Download as PDF, PPTX







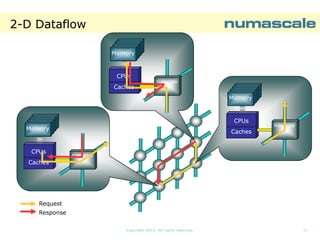





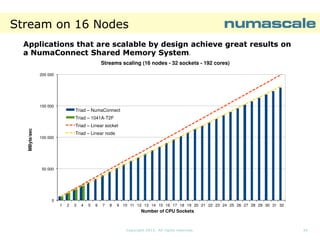

![NPB SP D-class runtime
D1600
1426,8
1400
1200
1000
Runtime [sec]
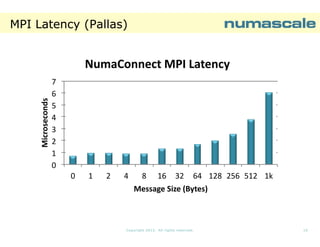
The
overhead
introduced
by MPI is not
needed when
we are
running on a
Shared
Memory
System
NPB-SP NC-OPENMP D-CLASS
8 NumaConnect Nodes: Runtime [sec]
829,64
800
600
546,67
468,91
400
200
0
16
36
64
121
Number of threads
Copyright 2013. All rights reserved.
27](https://image.slidesharecdn.com/numascale-product-ibm-sept13-131014024606-phpapp01/85/Numascale-Product-IBM-27-320.jpg)
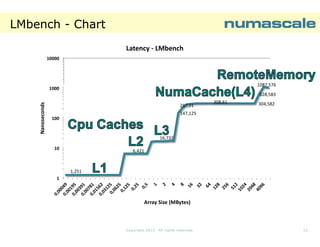
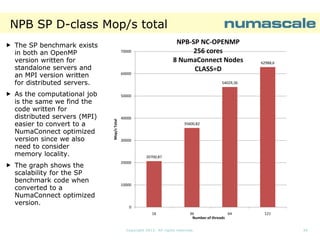
![NPB SP D-class runtime
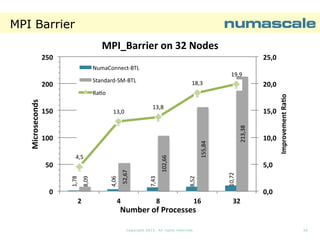
DThe runtime using 121
cores is cut to half
when running on 8
NumaConnect
Nodes, compared to 4
NumaConnect Nodes
The picture on the
right shows that the
The AMD Opteron™
6300 series processor
is organized as a
MultiMulti-Chip Module
(two CPU dies in the
package).
package). Each die
has 8 cores, but 4
FPUs
1200
1000
998,86
800
Runtime (sec)
sec)
The number of cores
pr. FPUs is one when
running on 8
NumaConnect Nodes
and two when running
on 4 NumaConnect
Nodes.
Nodes.
NPB-SP NC-OPENMP D-CLASS
8 NumaConnect Nodes: Runtime [sec]
vs Affinity 121 cores using SP CLASS D
600
475,28
400
200
0
0-127
0-127:2
Affinty
Copyright 2013. All rights reserved.
29](https://image.slidesharecdn.com/numascale-product-ibm-sept13-131014024606-phpapp01/85/Numascale-Product-IBM-29-320.jpg)

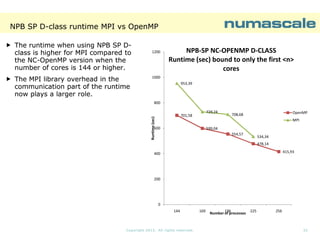
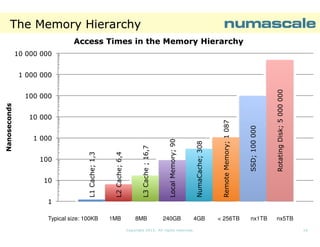
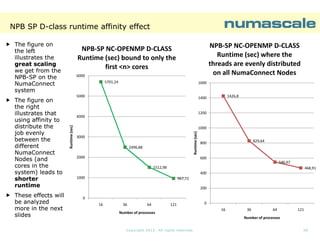
![NPB SP E-class runtime
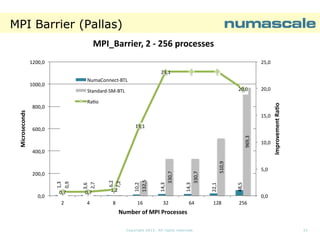
EThe SP benchmark Eclass scales perfectly
from 64 processes (using
(using
affinity 0-255:4) to 121
processes ( using affinity
0-241:2).
Runtime [sec]: NPB-SP NC-OPENMP ECLASS
8 NumaConnect Nodes
18000
General statement:
Larger problems scales
better.
15242,11
14000
12000
Runtime
E-class problems are
more representative for
large shared memory
systems and clusters.
16000
10000
8000
7246,13
6000
4000
2000
0
64
121
Number of processes
Copyright 2013. All rights reserved.
33](https://image.slidesharecdn.com/numascale-product-ibm-sept13-131014024606-phpapp01/85/Numascale-Product-IBM-33-320.jpg)


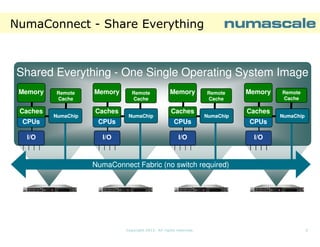
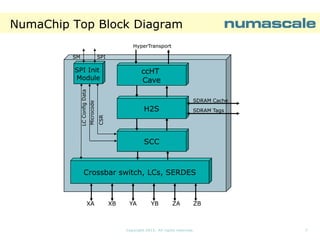
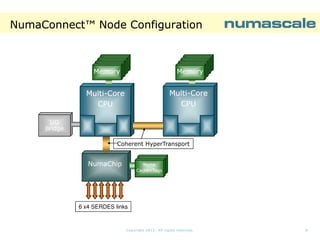
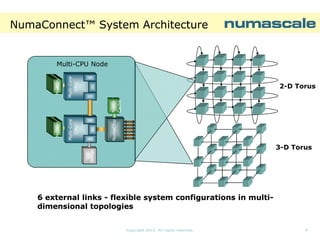
The document describes NumaConnect, a technology that tightly couples commodity servers into a single large system with shared memory, I/O, and a single operating system image. Key features include cache coherent global shared memory accessible by all CPUs, a shared I/O subsystem, and support for various APIs. NumaConnect uses custom NumaChip ASICs and a high-speed interconnect fabric to create a unified memory address space across servers at cluster prices. It can scale to thousands of nodes with hundreds of thousands of cores and petabytes of shared memory. Benchmark results show NumaConnect delivers low latency, high bandwidth, and excellent scaling for applications.














![[2018 GDC] Real-Time Ray-Tracing Techniques for Integration into Existing Ren...](https://cdn.slidesharecdn.com/ss_thumbnails/gdc2018takahiroharada-180330041526-thumbnail.jpg?width=640&height=640&fit=bounds)








































































