Download as PDF, PPTX
![Combining Asynchronous Task Parallelism
and Intel SGX for Secure Deep Learning
19th European Dependable Computing Conference
Leuven, Belgium
10 April, 2024
Xavier Martorel
Universitat Politecnica de Catalanya
Valerio Schiavoni
University of Neuchâtel
Isabelly Rocha
University of Neuchâtel
Pascal Felber
University of Neuchâtel
Marcelo Pasin
University of Neuchâtel
Osman Unsal
Barcelona Super Computing
[Practical Experience Report]](https://image.slidesharecdn.com/edcc24-240411061127-ce607e7c/85/Combining-Asynchronous-Task-Parallelism-and-Intel-SGX-for-Secure-Deep-Learning-1-320.jpg)
![Combining Asynchronous Task Parallelism
and Intel SGX for Secure Deep Learning
19th European Dependable Computing Conference
Leuven, Belgium
10 April, 2024
Xavier Martorel
Universitat Politecnica de Catalanya
Valerio Schiavoni
University of Neuchâtel
Isabelly Rocha
University of Neuchâtel
Pascal Felber
University of Neuchâtel
Marcelo Pasin
University of Neuchâtel
Osman Unsal
Barcelona Super Computing
[Practical Experience Report]](https://image.slidesharecdn.com/edcc24-240411061127-ce607e7c/75/Combining-Asynchronous-Task-Parallelism-and-Intel-SGX-for-Secure-Deep-Learning-1-2048.jpg)




![valerio.schiavoni@unine.ch - SGX-OmpSs - EDCC’24
/11
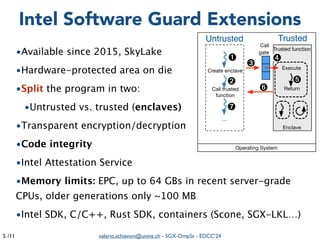
SGX-OmpSs: example
7
1 int SGX_CDECL main(int argc, char*argv[])
2 {
3 ...
4 double *A, B, C = (double *) malloc(DIM * DIM * sizeof(double));
5 fill_random(A); fill_random(B); fill_random(C);
6 for(i=0;i<DIM;i++)
7 for (j = 0; j < DIM; j++)
8 for (k = 0; k < DIM; k++) {
9 // OmpSs pragmas
10 #pragma omp task in(A[i][k], B[k][j]) inout(C[i][j]) no_copy_deps
11 // SGX ecall
12 ecall_matmul(global_eid, &A[i][k], &B[k][j], &C[i][j], BSIZE); }
13 // OmpSs pragmas
14 #pragma omp taskwait //barrier to wait for pending tasks
…
}
•Matrix multiplication, 2 pragmas, 1 sgx ecall](https://image.slidesharecdn.com/edcc24-240411061127-ce607e7c/85/Combining-Asynchronous-Task-Parallelism-and-Intel-SGX-for-Secure-Deep-Learning-7-320.jpg)
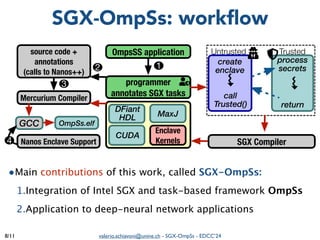

![valerio.schiavoni@unine.ch - SGX-OmpSs - EDCC’24
/11
11
0
100
200
300
400
500
sgx 2 4 8
-100
-80
-60
-40
-20
0
20
40
60
Runtime
[s]
Difference
[%]
YOLO-Pascal LENET-MNIST
Runtime 🏃
•Real-time object detection on the Pascal VOC 2012 dataset
•Hand-written digits, lightweight CNN](https://image.slidesharecdn.com/edcc24-240411061127-ce607e7c/85/Combining-Asynchronous-Task-Parallelism-and-Intel-SGX-for-Secure-Deep-Learning-13-320.jpg)
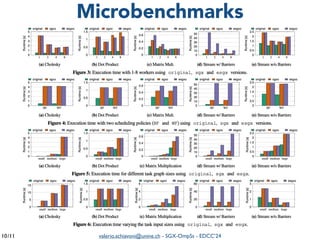
![valerio.schiavoni@unine.ch - SGX-OmpSs - EDCC’24
/11
11
0
100
200
300
400
500
sgx 2 4 8
-100
-80
-60
-40
-20
0
20
40
60
Runtime
[s]
Difference
[%]
YOLO-Pascal LENET-MNIST
Runtime 🏃
•Real-time object detection on the Pascal VOC 2012 dataset
•Hand-written digits, lightweight CNN
baseline, no parallelism](https://image.slidesharecdn.com/edcc24-240411061127-ce607e7c/85/Combining-Asynchronous-Task-Parallelism-and-Intel-SGX-for-Secure-Deep-Learning-14-320.jpg)
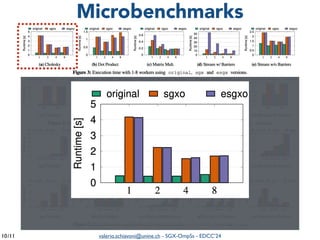
![valerio.schiavoni@unine.ch - SGX-OmpSs - EDCC’24
/11
11
0
100
200
300
400
500
sgx 2 4 8
-100
-80
-60
-40
-20
0
20
40
60
Runtime
[s]
Difference
[%]
YOLO-Pascal LENET-MNIST
Runtime 🏃
•Real-time object detection on the Pascal VOC 2012 dataset
•Hand-written digits, lightweight CNN
baseline, no parallelism
lower is
better](https://image.slidesharecdn.com/edcc24-240411061127-ce607e7c/85/Combining-Asynchronous-Task-Parallelism-and-Intel-SGX-for-Secure-Deep-Learning-15-320.jpg)
![valerio.schiavoni@unine.ch - SGX-OmpSs - EDCC’24
/11
11
0
100
200
300
400
500
sgx 2 4 8
-100
-80
-60
-40
-20
0
20
40
60
Runtime
[s]
Difference
[%]
YOLO-Pascal LENET-MNIST
Runtime 🏃
•Real-time object detection on the Pascal VOC 2012 dataset
•Hand-written digits, lightweight CNN
baseline, no parallelism
lower is
better](https://image.slidesharecdn.com/edcc24-240411061127-ce607e7c/85/Combining-Asynchronous-Task-Parallelism-and-Intel-SGX-for-Secure-Deep-Learning-16-320.jpg)
![valerio.schiavoni@unine.ch - SGX-OmpSs - EDCC’24
/11
12
5
10
15
20
25
30
35
sgx 2 4 8
-100
-80
-60
-40
-20
0
20
40
60
80
100
120
140
Energy
[kJ]
Difference
[%]
YOLO-Pascal LENET-MNIST
Energy🔋🪫
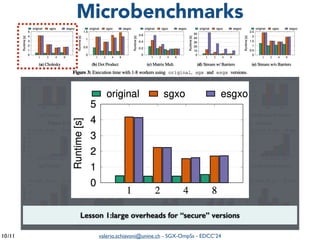
Lesson 5: predicting performances is not easy, must be done on a case-by-case
read paper for 2-4](https://image.slidesharecdn.com/edcc24-240411061127-ce607e7c/85/Combining-Asynchronous-Task-Parallelism-and-Intel-SGX-for-Secure-Deep-Learning-17-320.jpg)
![valerio.schiavoni@unine.ch - SGX-OmpSs - EDCC’24
/11
12
5
10
15
20
25
30
35
sgx 2 4 8
-100
-80
-60
-40
-20
0
20
40
60
80
100
120
140
Energy
[kJ]
Difference
[%]
YOLO-Pascal LENET-MNIST
Energy🔋🪫
Lesson 5: predicting performances is not easy, must be done on a case-by-case
read paper for 2-4](https://image.slidesharecdn.com/edcc24-240411061127-ce607e7c/85/Combining-Asynchronous-Task-Parallelism-and-Intel-SGX-for-Secure-Deep-Learning-18-320.jpg)


The document summarizes a presentation on combining asynchronous task parallelism and Intel SGX for secure deep learning. It discusses using Intel SGX to securely execute portions of deep learning tasks and an OpenMP-based framework called SGX-OmpSs to parallelize tasks across CPU cores. Evaluation shows SGX-OmpSs can accelerate two deep learning models for object detection and handwritten digit recognition, reducing runtime by up to 94% and energy usage by up to 92% compared to a non-parallel baseline. The approach provides an easy way to develop secure applications using asynchronous task parallelism with minimal effort to port to SGX.



























![From Draft to DSN - How to Get your Paper In [DSN 2025 Doctoral Forum Keynote]](https://cdn.slidesharecdn.com/ss_thumbnails/25-dsnphdforum-keynote-250703114856-4ef7c054-thumbnail.jpg?width=640&height=640&fit=bounds)

































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)
