- 지도학습
- 정답을알고 있는 데이터를 이용해 학습
- 비지도학습
- 정답없이 주어진 데이터로 학습
- 강화학습
- 행동의 결과로 나타나는 보상을 통해 학습
머신러닝
3.
Agent가 문제 정의를하기 위한 구성요소
- 상태(state)
- 현재 에이전트의 정보.
- 에이전트가 상태를 통해 상황을 판단해서 행동을 결정하기에 충분한 정보를 제공.
- 행동(action)
- 에이전트가 어떠한 상태에서 취할 수 있는 행동(사기, 팔기, …)
- 보상(reward)
- 자신이 했던 행동들을 평가할 수 있는 단서.
- environment
4.
Q Learning
- Qfunction : state-action value function
- Q(state, action) → reward(quality)
- ex.
- Q(state1, LEFT) = 0
- Q(state1, RIGHT) = 0.5
- Q(state1, UP) = 0.2
- Q(state1, DOWN) = 0.1
- 위와 같은 경우 state1의 경우에는 RIGHT일 때 기대값이 가장 크므로, RIGHT action을 취하면
된다는 것을 알 수 있음.
5.
(dummy) Q-Learning algorithm
1.모든 s,a에 대해 Q(s,a)=0로 초기화
2. observe current state s
3. 액션 a를 선택하고 실행
4. reward(r)을 받음
5. observe the new state s’ : s’로 이동
6. update Q(s,a)
a. Q(s,a) ← r + max Q(s’,a’)
7. s ← s’
8. 3으로 계속 반복.
6.
Exploit vs Exploration: decaying E-greedy
for i in range(1000):
e = 0.1 / (i+1)
if random(1)<e:
action = random
else:
action = argmax(Q(s,a))
Deterministic vs Stochastic
-Deterministic
- the output of the model is fully determined by the parameter values and the initial conditions
- 항상 정해진 입력에 대해서 동일한 출력이 나오는 환경을 의미.
- frozen lake 게임에서 is_slippery가 False인 경우로 생각하면 됨.
- Stochastic :
- the same set of parameter values and initial conditions will lead to an ensemble of different outputs.
- frozen lake에서 is_slippery가 True인 경우와 유사함.
- 동일한 입력에 대해서 항상 동일한 결과가 나오지 않는 환경.
9.
Learning incrementally
- …
위의기존 Q를 그대로 받아 들이는 방식과는 달리 learning rate를 도입함.
- …
- tensorflow의 learning rate와 동일한 개념.
- 기존의 Q를 모두 받아 들이는 방식과는 다르게, learning rate 만큼만 받아 들임.
10.
Q Network
- 기존Q-Table 방식으로 커버할 수 없는 수많은 + 복잡한 경우가 존재하는 케이
스는?
- Q-Table 대신 Neural Network을 사용
- State를 입력으로 하고, 가능한 Action들을 출력으로 주도록 network을 구성
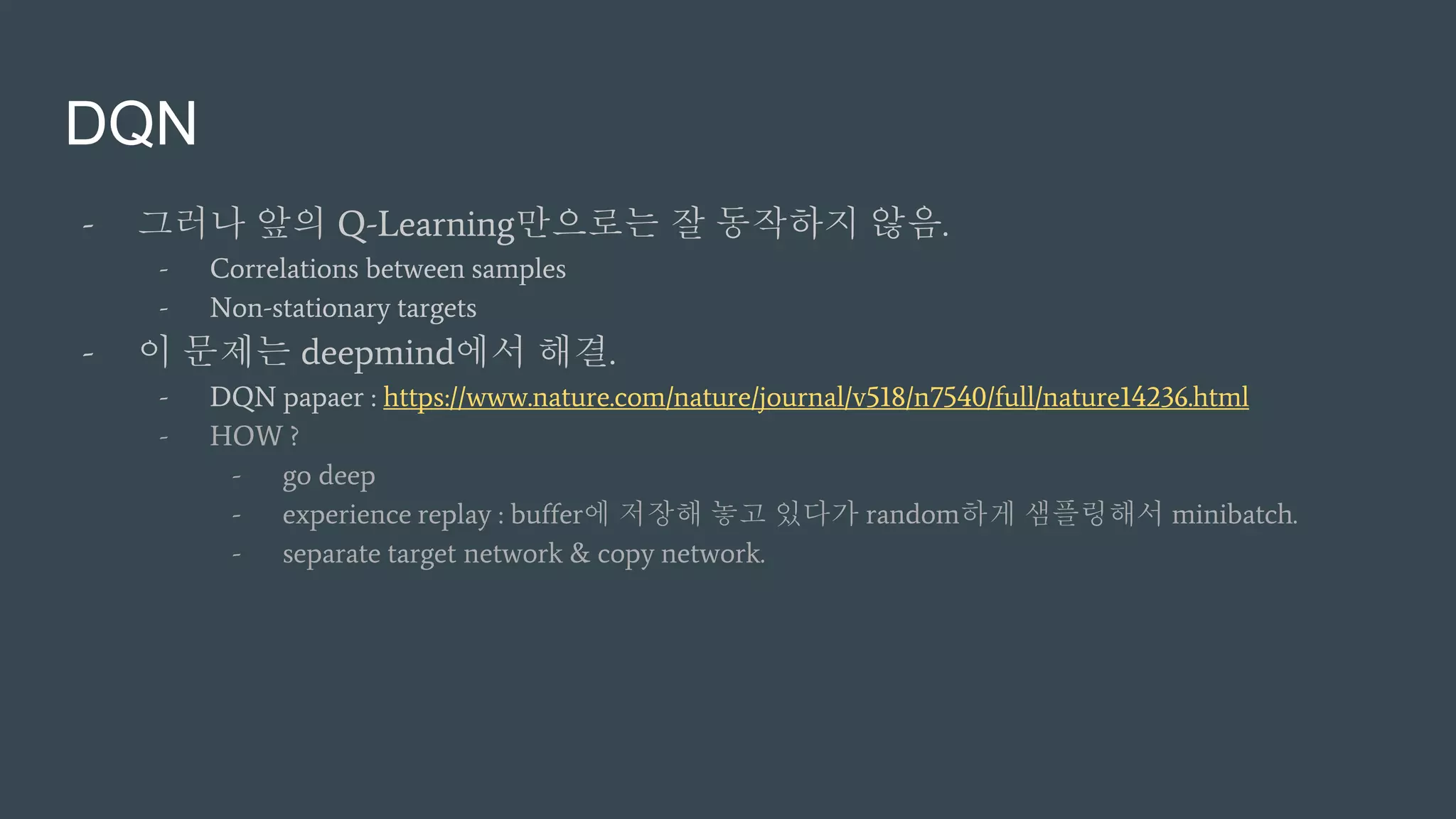
DQN
- 그러나 앞의Q-Learning만으로는 잘 동작하지 않음.
- Correlations between samples
- Non-stationary targets
- 이 문제는 deepmind에서 해결.
- DQN papaer : https://www.nature.com/nature/journal/v518/n7540/full/nature14236.html
- HOW ?
- go deep
- experience replay : buffer에 저장해 놓고 있다가 random하게 샘플링해서 minibatch.
- separate target network & copy network.
14.
주식 데이터에 적용
-pandas, sqlite3, sklearn을 사용해서 전처리
- https://github.com/dspshin/DQN_examples/blob/master/stock.ipynb
- 소스코드
- https://github.com/dspshin/DQN_examples
15.
소스코드 간단 해설
-기반은 cartpole example
- https://github.com/dspshin/DQN_examples/blob/master/cart_pole_dqn2015.py
- gym을 stock과 관련된 동작을 하도록 재정의
- gym.reset(), gym.step()을 재정의
- 로직의 간단화를 위해, 주식 거래 단위는 1개로 고정.
- 추후 보다 현실적으로 변경 필요.
- action은 3가지 - 매도, 매수, 아무것도 안하기
- state의 구성요소
- ['ratio', 'amount', 'ends', 'foreigner', 'insti', 'person', 'program', 'credit']
- https://github.com/dspshin/DQN_examples/blob/master/my_gym/gym.py
- dqn network 변경
16.
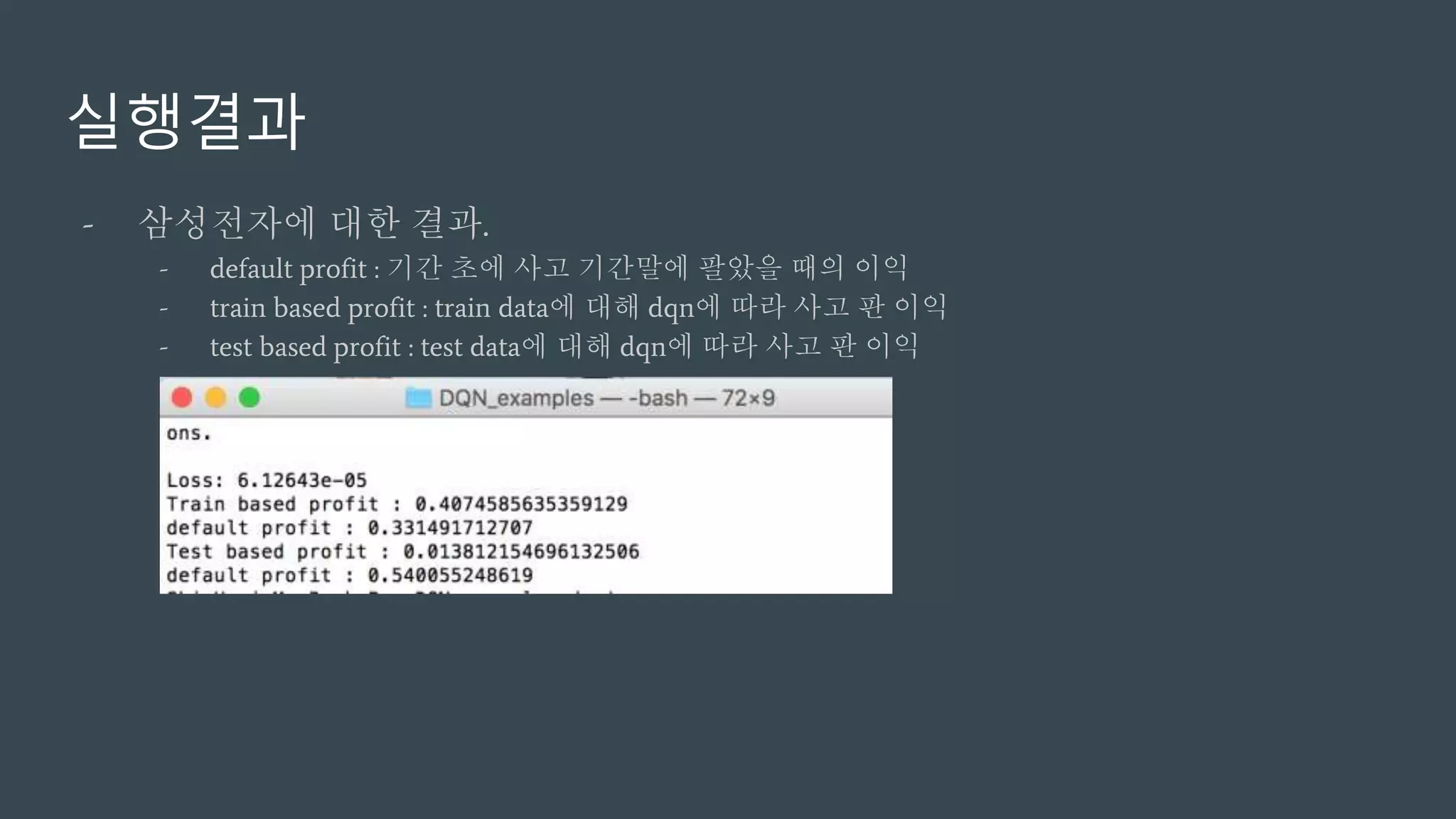
실행결과
- 삼성전자에 대한결과.
- default profit : 기간 초에 사고 기간말에 팔았을 때의 이익
- train based profit : train data에 대해 dqn에 따라 사고 판 이익
- test based profit : test data에 대해 dqn에 따라 사고 판 이익
17.
To do list
-다른 종목들에 대한 테스트
- 입력인자를 더 추가
- Network을 다르게 구성













![소스코드 간단 해설
- 기반은 cartpole example
- https://github.com/dspshin/DQN_examples/blob/master/cart_pole_dqn2015.py
- gym을 stock과 관련된 동작을 하도록 재정의
- gym.reset(), gym.step()을 재정의
- 로직의 간단화를 위해, 주식 거래 단위는 1개로 고정.
- 추후 보다 현실적으로 변경 필요.
- action은 3가지 - 매도, 매수, 아무것도 안하기
- state의 구성요소
- ['ratio', 'amount', 'ends', 'foreigner', 'insti', 'person', 'program', 'credit']
- https://github.com/dspshin/DQN_examples/blob/master/my_gym/gym.py
- dqn network 변경](https://image.slidesharecdn.com/yky1vxfkqgm0u5e3y47m-signature-bb145771655240b9c4bc2a77657e68e696084c48db55e0e23e48858e3743f255-poli-171112164427/75/ML-phase-2-15-2048.jpg)







![[125] 머신러닝으로 쏟아지는 유저 cs 답변하기](https://cdn.slidesharecdn.com/ss_thumbnails/25cs-171016061055-thumbnail.jpg?width=640&height=640&fit=bounds)





![[D2대학생세미나]lovely algrorithm](https://cdn.slidesharecdn.com/ss_thumbnails/d2lovelyalgrorithm-140827015148-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)



![[RLkorea] 각잡고 로봇팔 발표](https://cdn.slidesharecdn.com/ss_thumbnails/rlkorea-robotarm-190303021332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[머가]Chap11 강화학습](https://cdn.slidesharecdn.com/ss_thumbnails/chap11-170923012256-thumbnail.jpg?width=640&height=640&fit=bounds)












