Download as PDF, PPTX





![Concept: Directed acyclic graph, operator, task, etc
custom_param_per_dag = {'sg': { ... }, 'eu': { ... }, 'us': { ... }}
for region, v in custom_param_per_dag.items():
dag = DAG('shipment_{}'.format(region), ...)
export = PostgresToS3Operator(task_id='db_to_s3', ...)
transfer = S3CopyObjectOperator(task_id='s3_to_s3', ...)
export >> transfer
globals()[dag] = dag
9](https://image.slidesharecdn.com/yohei-onishi-airflow-pyconsg2019-191011102520/85/Building-a-Data-Pipeline-using-Apache-Airflow-on-AWS-GCP-9-320.jpg)
![template
t1 = PostgresToS3Operator(
task_id='db_to_s3',
sql="SELECT * FROM shipment WHERE region = '{{ params.region }}'
AND ship_date = '{{ execution_date.strftime("%Y-%m-%d") }}'",
bucket=default_args['source_bucket'],
object_key='{{ params.region }}/{{
execution_date.strftime("%Y%m%d%H%M%S") }}.csv',
params={'region':region},
dag=dag) 10](https://image.slidesharecdn.com/yohei-onishi-airflow-pyconsg2019-191011102520/85/Building-a-Data-Pipeline-using-Apache-Airflow-on-AWS-GCP-10-320.jpg)

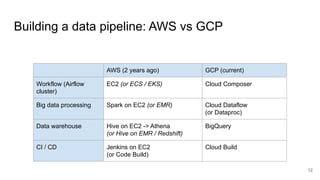
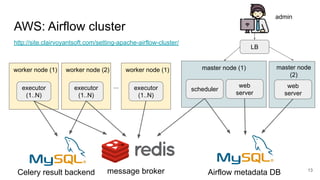

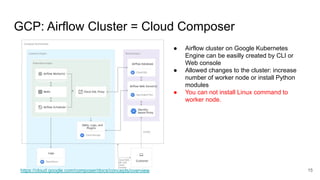
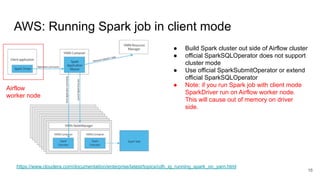
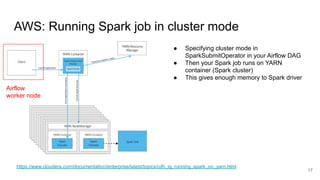


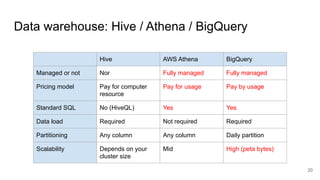
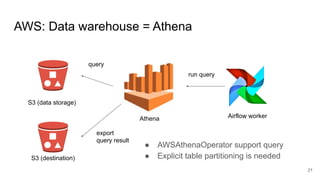
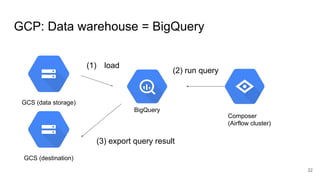
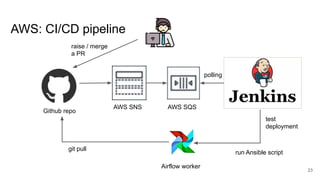
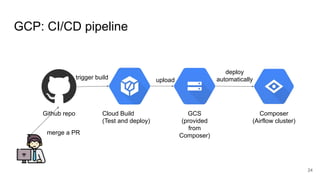
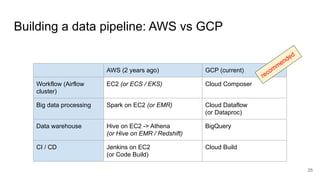




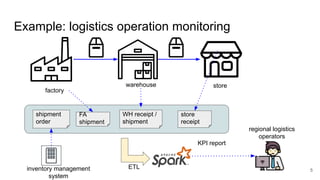
The document presents a session at PyCon SG 2019 by Yohei Onishi on building data pipelines using Apache Airflow on AWS and GCP, targeting data engineers. It covers topics such as Airflow's capabilities, examples of data workflows, comparisons between AWS and GCP services, and best practices for creating scalable data pipelines. Ultimately, it suggests that GCP offers superior managed services for data pipelines and warehousing.



















































![Test-Driven Development for [Embedded] C by James Grenning at Agile Japan 2013](https://cdn.slidesharecdn.com/ss_thumbnails/embeddedtdd-agilejapan-130526025754-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























