Download as PDF, PPTX










![21
Deep Learning – Paper 2
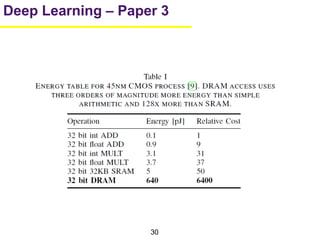
[7] Mark Horowitz. Energy table for 45nm process, Stanford VLSI wiki
Mark Horowitz Professor of Electrical Engineering and Computer Science
VLSI, Hardware, Graphics and Imaging, Applying Engineering to Biology](https://image.slidesharecdn.com/2016-05-25-deep-learning-03-160531032409/85/Recent-developments-in-Deep-Learning-21-320.jpg)
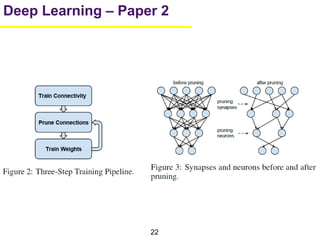
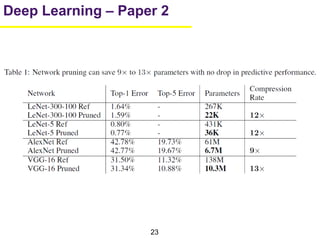


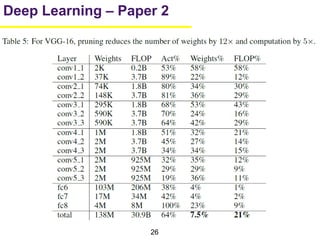
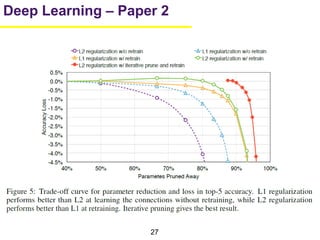


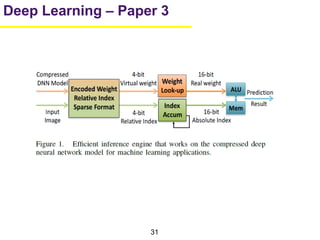

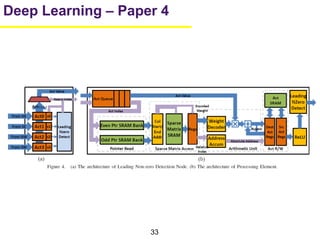

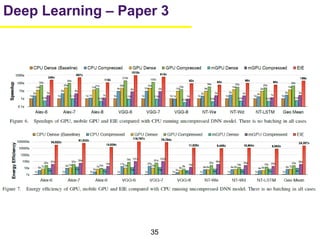
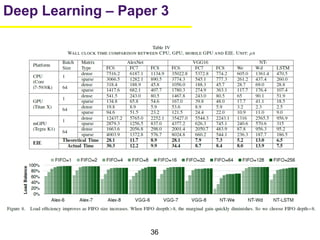
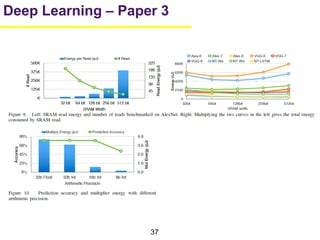
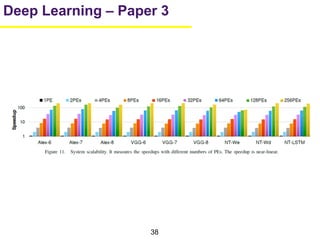
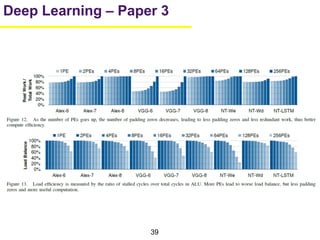
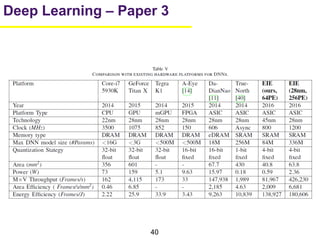




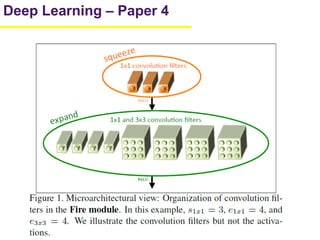
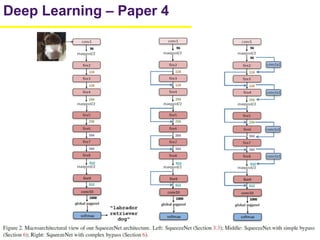
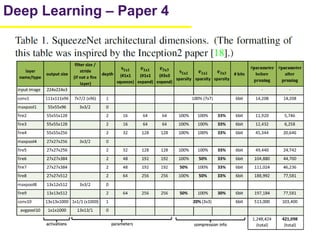
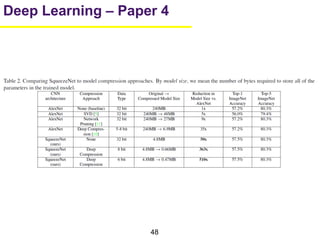

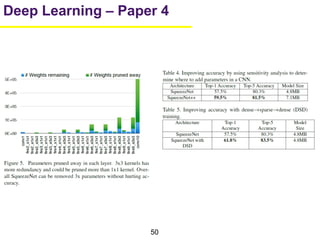


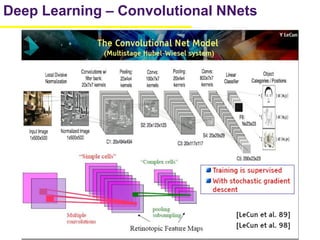
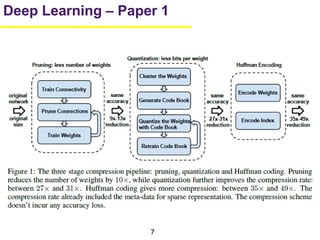
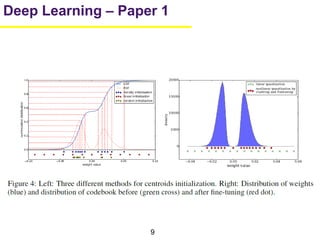
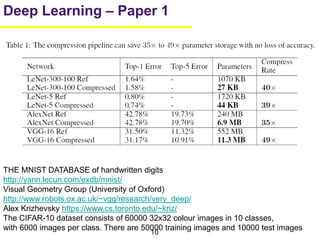
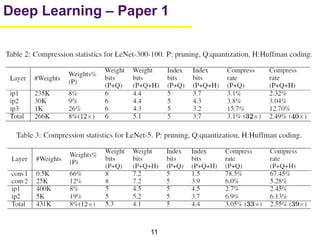
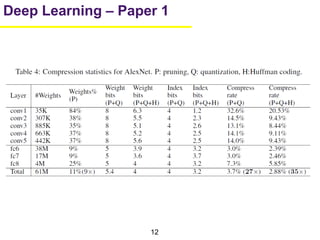
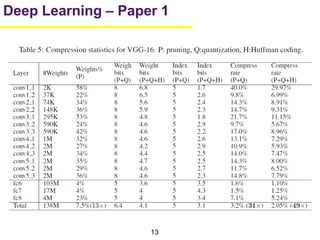
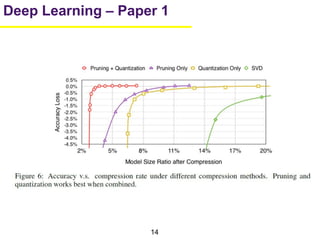
1. The document summarizes several papers on deep learning and convolutional neural networks. It discusses techniques like pruning weights, trained quantization, Huffman coding, and designing networks with fewer parameters like SqueezeNet. 2. One paper proposes techniques to compress deep neural networks by pruning, trained quantization, and Huffman coding to reduce model size. It evaluates these techniques on networks for MNIST and ImageNet, achieving compression rates of 35x to 49x with no loss of accuracy. 3. Another paper introduces SqueezeNet, a CNN architecture with AlexNet-level accuracy but 50x fewer parameters and a model size of less than 0.5MB. It employs fire modules with 1x1 convolutions to





















































































