Download to read offline

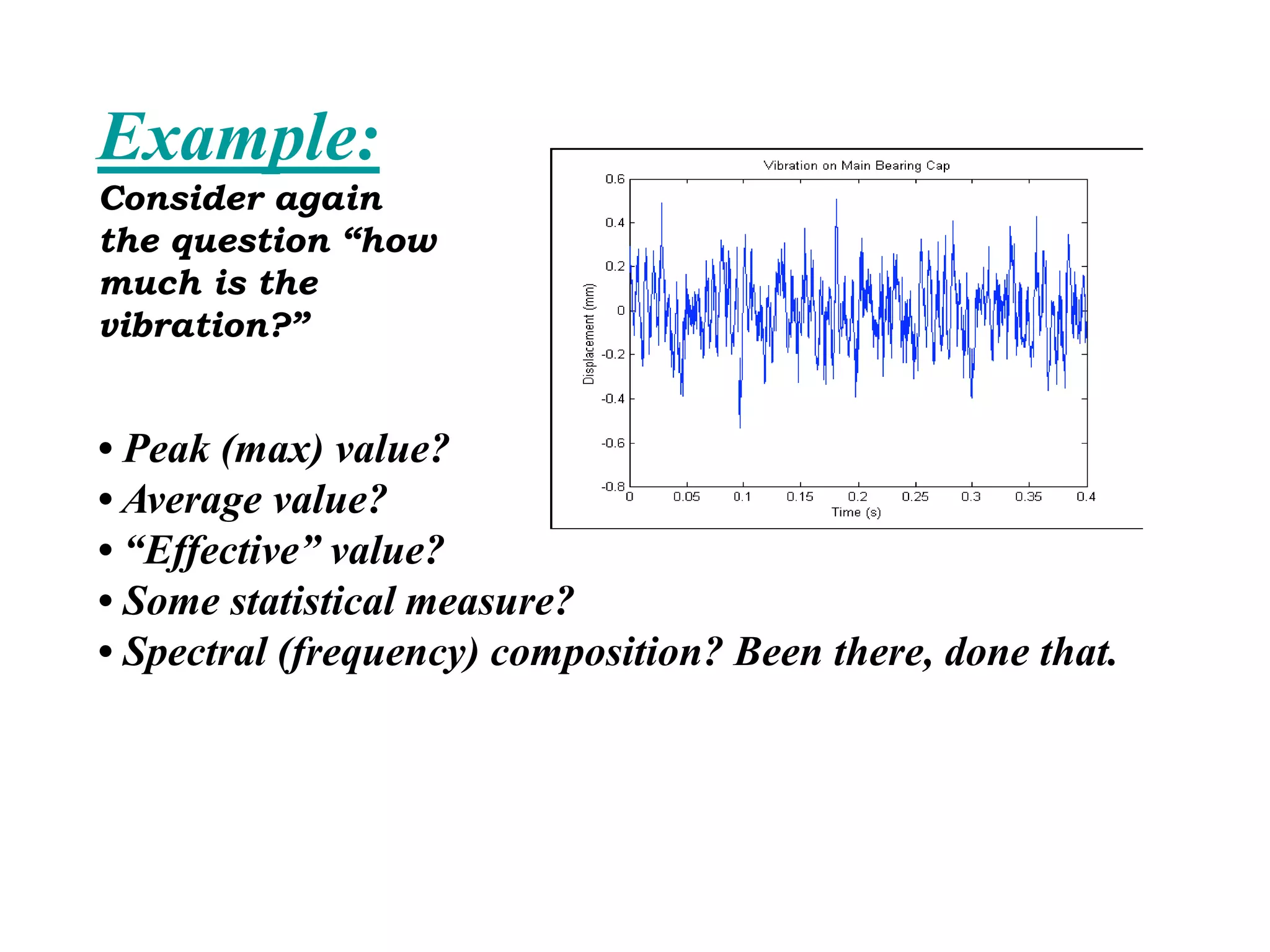


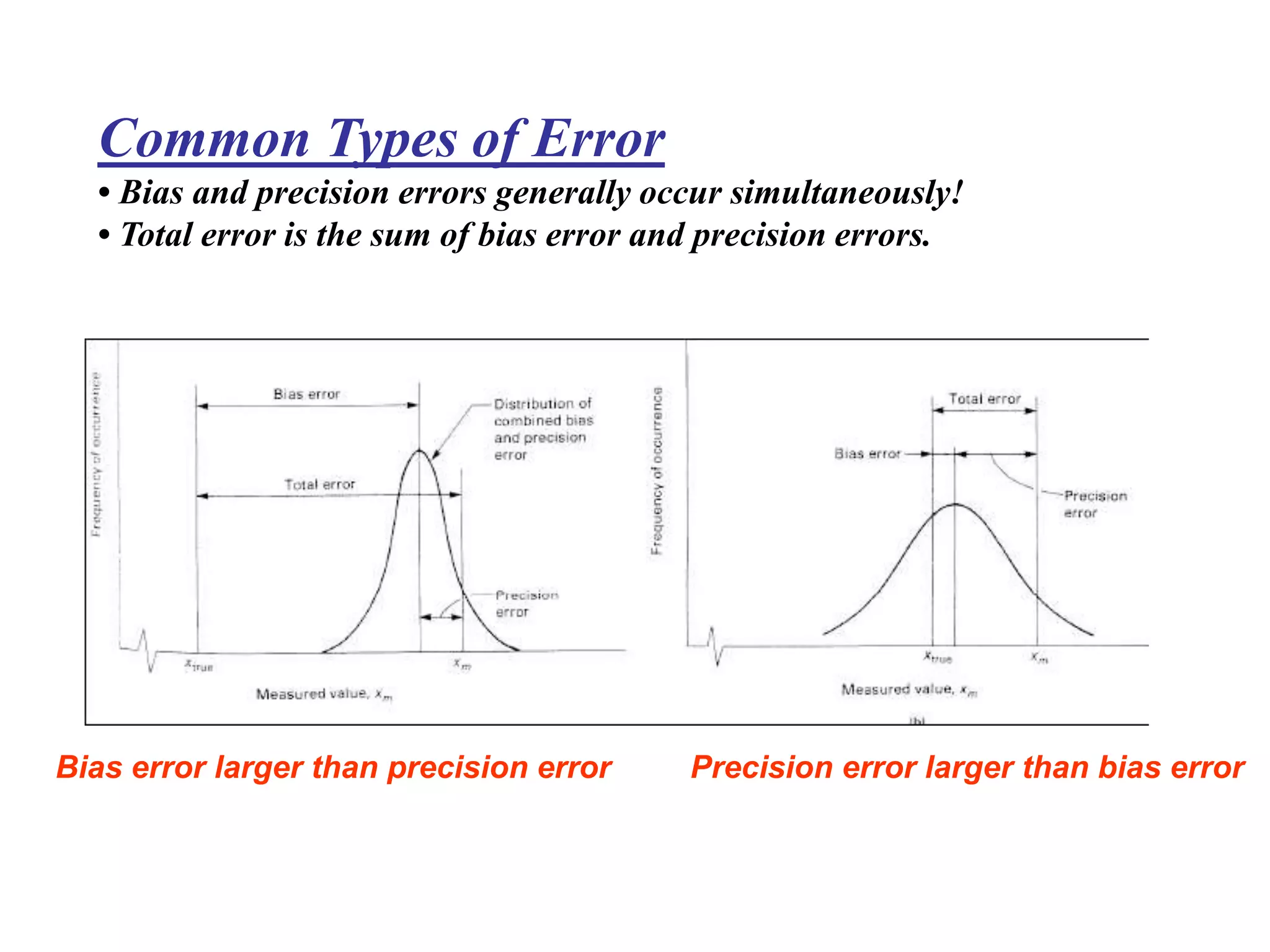


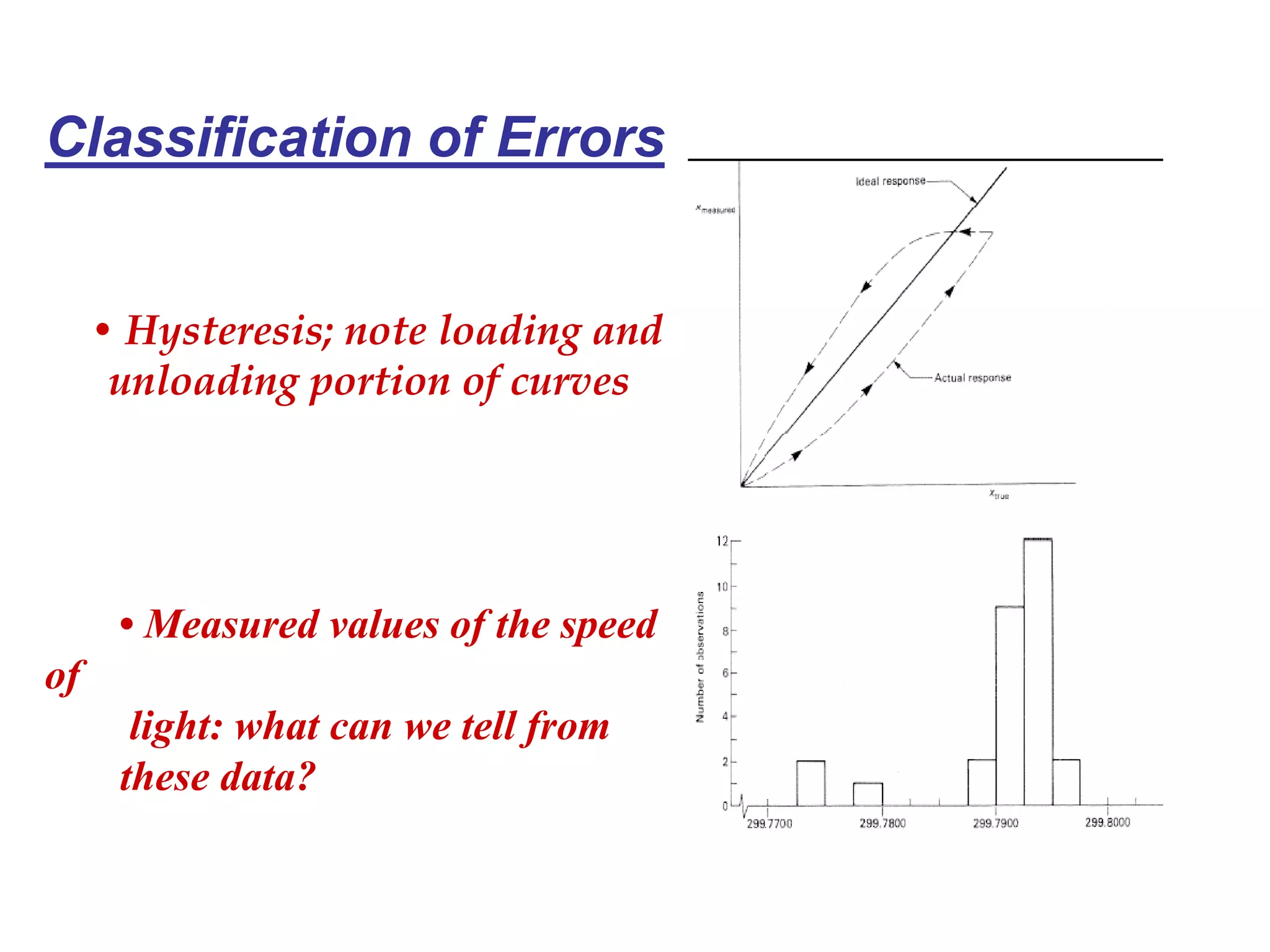

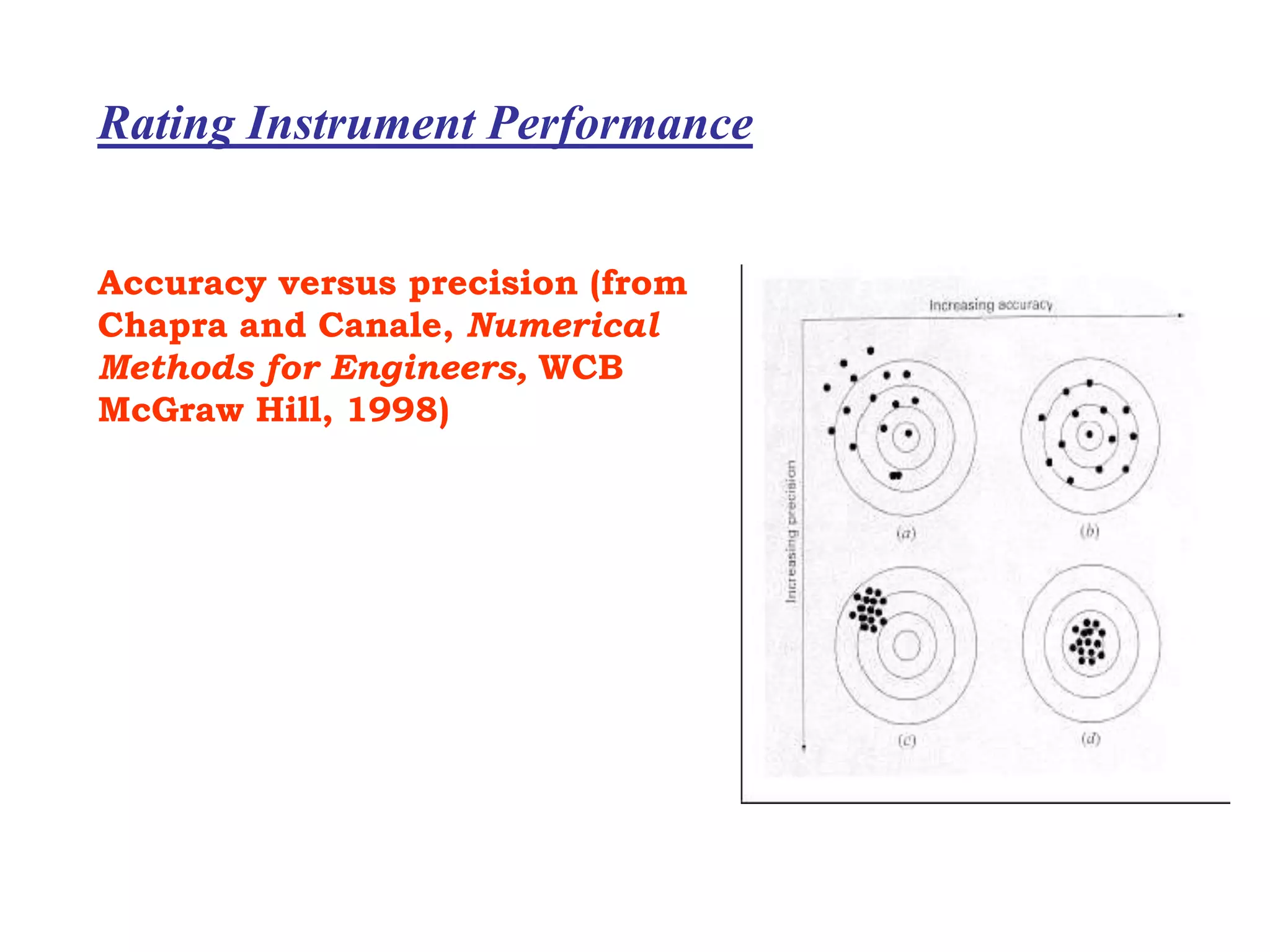



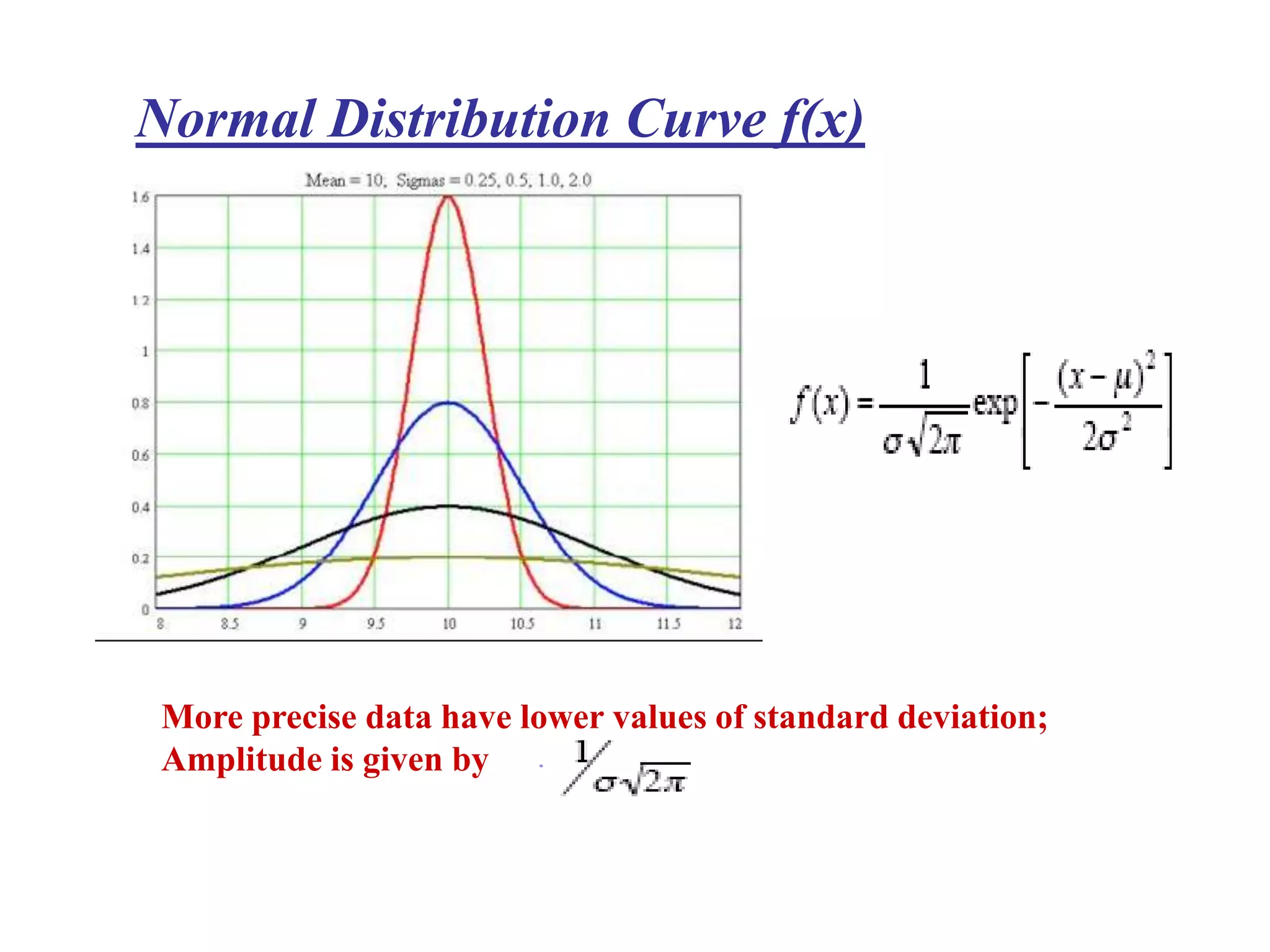
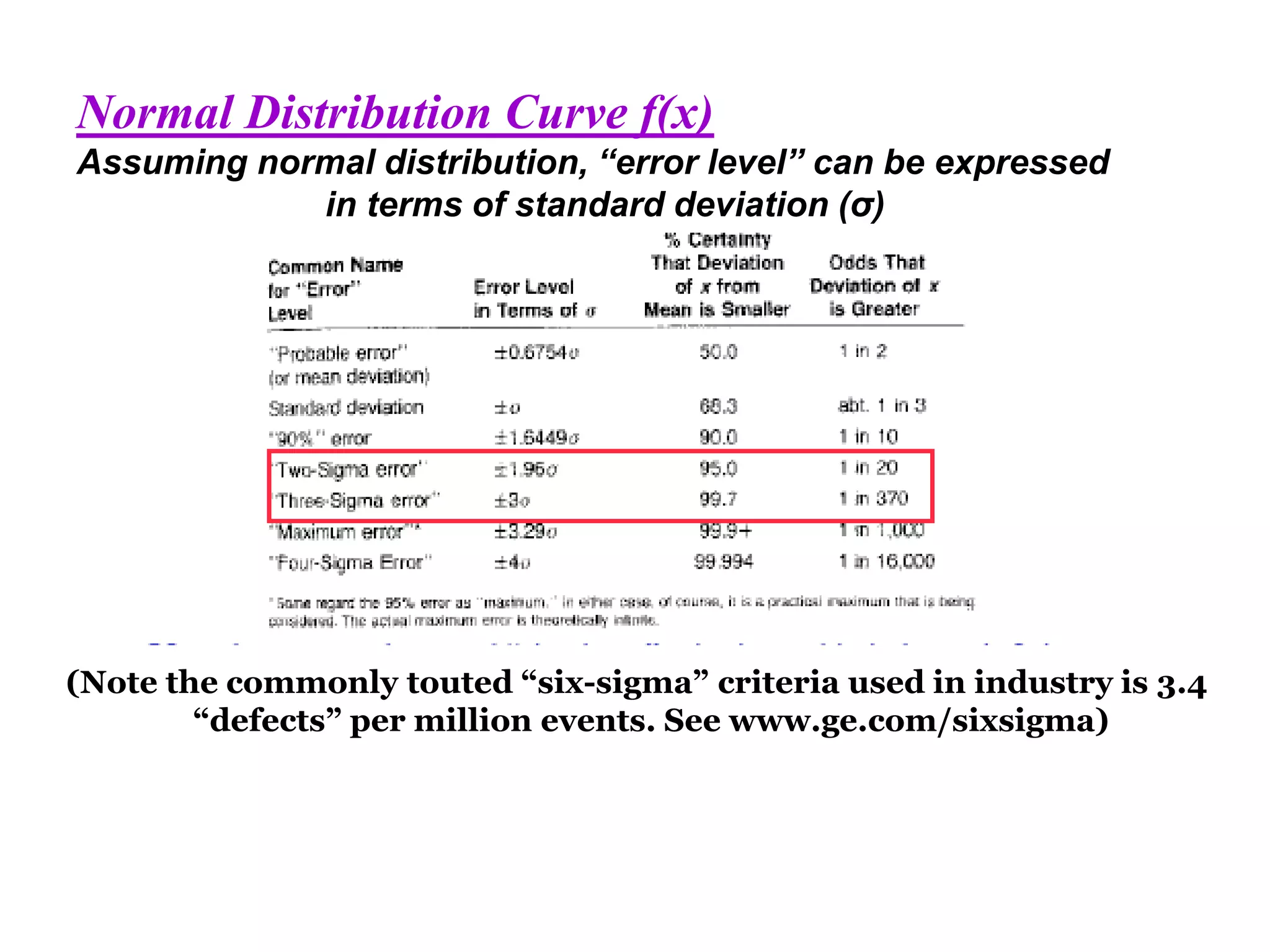
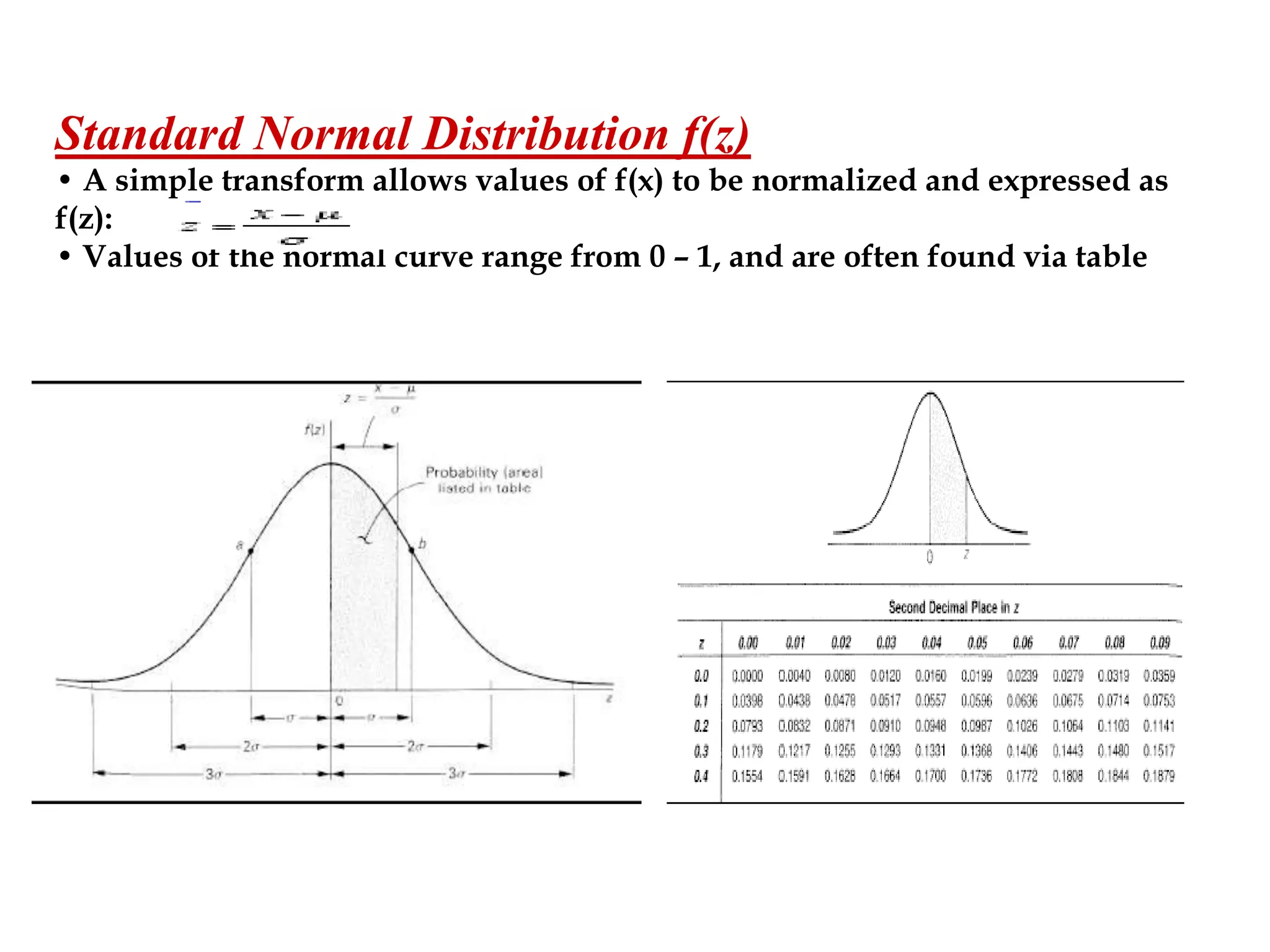

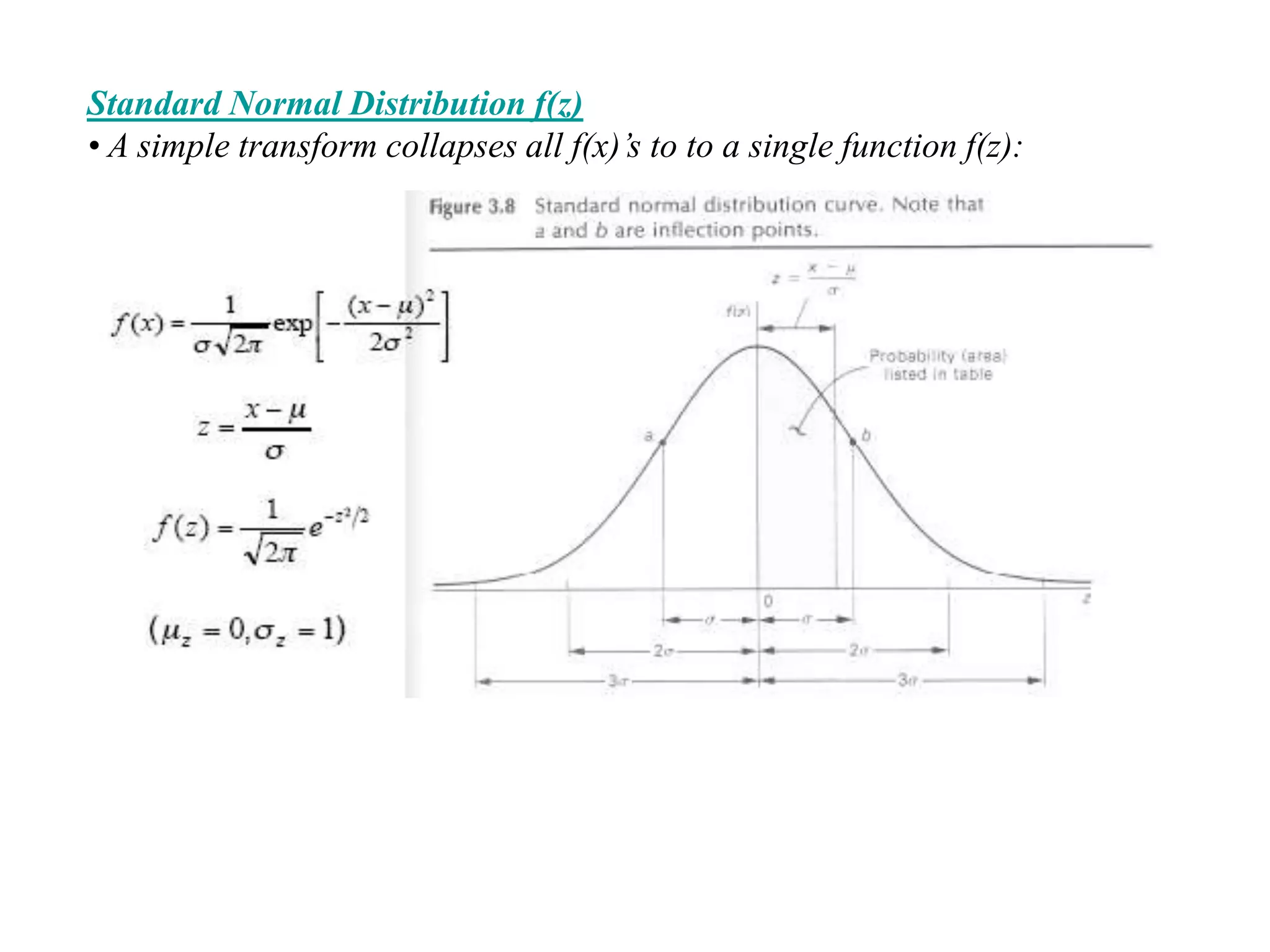
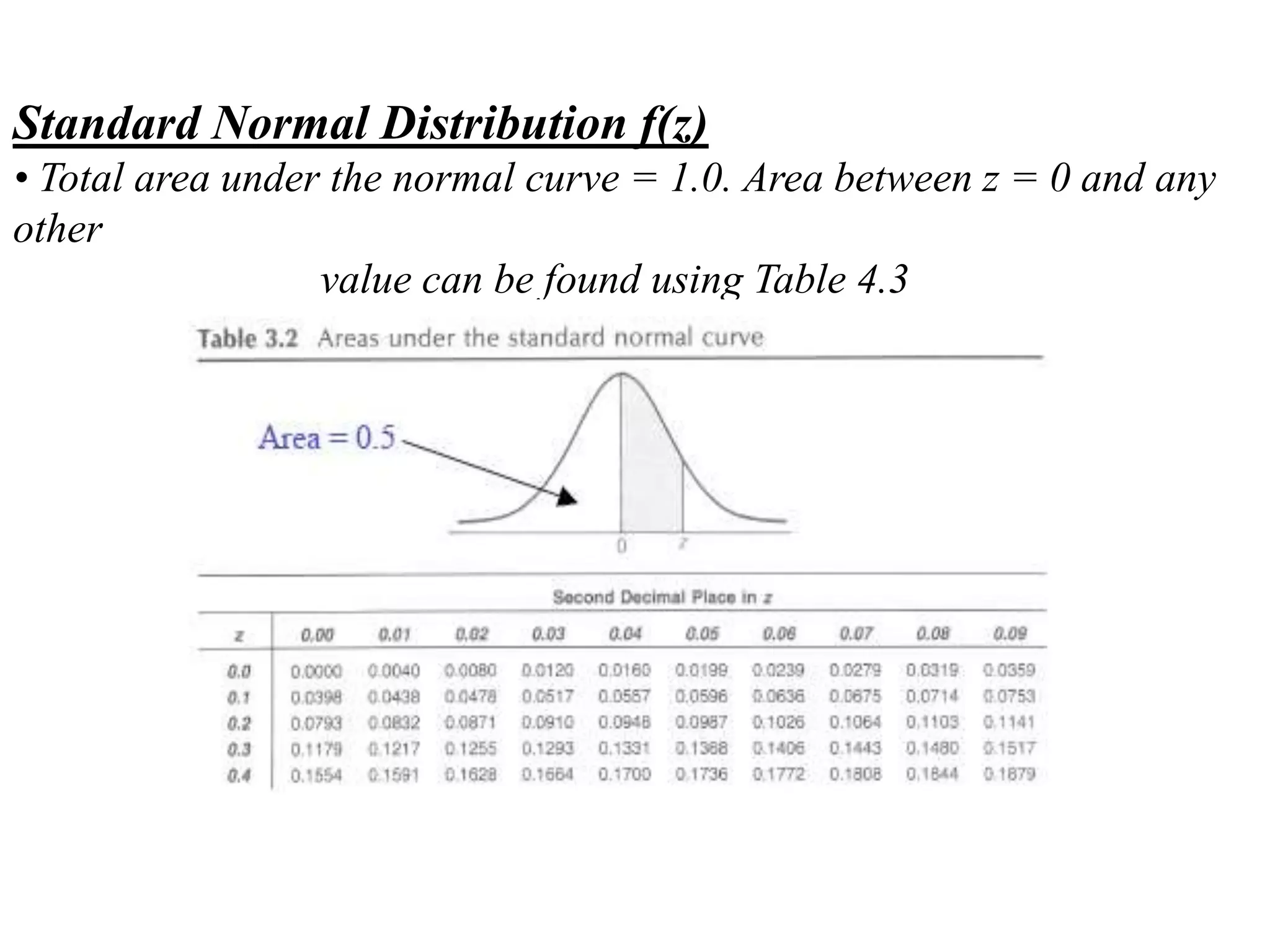


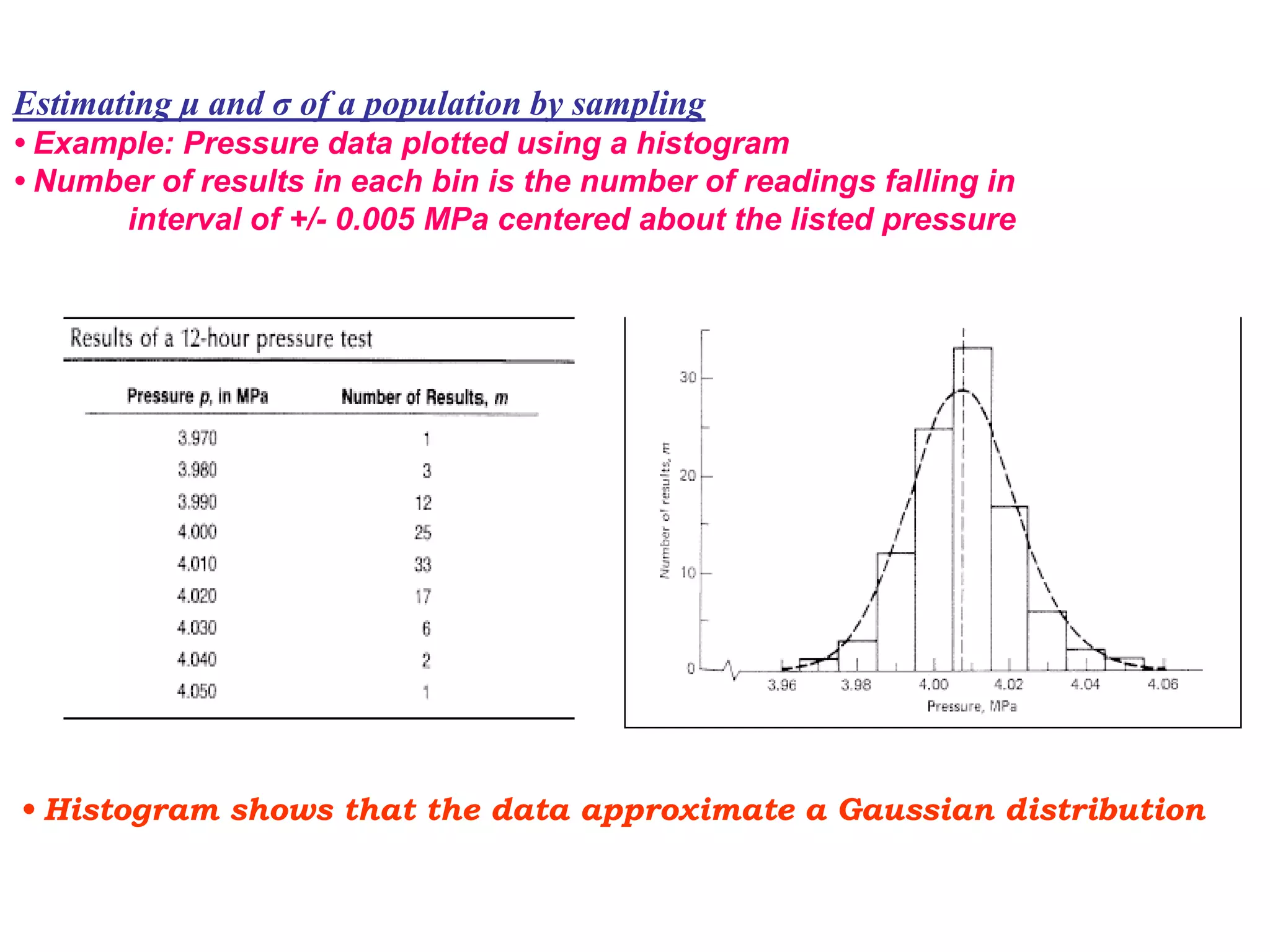




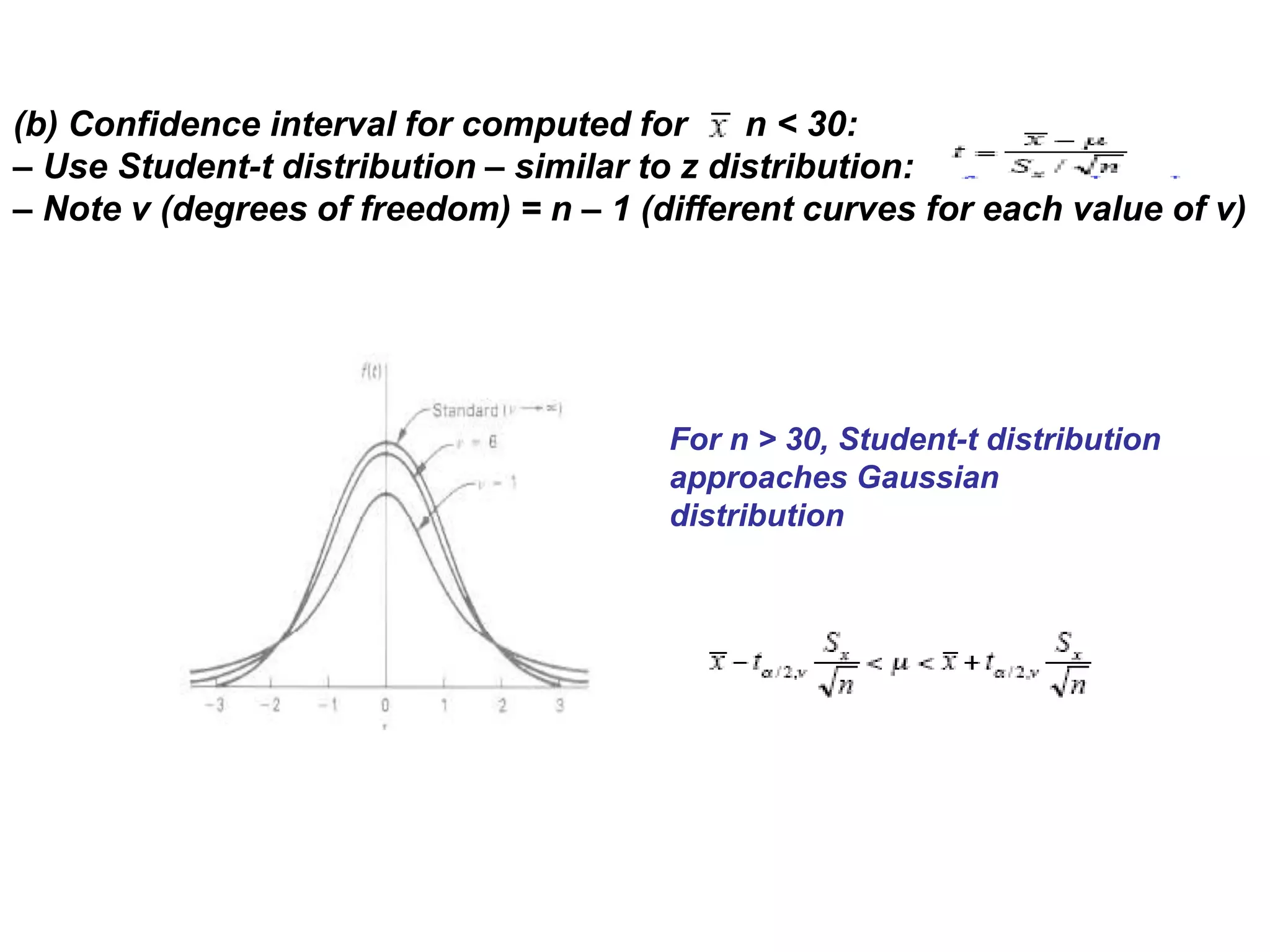



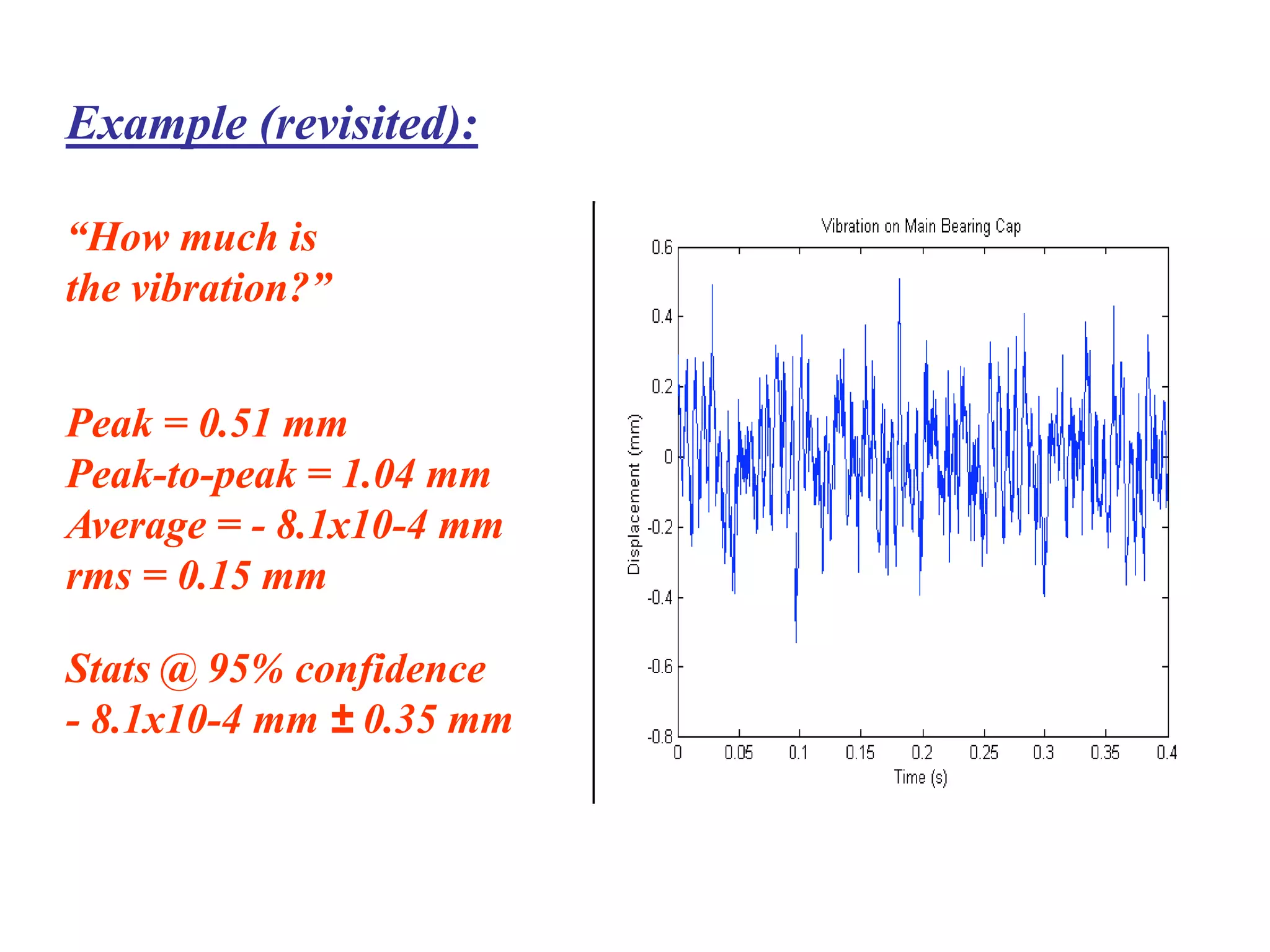





The document discusses measurement error and uncertainty. It explains that total error is the sum of bias error and precision errors. Bias errors are systematic and occur the same way each time, while precision errors are random. Common types of errors include calibration errors, human errors, equipment defects, and environmental factors. Instruments are rated based on their accuracy, precision, resolution, and sensitivity. The normal and standard normal distributions are used to model measurement uncertainty and determine confidence intervals for means and deviations based on sample size and coverage percentage.



































































