Download as PDF, PPTX






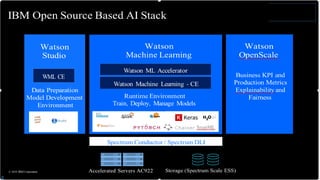



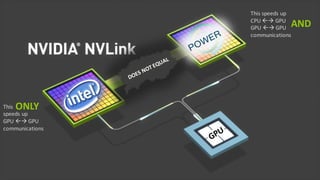


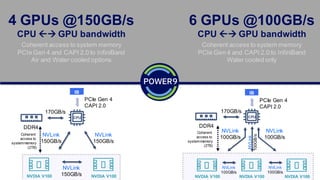





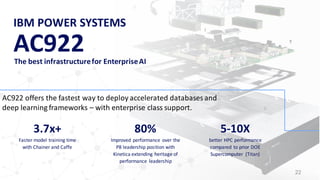

The document introduces the IBM Power Systems AC922 system as a cognitive infrastructure for enterprise AI. Some key points: - Existing server infrastructures are not well-suited for modern AI workloads and large-scale cognitive data volumes. - The AC922 is designed specifically for AI with accelerated computing capabilities like GPUs and fast interconnects to enable faster model training, larger models, and quicker time to value from AI projects. - Features include the POWER9 processor, high-bandwidth NVLink connections between CPUs and multiple GPUs, support for large memory and accelerated databases/frameworks, and scaling to warehouse-sized deployments through distributed deep learning.











































































