Download as PDF, PPTX





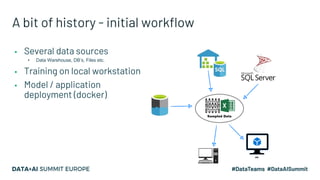

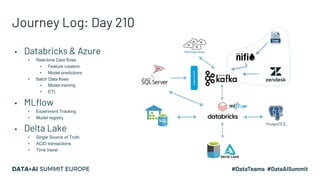
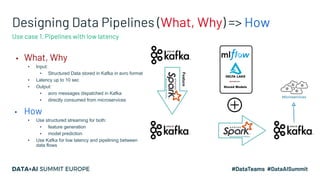
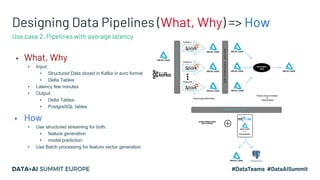

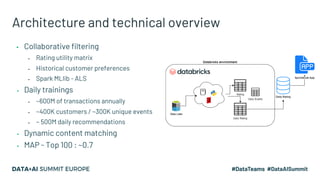

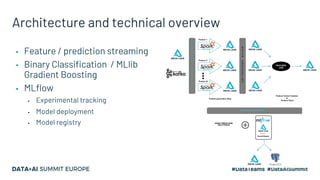
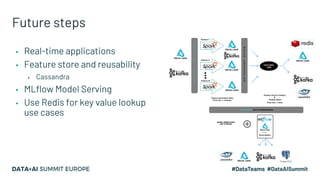


Kaizen, a leading gametech company in Greece, aims to enhance customer experience through personalized services using machine learning and data streaming technologies. The document details the company's evolution in data pipeline design, focusing on real-time and batch processing for feature generation and model predictions. Key components include collaborative filtering for sportsbook personalization and strategies for real-time bonus computation, with future plans for feature store implementation and model serving.























































































