The document outlines the principles and methodologies for conducting agricultural experiments, defining key terms such as experiments, factors, treatments, and statistical considerations in experimentation. It describes different types of experiments and surveys, emphasizing the importance of clear research aims, unbiased methodologies, and ethical practices. Additionally, it discusses sampling techniques, the design of surveys, and the analysis of data to derive meaningful conclusions relevant to agricultural practices.






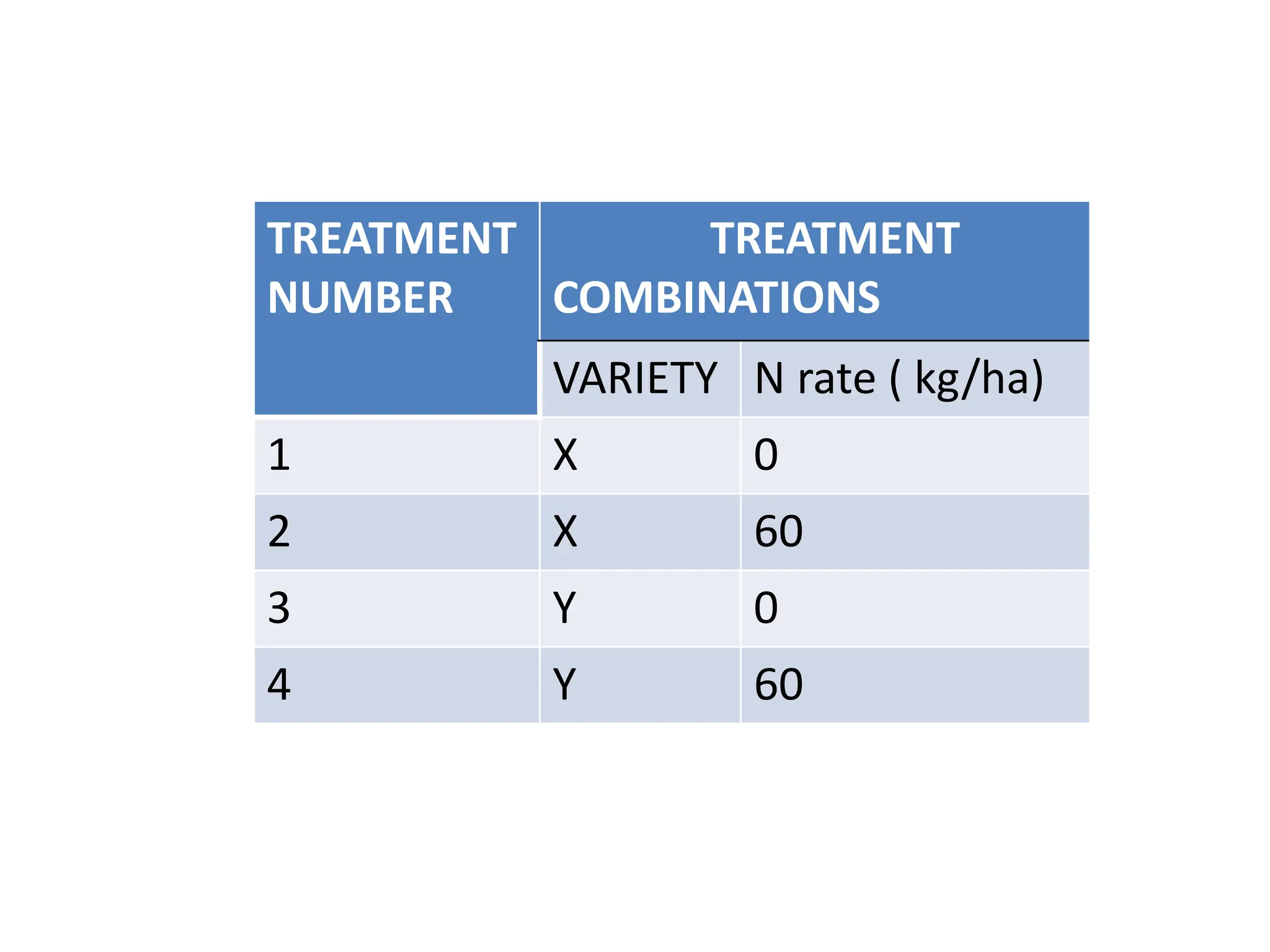
![ Treatment or Treatment
combination
• is one or more things that are compared or
investigated in an experiment. OR
• It is a dosage/ amount of materials or
procedure which is to be tested in experiment.
• Example: In experiment involved spacing trial
[a factor] and a fertilizer trial[another factor],
now trial treatments can be:-
• Planting at 75x60cm with 60kgs N/ha.
• Planting at 25x10cm with 20 kgs N/ha](https://image.slidesharecdn.com/experimentation1-240620063004-d661c84d/75/PRINCIPLES-OF-AGRICULTURAL-EXPERIMENTATION1-8-2048.jpg)
![• NB: Total number of treatments is the product
of levels in each factor.
• For above example will be:
[2 factors] x[2 level] = 4 treatments](https://image.slidesharecdn.com/experimentation1-240620063004-d661c84d/75/PRINCIPLES-OF-AGRICULTURAL-EXPERIMENTATION1-9-2048.jpg)











































![v. Treatment or Treatment
combination
• is one or more things that are compared or
investigated in an experiment.
• It is a dosage/ amount of materials or
procedure which is to be tested in experiment.
• Example: In experiment involved spacing trial
[a factor] and a fertilizer trial[another factor],
now trial treatments can be:-
• Planting at 75x60cm with 60kgs N/ha.
• Planting at 25x10cm with 20 kgs N/ha](https://image.slidesharecdn.com/experimentation1-240620063004-d661c84d/75/PRINCIPLES-OF-AGRICULTURAL-EXPERIMENTATION1-53-2048.jpg)
![• NB; Total number of treatments is the
products of levels in each factor.
• For above example will be
[2factors] x[2level] =4treatments](https://image.slidesharecdn.com/experimentation1-240620063004-d661c84d/75/PRINCIPLES-OF-AGRICULTURAL-EXPERIMENTATION1-54-2048.jpg)