistent Multi-View Generation and 3D Diffusion”, CVPR, 2024.
[3] Bingxin Ke et al., “Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation”,
CVPR, 2024.
[4] Zigang Geng et al., “InstructDiffusion: A Generalist Modeling Interface for Vision Tasks”, CVPR, 2024.
[5] Fan Zhang et al., “Atlantis: Enabling Underwater Depth Estimation with Stable Diffusion”, CVPR, 2024.
36.
35
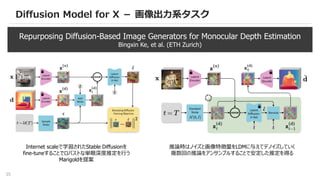
Diffusion Model forX - 画像出力系タスク
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Bingxin Ke, et al. (ETH Zurich)
Internet scaleで学習されたStable Diffusionを
fine-tuneすることでロバストな単眼深度推定を行う
Marigoldを提案
推論時はノイズと画像特徴量をLDMに与えてデノイズしていく
複数回の推論をアンサンブルすることで安定した推定を得る
37.
36
Diffusion Model forX - Downstreamタスク
InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
Zigang Geng, et al. (Microsoft Research Asia)
「keypointを黄色の円で塗りつぶせ」のようなinstructを与えることで
diffusion modelでもdownstream系のタスクをimg2imgの枠組みで
実現できることを示した
円やbounding boxを生成できるように
事前学習で適合させたのち、タスク固有の学習で
instructionを教えて、Human alignmentで微調整を実施
38.
37
Diffusion Model forX - 学習データ生成
Atlantis: Enabling Underwater Depth Estimation with Stable Diffusion
Fan Zhang, et al. (Beijing Institute of Technology et al.)
既存のDepth推定器(MiDaS)とVLM(BLIP2)を用いて、海中画像と
その深度画像、キャプションのデータセットを作成し、
Stable Diffusion + ControlNetでDepth+キャプションから海中画像を
生成するようにfine-tuneする
陸上のデプスデータセットから海中画像を生成し、
そのデータセットで学習することで、
陸上海中のドメインギャップに対して
汎化できることを示した
3D Vision動向
– 3D生成モデル
– 単眼Depth推定
– 3D Gaussian Splatting
– 3D Visionにおけるunified model - DUSt3R / MASt3R
44.
43
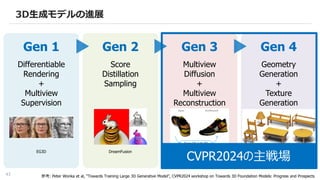
3D生成モデルの進展
参考: Peter Wonkaet al, “Towards Training Large 3D Generative Model”, CVPR2024 workshop on Towards 3D Foundation Models: Progress and Prospects
Gen 1 Gen 2 Gen 3 Gen 4
Differentiable
Rendering
+
Multiview
Supervision
Score
Distillation
Sampling
Multiview
Diffusion
+
Multiview
Reconstruction
Geometry
Generation
+
Texture
Generation
EG3D DreamFusion Zero-1-to-3 MeshGPT
CVPR2024の主戦場
45.
44
3D生成モデルの進展 - Gen1 to Gen 2
Gen 1
Diffentiable Rendering
+ Multiview Supervision
[1] Eric R. Chan et al., “Efficient Geometry-aware 3D Generative Adversarial Networks”, CVPR, 2022.
[2] Ben Poole et al., “DreamFusion: Text-to-3D using 2D Diffusion”, ICLR, 2023.
可微分レンダラを学習の系に組み込み
入力画像との再構築誤差で学習
3D教師データが不要で学習可能
3D geometryにノイズが多い
Gen 2
Score Distillation Sampling
diffusion modelを利用して
NeRFの3D表現を最適化
3D教師データが不要で学習可能
低速・Janus問題
Janus問題
46.
45
3D生成モデルの進展 - Gen3 to Gen 4
Gen 3
Multiview Diffusion
+ Multiview Reconstruction
Gen 4
Geometry Generation
+ Texture Generation
[1] Ruoshi Liu et al., “Zero-1-to-3: Zero-shot One Image to 3D Object”, ICCV, 2023.
[2] Xuanchi Ren et al., “XCube: Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies”, CVPR, 2024.
Multiview制約をdiffusion modelに
組み込むことで頑健性向上
Janus-free, 高速な推論
大規模なMultiviewデータセット必要
3次元点群やmeshを直接推論
高速な推論, 事前学習済みモデル不要
大規模な3Dデータセット必要
47.
46
Gen 3やGen 4を支える大規模3Dデータセット
Objaverse(2023)
10M+の3D object dataset
MVImgNet (2023)
6.2MのMulti-view dataset
[1] Matt Deitke et al., “Objaverse-XL: A Universe of 10M+ 3D Objects”, arxiv, 2023.
[2] Xianggang Yu et al., “MVImgNet: A Large-scale Dataset of Multi-view Images”, CVPR, 2023.
3Dのドメインでも巨大データセットxシンプルなモデルで直接推論できる時代になってきた
48.
47
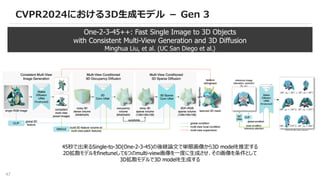
CVPR2024における3D生成モデル - Gen3
One-2-3-45++: Fast Single Image to 3D Objects
with Consistent Multi-View Generation and 3D Diffusion
Minghua Liu, et al. (UC San Diego et al.)
45秒で出来るSingle-to-3D(One-2-3-45)の後継論文で単眼画像から3D modelを推定する
2D拡散モデルをfinetuneして6つのmulti-view画像を一度に生成させ、その画像を条件として
3D拡散モデルで3D modelを生成する
49.
48
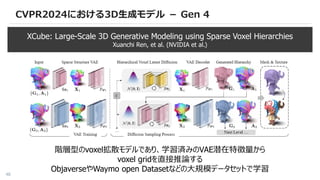
CVPR2024における3D生成モデル - Gen4
XCube: Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies
Xuanchi Ren, et al. (NVIDIA et al.)
階層型のvoxel拡散モデルであり、学習済みのVAE潜在特徴量から
voxel gridを直接推論する
ObjaverseやWaymo open Datasetなどの大規模データセットで学習
50
単眼相対Depth推定(RDE)の進展
SfMLearner (2017)
各データセットごとに学習
[1] TinghuiZhou et al., “Unsupervised Learning of Depth and Ego-Motion from Video”, CVPR, 2017.
[2] René Ranftl et al., “Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer”, TPAMI, 2020.
[3] Lihe Yang et al., “Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data”, CVPR, 2024.
MiDaS (2020)
複合データセットで学習
DepthAnything (2024)
Internet-scaleで学習
RDEでは学習できるデータセットをスケールさせることで汎化性を高めてきた
52
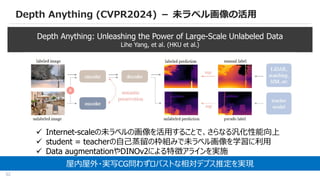
Depth Anything (CVPR2024)- 未ラベル画像の活用
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Lihe Yang, et al. (HKU et al.)
Internet-scaleの未ラベルの画像を活用することで、さらなる汎化性能向上
student = teacherの自己蒸留の枠組みで未ラベル画像を学習に利用
Data augmentationやDINOv2による特徴アラインを実施
屋内屋外・実写CG問わずロバストな相対デプス推定を実現
54.
53
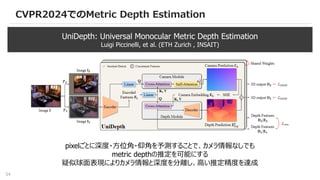
単眼メトリックDepth推定(MDE)の進展
ZoeDepth (2023)
[1] ShariqFarooq Bhat et al., “ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth”, arxiv, 2023.
[2] Wei Yin et al., “Metric3D: Towards Zero-shot Metric 3D Prediction from A Single Image”, arxiv, 2023.
Metric3D (2023)
相対Depth推定器の進展に底上げされてメトリック推定も汎化性が大幅に向上
metric depth推定用のLUTを学習し
分類問題として推定する
カメラの内部パラメータをつかった
変換・逆変換で相対デプスから絶対デプス
に変換
55
3D Gaussian Splattingの進展
0
50
100
150
20222023 2024
NeRF 3D Gaussian Splatting
[1] Bernhard Kerbl et al., “3D Gaussian Splatting for Real-Time Radiance Field Rendering”, SIGGRAPH, 2023.
NVSでの
定常進化
3D生成AIでの
利用
Offline
3Dシーン再構築
Online
3Dシーン再構築
(SLAM)
CVPR2024で見られた進展
57.
56
3D Gaussian Splattingの進展- NVSでの定常進化
Mip-Splatting: Alias-free 3D Gaussian Splatting
Zehao Yu, et al. (University of Tubingen et al.)
4D Gaussian Splatting for Real-Time Dynamic
Scene Rendering
Guanjun Wu, et al. (HUST et al.)
Zoom時のエイリアス問題を3D平滑化フィルタと
2D Mipフィルタを導入することで解決
様々なスケールで高品質なレンダリングを実現
3Dガウス分布と4Dニューラルボクセルを用いて、
動的シーンの形状と時間変化を正確にモデル化
高品質な動的シーンレンダリングをリアルタイムに実現
※NVS: Novel View Synthesis
NeRFと同様の進化を3DGS版で焼き直す
58.
57
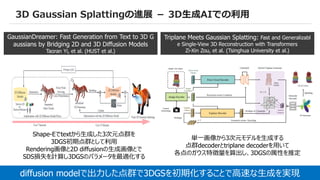
3D Gaussian Splattingの進展- 3D生成AIでの利用
GaussianDreamer: Fast Generation from Text to 3D G
aussians by Bridging 2D and 3D Diffusion Models
Taoran Yi, et al. (HUST et al.)
Triplane Meets Gaussian Splatting: Fast and Generalizabl
e Single-View 3D Reconstruction with Transformers
Zi-Xin Zou, et al. (Tsinghua University et al.)
Shape-Eでtextから生成した3次元点群を
3DGS初期点群として利用
Rendering画像と2D diffusionの生成画像とで
SDS損失を計算し3DGSのパラメータを最適化する
単一画像から3次元モデルを生成する
点群decoderとtriplane decoderを用いて
各点のガウス特徴量を算出し、3DGSの属性を推定
diffusion modelで出力した点群で3DGSを初期化することで高速な生成を実現
59.
58
3D Gaussian Splattingの進展- Offline 3Dシーン再構築
SuGaR: Surface-Aligned Gaussian Splatting forEfficient 3D Mes
h Reconstruction and High-Quality Mesh Rendering
Antoine Guedon, et al. (LIGM)
COLMAP-Free 3D Gaussian Splatting
Yang Fu, et al. (UC San Deigo et al.)
3DGSの苦手 (surfaceが汚い)を克服することでMesh復元などにも活用可能
3D Gaussianの表面アラインを促進する
ロス関数を導入することで、3DGSのsurfaceを整える
ガウス分布とメッシュを同時に最適化することで
高品質なメッシュを構築
2view間で単眼Depth推定結果に基づいて3DGSを生成
推定したLocal 3DGSをGlobal空間に蓄積していくことで
COLMAP-freeな3次元復元を実現
60.
59
3D Gaussian Splattingの進展- Online 3Dシーン再構築 (SLAM)
Gaussian Splatting SLAM
Hidenobu Matsuki, et al. (Imperial College London)
3DGSの高速なレンダリングとSLAMは相性が良く、同テーマで複数本発表
RGBカメラのみの入力で3DGSのmapを作成しながらカメラトラッキングを実現
3DGSのレンダリングロスでposeとmapを最適化していく
球面調和関数を保持しないことで高速かつ軽量なmappingを実現
61
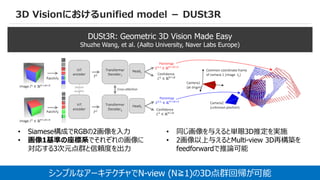
3D Visionにおけるunified model- DUSt3R
DUSt3R: Geometric 3D Vision Made Easy
Shuzhe Wang, et al. (Aalto University, Naver Labs Europe)
• Siamese構成でRGBの2画像を入力
• 画像1基準の座標系でそれぞれの画像に
対応する3次元点群と信頼度を出力
• 同じ画像を与えると単眼3D推定を実施
• 2画像以上与えるとMulti-view 3D再構築を
feedforwardで推論可能
シンプルなアーキテクチャでN-view (N≧1)の3D点群回帰が可能
63.
62
3D Visionにおけるunified model- DUSt3R
DUSt3R: Geometric 3D Vision Made Easy
Shuzhe Wang, et al. (Aalto University, Naver Labs Europe)
3D Vision領域における初めてのUnified Modelとして期待を集める
3次元点群を出力しているため、単眼・複眼両方の多様な3D Visionの
問題が統一的なモデルで扱える
64.
63
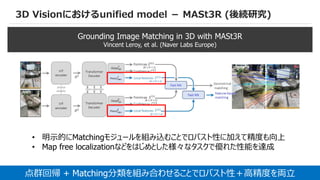
3D Visionにおけるunified model- MASt3R (後続研究)
Grounding Image Matching in 3D with MASt3R
Vincent Leroy, et al. (Naver Labs Europe)
点群回帰 + Matching分類を組み合わせることでロバスト性+高精度を両立
• 明示的にMatchingモジュールを組み込むことでロバスト性に加えて精度も向上
• Map free localizationなどをはじめとした様々なタスクで優れた性能を達成
65.
64
• 3D生成モデルの進展
– 大規模3Dデータセットの登場で直接推論が可能
•単眼Depth推定の進展
– Internet scaleでの学習によりロバスト性向上
• 3D Gaussian Splattingの進展
– NeRFを上回る急速な進展
• 3D Visionにおけるunified model
– DUSt3R / MASt3Rについて紹介
3D Vision動向まとめ
66.
65
• 学会トレンド
– 生成AIが最大ホットトピック
–3D Gaussian SplattingやFoundation modelが急成長
• 基盤モデル動向
– VLM / MLLMは”v2” へと成熟
– CLIP / DINOv2 / SAMなどのモデルの活用
– PEFT / Training-freeな省学習によるタスク適合
– 生成AI以外の観点でも普及がすすむDiffusion model
– タスクの複雑化に伴いBenchmarkも並行して整備
• 3D Vision動向
– 大規模3D datasetによる3D生成AIの進化
– Internet scaleの画像で学習したロバストな単眼Depth推定
– 3D Gaussian Splattingの急速な進展と普及
– 3D Visionにおけるunified model
全体まとめ











![20
事前学習済みモデルの活用 - CLIP / DINOv2 / SAM
[1] Alec Radford et al., “Learning Transferable Visual Models From Natural Language Supervision”, ICML, 2021.
[2] Maxime Oquab et al., “DINOv2: Learning Robust Visual Features without Supervision”, TMLR, 2024.
[3] Alexander Kirillov et al., “Segment Anything”, ICCV, 2023.
CLIP (1位/523本) DINOv2 (59位/67本) SAM (15位/153本)
Vision-Languageの統合
タスクのopen-vocabulary化
Semantic Alignされた
見えの変化に頑健な画像特徴量
セグメンテーションタスクの
ベースモデル
※ ()内はCVPR2024論文内での引用ランク/引用数](https://image.slidesharecdn.com/cvpr20241-240726080235-c840916a/85/CVPR2024-Vision-CVPR2024-report-21-320.jpg)







![34
Diffusion Model for X
画像出力系タスク[3] Downstreamタスク[4] 学習データ生成[5]
text-to-image[1] text/image-to-3D[2]
[1] Jing Shi Ke et al., “InstantBooth: Personalized Text-to-Image
Generation without Test-Time Finetuning”, CVPR, 2024.
[2] Minghua Liu et al., “One-2-3-45++: Fast Single Image to 3D Objects
with Consistent Multi-View Generation and 3D Diffusion”, CVPR, 2024.
[3] Bingxin Ke et al., “Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation”,
CVPR, 2024.
[4] Zigang Geng et al., “InstructDiffusion: A Generalist Modeling Interface for Vision Tasks”, CVPR, 2024.
[5] Fan Zhang et al., “Atlantis: Enabling Underwater Depth Estimation with Stable Diffusion”, CVPR, 2024.](https://image.slidesharecdn.com/cvpr20241-240726080235-c840916a/85/CVPR2024-Vision-CVPR2024-report-35-320.jpg)






![44
3D生成モデルの進展 - Gen 1 to Gen 2
Gen 1
Diffentiable Rendering
+ Multiview Supervision
[1] Eric R. Chan et al., “Efficient Geometry-aware 3D Generative Adversarial Networks”, CVPR, 2022.
[2] Ben Poole et al., “DreamFusion: Text-to-3D using 2D Diffusion”, ICLR, 2023.
可微分レンダラを学習の系に組み込み
入力画像との再構築誤差で学習
3D教師データが不要で学習可能
3D geometryにノイズが多い
Gen 2
Score Distillation Sampling
diffusion modelを利用して
NeRFの3D表現を最適化
3D教師データが不要で学習可能
低速・Janus問題
Janus問題](https://image.slidesharecdn.com/cvpr20241-240726080235-c840916a/85/CVPR2024-Vision-CVPR2024-report-45-320.jpg)
![45
3D生成モデルの進展 - Gen 3 to Gen 4
Gen 3
Multiview Diffusion
+ Multiview Reconstruction
Gen 4
Geometry Generation
+ Texture Generation
[1] Ruoshi Liu et al., “Zero-1-to-3: Zero-shot One Image to 3D Object”, ICCV, 2023.
[2] Xuanchi Ren et al., “XCube: Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies”, CVPR, 2024.
Multiview制約をdiffusion modelに
組み込むことで頑健性向上
Janus-free, 高速な推論
大規模なMultiviewデータセット必要
3次元点群やmeshを直接推論
高速な推論, 事前学習済みモデル不要
大規模な3Dデータセット必要](https://image.slidesharecdn.com/cvpr20241-240726080235-c840916a/85/CVPR2024-Vision-CVPR2024-report-46-320.jpg)
![46
Gen 3やGen 4を支える大規模3Dデータセット
Objaverse (2023)
10M+の3D object dataset
MVImgNet (2023)
6.2MのMulti-view dataset
[1] Matt Deitke et al., “Objaverse-XL: A Universe of 10M+ 3D Objects”, arxiv, 2023.
[2] Xianggang Yu et al., “MVImgNet: A Large-scale Dataset of Multi-view Images”, CVPR, 2023.
3Dのドメインでも巨大データセットxシンプルなモデルで直接推論できる時代になってきた](https://image.slidesharecdn.com/cvpr20241-240726080235-c840916a/85/CVPR2024-Vision-CVPR2024-report-47-320.jpg)

![50
単眼相対Depth推定(RDE)の進展
SfMLearner (2017)
各データセットごとに学習
[1] Tinghui Zhou et al., “Unsupervised Learning of Depth and Ego-Motion from Video”, CVPR, 2017.
[2] René Ranftl et al., “Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer”, TPAMI, 2020.
[3] Lihe Yang et al., “Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data”, CVPR, 2024.
MiDaS (2020)
複合データセットで学習
DepthAnything (2024)
Internet-scaleで学習
RDEでは学習できるデータセットをスケールさせることで汎化性を高めてきた](https://image.slidesharecdn.com/cvpr20241-240726080235-c840916a/85/CVPR2024-Vision-CVPR2024-report-51-320.jpg)

![53
単眼メトリックDepth推定(MDE)の進展
ZoeDepth (2023)
[1] Shariq Farooq Bhat et al., “ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth”, arxiv, 2023.
[2] Wei Yin et al., “Metric3D: Towards Zero-shot Metric 3D Prediction from A Single Image”, arxiv, 2023.
Metric3D (2023)
相対Depth推定器の進展に底上げされてメトリック推定も汎化性が大幅に向上
metric depth推定用のLUTを学習し
分類問題として推定する
カメラの内部パラメータをつかった
変換・逆変換で相対デプスから絶対デプス
に変換](https://image.slidesharecdn.com/cvpr20241-240726080235-c840916a/85/CVPR2024-Vision-CVPR2024-report-54-320.jpg)
![55
3D Gaussian Splattingの進展
0
50
100
150
2022 2023 2024
NeRF 3D Gaussian Splatting
[1] Bernhard Kerbl et al., “3D Gaussian Splatting for Real-Time Radiance Field Rendering”, SIGGRAPH, 2023.
NVSでの
定常進化
3D生成AIでの
利用
Offline
3Dシーン再構築
Online
3Dシーン再構築
(SLAM)
CVPR2024で見られた進展](https://image.slidesharecdn.com/cvpr20241-240726080235-c840916a/85/CVPR2024-Vision-CVPR2024-report-56-320.jpg)



![60
3D Visionにおけるunified model - DUSt3R / MASt3R
“impossible matching”
まったく共通視野のない2画像での
3次元復元
本会議での発表に加えて、
2つのworkshopのinvited talkでも登壇
学会内で話題の論文の一つ
[1] https://x.com/JeromeRevaud/status/1763495315389165963
[2] https://image-matching-workshop.github.io/
[3] https://3dfm.github.io/
DUSt3R - Dense Unconstrained Stereo 3D Reconstruction](https://image.slidesharecdn.com/cvpr20241-240726080235-c840916a/85/CVPR2024-Vision-CVPR2024-report-61-320.jpg)






![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)



















![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)





















