Downloaded 21 times

















![Possible
Workaround
• Look-‐ahead:
Customize
Lucene/Solr
to
do
a
branch-‐and-‐bound
search,
bail
out
on
some
lower
bound
score
• Minimize
candidates
for
DisMax
search
-‐ reduce
total
number
of
Solr
instances
to
search
-‐ reduce
total
number
of
disjunc8ve
terms
[
Empirical
es8mate:
tn
=
2
*
tn-‐1
where
t
=
8me
&
n
=
number
of
disjunc8ve
terms]
5/2/13
18](https://image.slidesharecdn.com/rapidpruningofsearchspacethroughhierarchicalmatching-130515142428-phpapp01/75/Rapid-pruning-of-search-space-through-hierarchical-matching-18-2048.jpg)


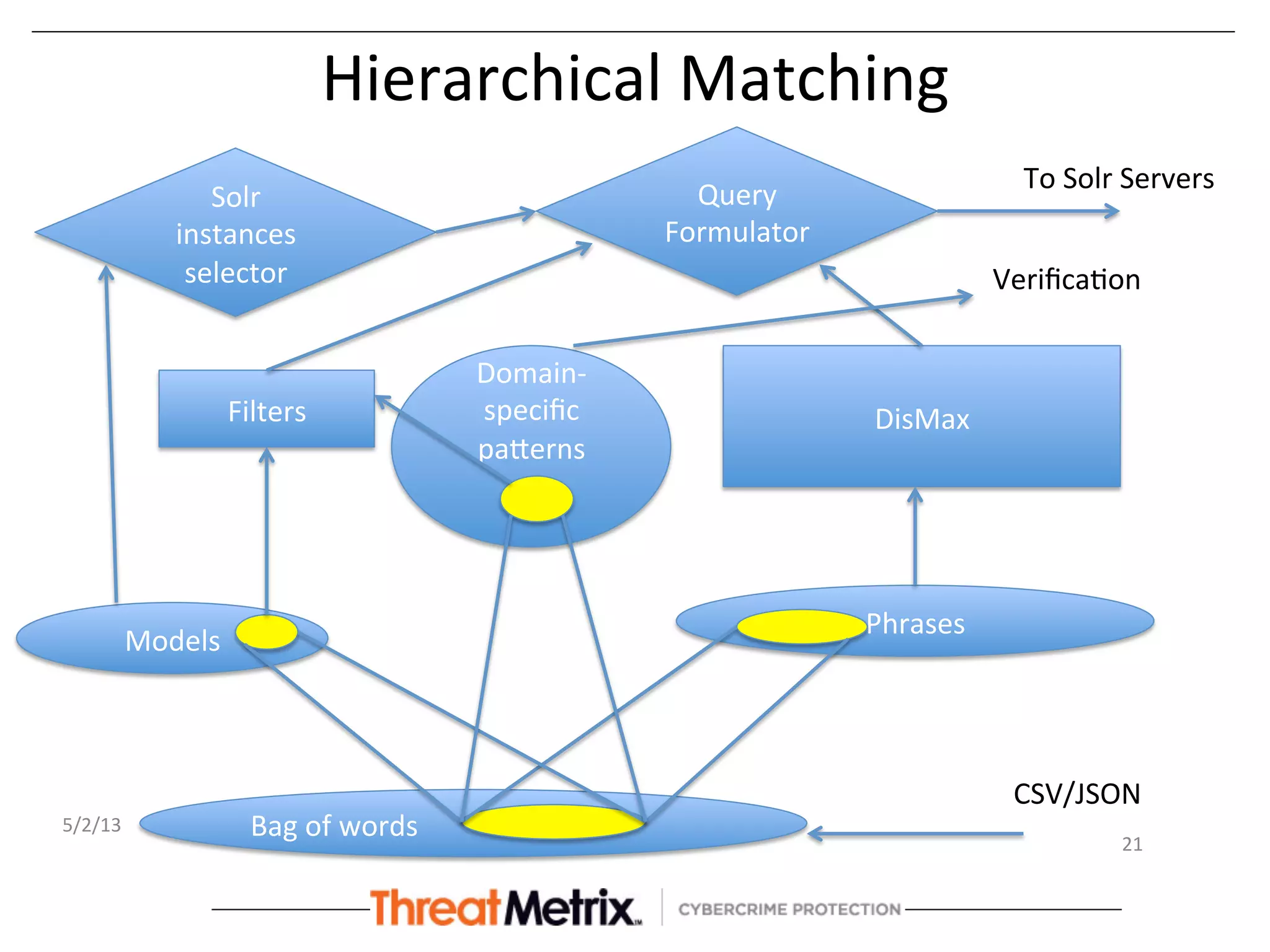






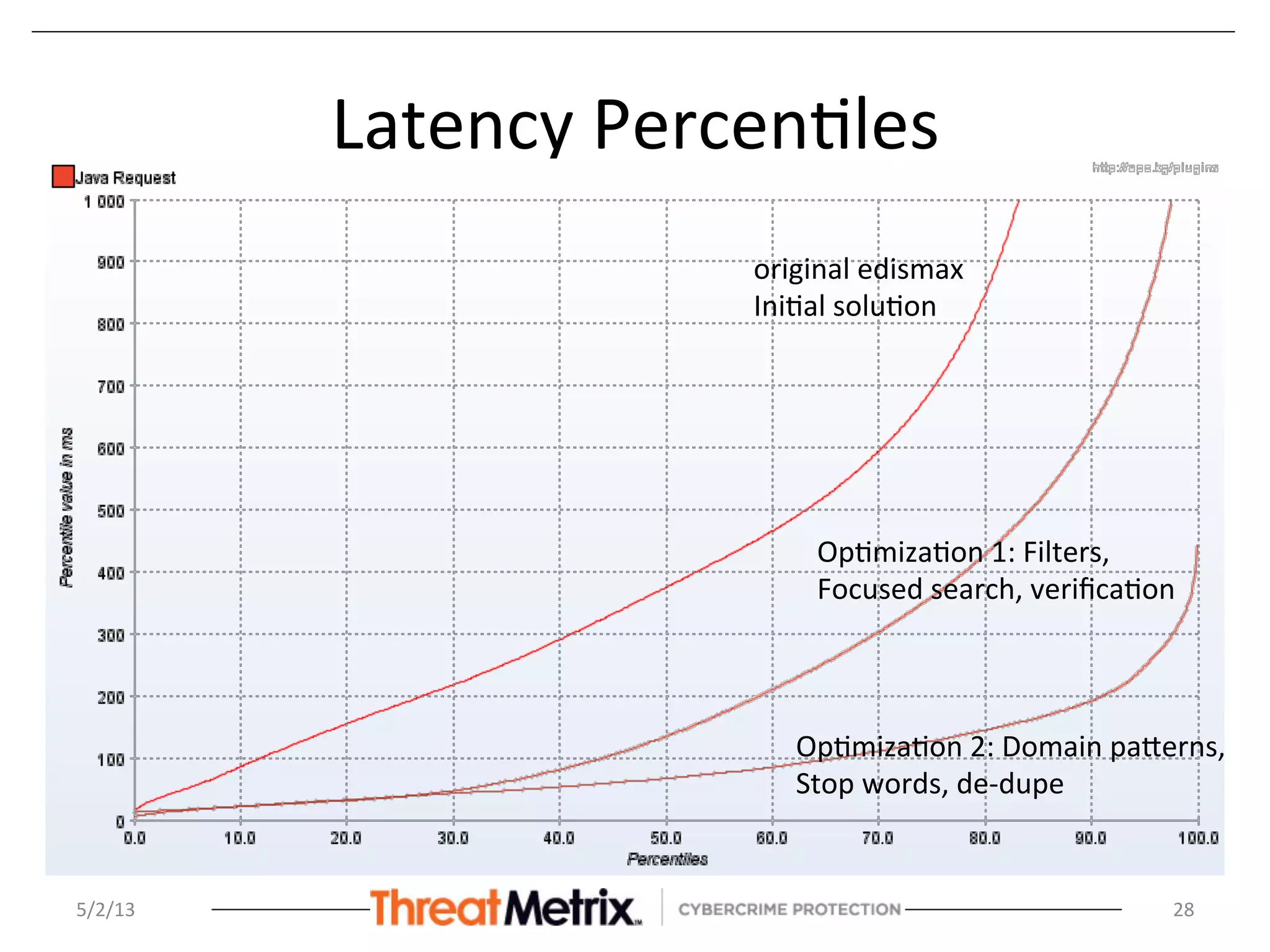
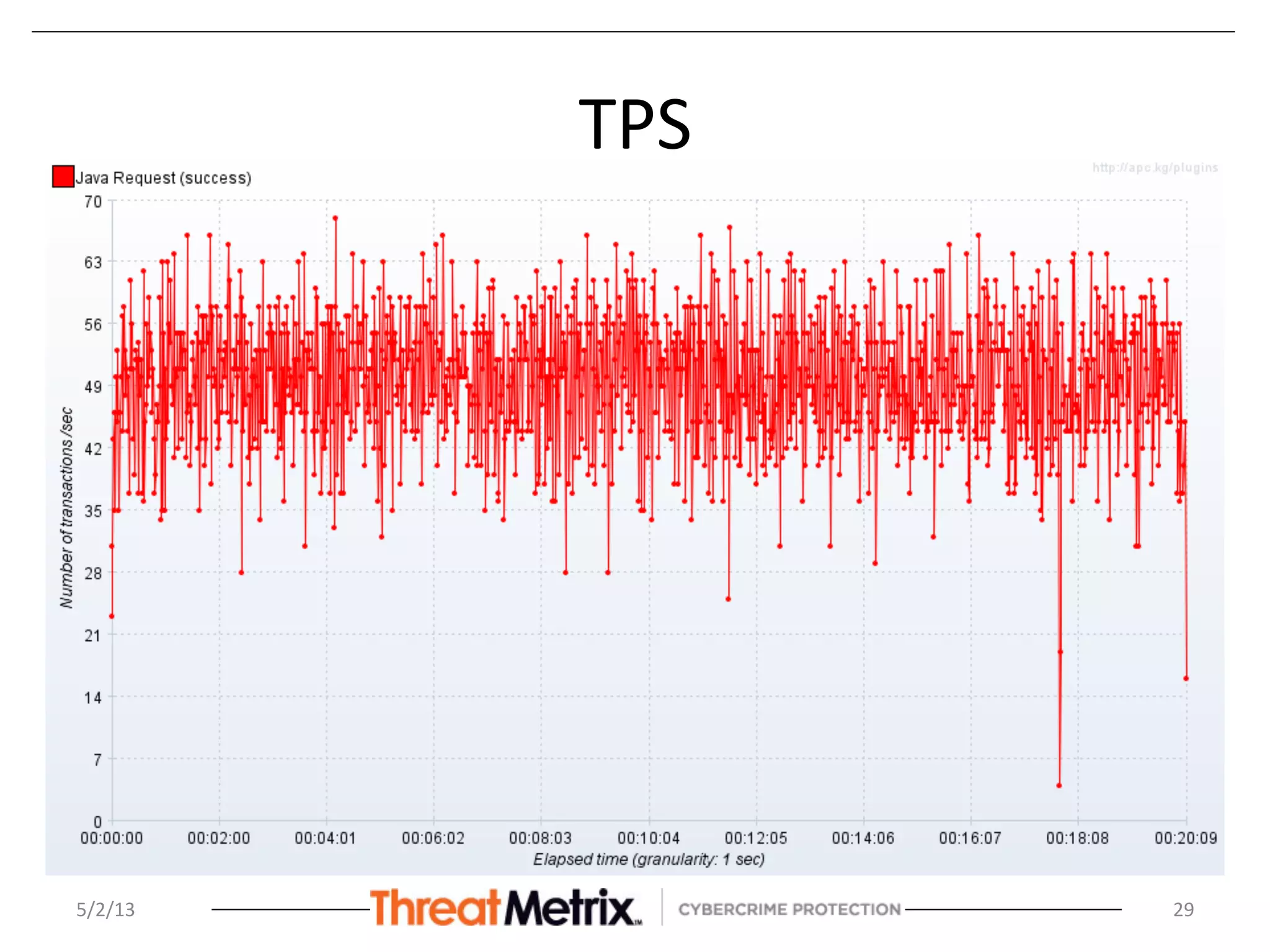
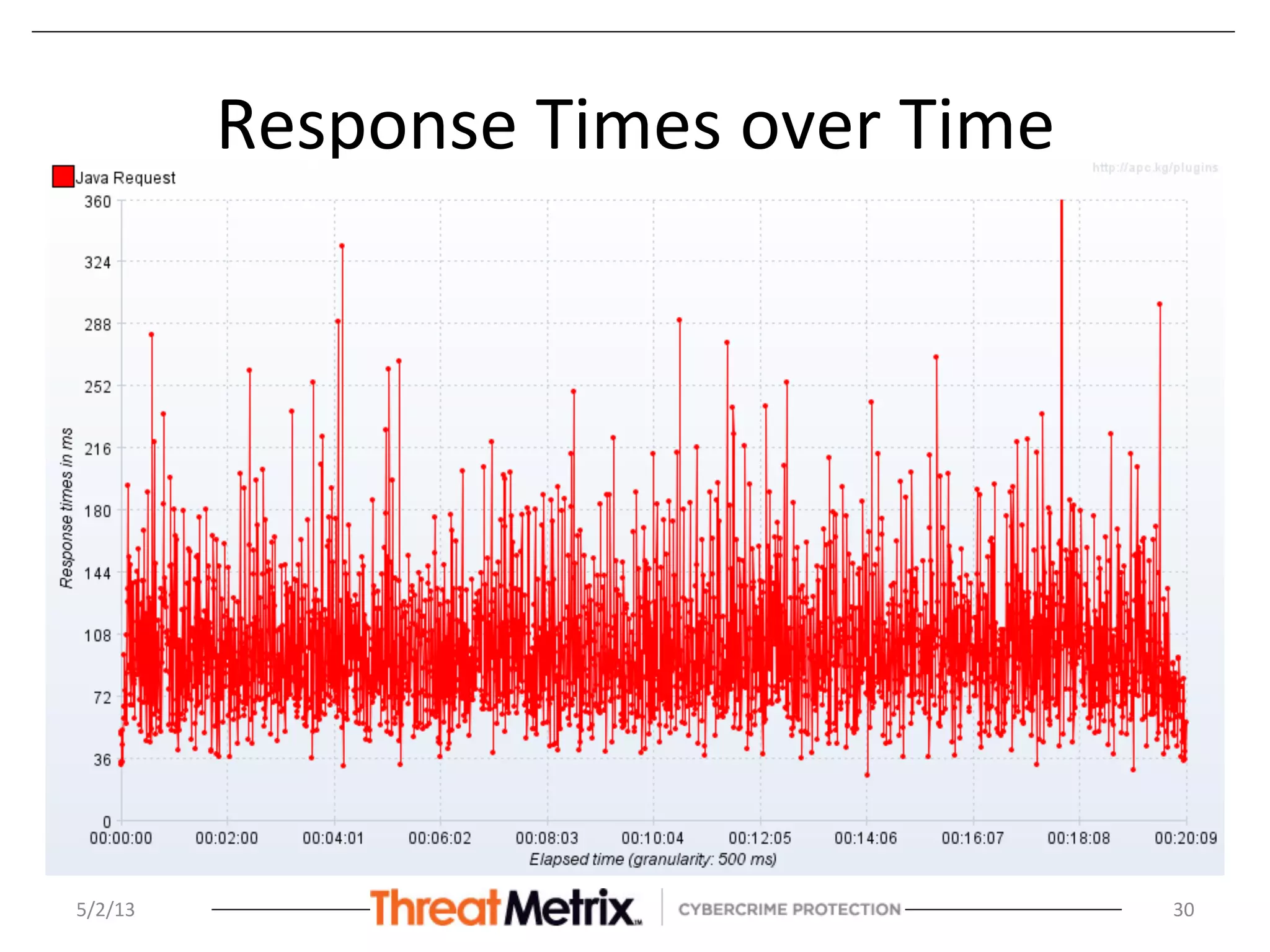







The document discusses the hierarchical matching approach to rapidly prune search space for device identification tasks faced by machine learning applications. It highlights the challenges of precision, latency, and the need for enterprise-level solutions, while exploring various methodologies including rules engines, learning models, and vector space models. The results demonstrate the effectiveness of these approaches in enhancing accuracy and response times during the classification of devices.























































































