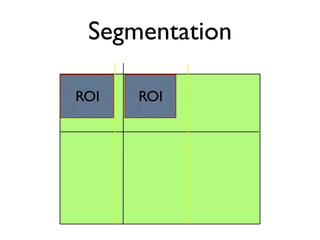
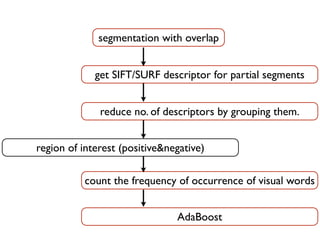
The document discusses using MapReduce for machine learning algorithms on multi-core systems. It describes segmenting images into regions of interest for feature extraction using SIFT and SURF descriptors. Machine learning algorithms like AdaBoost, locally weighted linear regression, naive Bayes, and support vector machines are proposed to fit the MapReduce model by dividing data and computation across multiple cores. Experimental results show nearly 2x speedup on 2 cores and 54x speedup on 64 cores by parallelizing algorithm computations.




![Map-Reduce???
• It’s just a framework
• You can also implement it by reading the
paper[1]. :)
• Hadoop is one implementation. (Apache +
Yahoo)
• Google’s implementation is not made
public.](https://image.slidesharecdn.com/projectprogress-090702024937-phpapp01/85/Project-Progress-6-320.jpg)






























































































