Downloaded 59 times

















![23 Preparing OpenSHMEM for Exascale
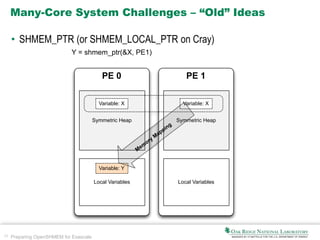
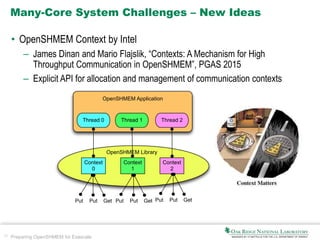
NVSHMEM
u[i][j] = u[i][j]
+ (v[i+1][j] + v[i-1][j]
+ v[i][j+1] + v[i][j+1])/x
16
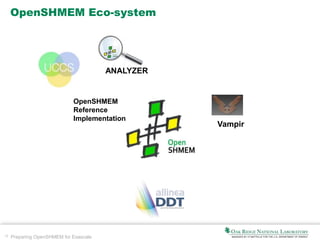
Evaluation results from: “TOC-Centric Communication: a case study with NVSHMEM”,
OUG/PGAS 2014, Shreeram
Potlurihttp://www.csm.ornl.gov/OpenSHMEM2014/documents/NVIDIA_Invite_OUG14.pdf
PRELIMINARY R
D
tl
0"
500"
1000"
1500"
64" 128" 256" 512" 1K" 2K"
Time%per%Step%(usec)%
Stencil%Size%%
tradi/ onal" persistent"kernel"
100"
1000"
p%(usec)%
Tradi. onal" Persistent"Kernel"](https://image.slidesharecdn.com/2ornl-150202174944-conversion-gate02/85/Preparing-OpenSHMEM-for-Exascale-23-320.jpg)
















![45 Preparing OpenSHMEM for Exascale
NVSHMEM Code Example
USING NVSHMEM
Device Code
__global__ void one_kernel (u, v, sync, …) {
i = threadIdx.x;
for (…) {
if (i+1 > nx) {
v[i+1] = nvshmem_float_g (v[1], rightpe)
}
if (i-1 < 1) {
v[i-1] = nvshmem_float_g (v[nx], leftpe)
}
-------
u[i] = (u[i] + (v[i+1] + v[i-1] . . .
contd….
contd….
/*peers array has left and right PE ids*/
if (i < 2) {
nvshmem_int_p (sync[i], 1, peers[i]);
nvshmem_quiet();
nvshmem_wait_until (sync[i], EQ, 1);
}
//intra-process sync
------- //compute v from u and sync
}
}
19
Evaluation results from: “TOC-Centric Communication: a case study with NVSHMEM”,
OUG/PGAS 2014, Shreeram
Potlurihttp://www.csm.ornl.gov/OpenSHMEM2014/documents/NVIDIA_Invite_OUG14.pdf](https://image.slidesharecdn.com/2ornl-150202174944-conversion-gate02/85/Preparing-OpenSHMEM-for-Exascale-45-320.jpg)

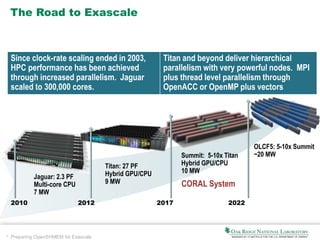
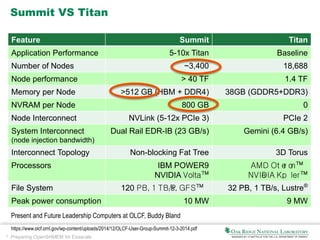
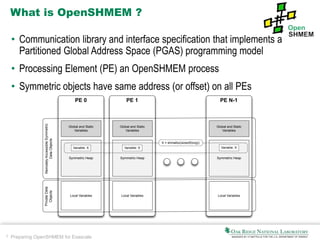
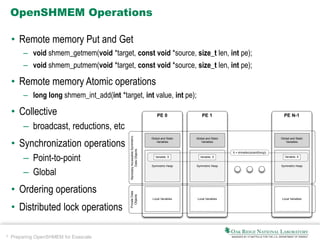
The document discusses the preparation of OpenSHMEM for exascale computing, highlighting the Coral initiative to develop three leadership computers with significant performance enhancements. It explains OpenSHMEM as a one-sided communication library utilizing a partitioned global address space for hybrid architectures, detailing its operations, principles, and evolution. The document also addresses upcoming challenges such as communication across different components, thread safety, and fault tolerance as well as the active research topics within the OpenSHMEM community.
















































































