Download to read offline





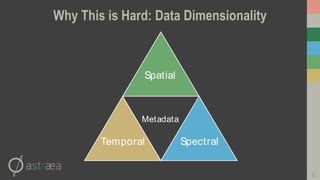
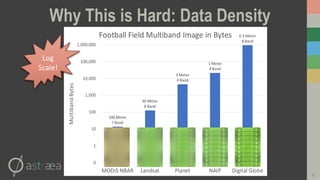
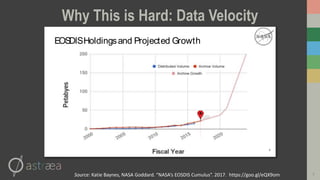

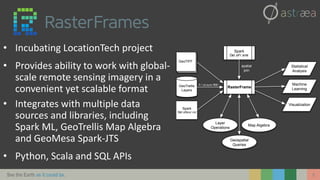



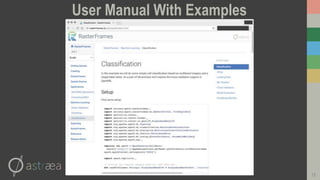

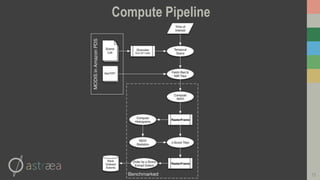





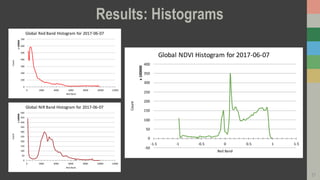

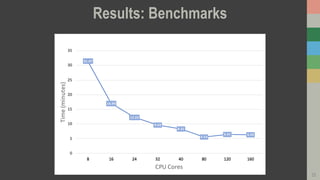



This document introduces RasterFrames, an open source project that enables global-scale geospatial machine learning. RasterFrames provides scalable tools for working with large remote sensing datasets in a convenient format. It integrates with Spark, GeoTrellis and other libraries. The document demonstrates RasterFrames by computing NDVI values from MODIS data and finding the highest NDVI locations globally on a given day. Performance benchmarks show RasterFrames can scale to large datasets across multiple CPU cores.
















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)












![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)





