Awareness and Trendin ICRA2020
・From Keywords in Proceedings
・From Awards
・From Plenary and Keynote
・From Session
・From All
Award, Plenary, Keynote,Sessionは全てではなく,特定の部分となります
13
14.
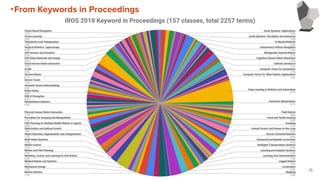
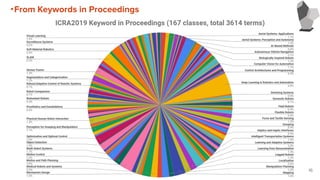
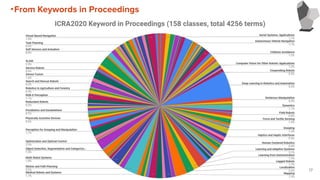
From Keywords inProceedings
・IROS2019, ICRA2019,2020におけるProceedingで使用されているKeywordを集計
・集計した結果より、傾向を考察する
・Top Keywordの表のPercentageには次の式を使用
Percentage =
14
Number of Proceeding including Each Keyword
Number of Total Proceedings
x 100 [%]
25
・ Service Robots
-Online Trajectory Planning through Combined Trajectory Optimization and Function Approximation:
Application to the Exoskeleton Atalante
- Human-Centric Active Perception for Autonomous Observation
- Active Reward Learning for Co-Robotic Vision Based Exploration in Bandwidth Limited Environments
・ Medical Robotics
- Fault Tolerant Control in Shape-Changing Internal Robots
- Swing-Assist for Enhancing Stair Ambulation in a Primarily-Passive Knee Prosthesis
- A Multilayer-Multimodal Fusion Architecture for Pattern Recognition of Natural Manipulations in
Percutaneous Coronary Interventions
・ Robot Mechanisms
- Design of a Roller-Based Dexterous Hand for Object Grasping and Within-Hand Manipulation
- Swing-Assist for Enhancing Stair Ambulation in a Primarily-Passive Knee Prosthesis
- Asynchronous and Decoupled Control of the Position and the Stiffness of a Spatial RCM Tensegrity Mechanism for Needle
Manipulation
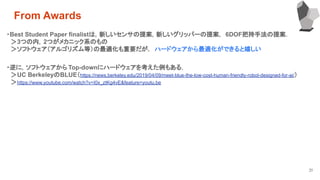
From Awards
26.
26
- Form2Fit: LearningShape Priors for Generalizable Assembly from Disassembly
- Deep Visual Heuristics: Learning Feasibility of Mixed-Integer Programs for Manipulation Planning
- Securing Industrial Operators with Collaborative Robots: Simulation and Experimental Validation for a Carpentry Task
・Automation
・ Human-Robot Interaction (HRI)
・ Multi-Robot Systems
- Preference-Based Learning for Exoskeleton Gait Optimization
- Perception-Action Coupling in Usage of Telepresence Cameras
- Human Interface for Teleoperated Object Manipulation with a Soft Growing Robot
- Efficient Large-Scale Multi-Drone Delivery Using Transit Networks
- Efficient Multi-Agent Trajectory Planning with Feasibility Guarantee Using Relative Bernstein Polynomial
- Distributed Multi-Target Tracking for Autonomous Vehicle Fleets
From Awards
27.
27
・Unmanned Aerial Vehicles
・RobotVision
・Robot Manipulation
- Design and Autonomous Stabilization of a Ballistically Launched Multirotor
- A Morphable Aerial-Aquatic Quadrotor with Coupled Symmetric Thrust Vectoring
- Nonlinear Vector-Projection Control for Agile Fixed-Wing Unmanned Aerial Vehicles
- OmniSLAM: Omnidirectional Localization and Dense Mapping for Wide-Baseline Multi-Camera Systems
- Metrically-Scaled Monocular SLAM Using Learned Scale Factors
- Graduated Non-Convexity for Robust Spatial Perception: From Non-Minimal Solvers to Global Outlier Rejection
- 6-DOF Grasping for Target-Driven Object Manipulation in Clutter
- Tactile Dexterity: Manipulation Primitives with Tactile Feedback
- Design of a Roller-Based Dexterous Hand for Object Grasping and Within-Hand Manipulation
From Awards
28.
28
・Cognitive Robotics
・Best StudentPaper Award
・Best Conference Paper Award
- Semantic Linking Maps for Active Visual Object Search
- Adversarial Skill Networks: Unsupervised Robot Skill Learning from Video
- Transient Behavior and Predictability in Manipulating Complex Objects
- Design of a Roller-Based Dexterous Hand for Object Grasping and Within-Hand Manipulation (robot manipulation)
- An ERT-Based Robotic Skin with Sparsely Distributed Electrodes: Structure, Fabrication, and DNN-Based Signal Processing
- 6-DOF Grasping for Target-Driven Object Manipulation in Clutter
- Preference-Based Learning for Exoskeleton Gait Optimization (HRI)
- Design of a Roller-Based Dexterous Hand for Object Grasping and Within-Hand Manipulation
- Prediction of Human Full-Body Movements with Motion Optimization and Recurrent Neural Networks
From Awards
29.
29
・In-hand Manipulation(メカ・アルゴリズム)がかなり盛り上がっている
Next-Picking的な問題への取り組みが盛んになってきたという印象
From Awards
ばら積み物体のピッキングより、もう少し工夫した作業を例題にしている
・DeepVisual Heuristics: Learning Feasibility of Mixed-Integer Programs for Manipulation Planning
→ 二台のロボットアームで、乱雑に置かれた物体から目的の物体をどちらがどのように掴むか
実現可能性を学習
・Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly
→ ピッキングから組みつけ(kit assembly)までを、様々な物体・組み付け対象に対して学習ベースで扱えるようにしている
・現実的なものが選ばれている
・特にservice robotやHRI関係では4,5年前くらいまでは,まだ家庭内とかサービス現場が展開対象のメイン
だったが,リハビリや極限環境等、テレオペレーション等、ロボットの利用が現実的になってきているとこ
ろでの活用を想定+技術的ポイント があるものという感じ
30.
30
・Best Paper Winnerは,下半身外骨格を用いた方向の最適化手法の提案.インタラクション付きの学習で
ユーザに合わせた学習が可能.
From Awards
・ Conginitive RobotsでLable-freeなVideoを用いたRL手法の提案.Label-freeなVideoを用いて,
複数のタスク(今回の提案では,シンプルなタスク, Stackとか)の実行を見越している?
・Adversarial Skill Networks: Unsupervised Robot Skill Learning from Video
→ ラベル付けされていないマルチビュー動画からタスクに依存しないスキル埋め込み空間を学習する
・ 同じくConginitive Robotsで,エリア内の物体探索を,ランドマークと対象物体の空間関係に関する背景
知識を活用して見つける手法が提案されている
>RLの学習コスト削減
・Semantic Linking Maps for Active Visual Object Search
→ セマンティックリンキングマップ(SLiM)モデルを導入することで、アクティブな視覚的物体探索戦略手法を提案
>Affordanceを空間探索で使用しているイメージ(把持での Affordanceは物体の使用方法を考慮した把持
位置検出が可能.それに対して,今回は物体の置いてあると想定される位置を考慮して探索する)
From Plenary andKeynote
・Planaryからは次のものを紹介
Yann LeCun ーSelf-Supervised Learning & World Modelsー
・Keynoteからは,次のものを紹介
Pieter Abbeel
ーCan Deep Reinforcement Learning from pixels be made
as efficient as from state?
32
33.
From Plenary andKeynote
・Yann LeCunーSelf-Supervised Learning & World Models
33
人間や動物が新しいタスクを効率的に学習できるのは、知覚世界や運動世界の優れた表現や予測モデルを学習する
能力があるからではないかと考えられている.この能力を再現するには?
方法の1つとして,入力の他の部分から入力の一部を予測する自己教師付き学習(SSL)
34.
From Plenary andKeynote
・Yann LeCunーSelf-Supervised Learning & World Models
34
・教師あり学習を使用した認識は上手くいく
➔ただし,豊富にラベル付きデータがあったとしても,それが十分なデータとは限らない
・深層強化学習を使用した動作生成も良い
➔シミュレーションでは良い感じだけど,現実では遅すぎる
1.少ないラベル付きデータor 少ないトレーニングで十分な学習ができるようにする
→ 自己教師学習などを使って,足りない部分を補う
2.推論の学習(Learning to reason)
→ 勾配に基づく学習と推論を両立させる
3.連続で複雑な動作を計画する為の学習
→ 動作計画の階層的表現を学習する
・現在の課題をまとめると3つの課題で表現される
From Plenary andKeynote
・Yann LeCunーSelf-Supervised Learning & World Models
36モデルベース強化学習とEnergy Based Model(CORL2019の紹介あり)
https://www.slideshare.net/DeepLearningJP2016/dlenergy-based-model
・Energy-based のSSLは,共通認識の土台にできる?
➔Animalやhumanは観察からSSLしている.
➔知識の蓄積が共通認識の土台であれば,可能性はある?
・SLやRLをスケーリングしても,人間レベルのAIにするのは難しいだろう
37.
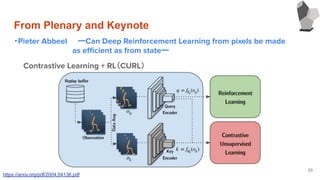
From Plenary andKeynote
・Pieter Abbeel ーCan Deep Reinforcement Learning from pixels be made
as efficient as from stateー
37
・状態ベースのRLとPixelベースのRLを比較した時,PixelベースのRLは状態ベースのRLと同等 の性
能を出すことが可能なのか?
➔状態ベースのD4PGとPixelベースのD4PGを比較
➔同じタスクを解く為に,Pixelベースの方が50Mステップ以上必要になった
➔https://deepmind.com/research/publications/deepmind-control-suite
➔Pixelベースでもより良い特徴量を獲得したい
※PixelベースのRLでマニピュレーション(Plenary中では紹介されていないです)
➔https://arxiv.org/abs/1803.09956
➔https://arxiv.org/abs/1909.04840
➔https://arxiv.org/abs/1909.11730
38.
From Plenary andKeynote
・Pieter Abbeel ーCan Deep Reinforcement Learning from pixels be made
as efficient as from stateー
38
・より良い特徴量を獲得する為には?
➔Contrastive Learning + RL(CURL)とか良いかも
➔Contrastive Learningは,画像特徴量を取得する手法
※Contrastive Learning
➔https://arxiv.org/abs/1905.09272
➔https://arxiv.org/abs/2002.05709
➔https://arxiv.org/abs/1911.05722
➔https://ai-scholar.tech/articles/contrastive-learning/supervised-contrastive-learning
※CURL: Contrastive Unsupervised Representations for
Reinforcement Learning
➔https://arxiv.org/pdf/2004.04136.pdf
39.
From Plenary andKeynote
・Pieter Abbeel ーCan Deep Reinforcement Learning from pixels be made
as efficient as from stateー
39
Contrastive Learning + RL(CURL)
https://arxiv.org/pdf/2004.04136.pdf
40.
From Plenary andKeynote
・Pieter Abbeel ーCan Deep Reinforcement Learning from pixels be made
as efficient as from stateー
40
・CURLは上手くいった?
➔DeepMind Control SuiteとAtariに対して実行
➔SACと比較して,上手くいく
➔Atariの人間のスコアと比較してスコアを上回るのは2つのみ
41.
From Plenary andKeynote
・Pieter Abbeel ーCan Deep Reinforcement Learning from pixels be made
as efficient as from stateー
41
・他のより良い特徴量を求める方法はある?
➔RL with Augmented Data(RAD) も良いかも
➔Augumentationには、Crop, Flip, Color jitter, Random Convとか含まれている
➔CORLより上手くいく
※Reinforcement Learning with Augmented Data
➔https://arxiv.org/abs/2004.14990
42.
From Plenary andKeynote
・Pieter Abbeel ーCan Deep Reinforcement Learning from pixels be made
as efficient as from stateー
42
Augmented Data
https://arxiv.org/abs/2004.14990
43.
From Plenary andKeynote
・Pieter Abbeel ーCan Deep Reinforcement Learning from pixels be made
as efficient as from stateー
43
・CURLとRADのどちらが良かった?
➔RADの方が,CURLと比較して性能がより出ていた
・報酬関数が無くても,CURLは適用できる
➔CURLは複数のタスク向け
・Contrastive representation Learning methodを適用するのに足りないものは何か?
➔Contrastive representationは,時間要素が含まれていない.
44.
From Session
44
・Sessionでは,次のSessionを調査
― GraspingⅠ,Ⅱ, Ⅲ, Ⅳ
― Grippers and Other End-EffectorsⅠ, Ⅱ
― Perception for Grasping and ManipulationⅠ, Ⅱ, Ⅲ, Ⅳ, Ⅴ
― Path Planning for Multiple Mobile Robots or AgentsⅠ, Ⅱ
― reinforcement Learning for RoboticsⅠ, Ⅱ
― Mobile ManipulatorⅠ
― Industrial RobotsⅠ, Ⅱ
― ManipulationⅠ, Ⅱ
― Dexterous ManipulationⅠ, Ⅱ
― Manipulation PlanningⅠ, Ⅱ
・これらのSessionにおける傾向をまとめる
45.
From Session
45
・ GraspingⅠ,Ⅱ, Ⅲ, Ⅳ
・ Grippers and Other End-EffectorsⅠ, Ⅱ
・ Perception for Grasping and ManipulationⅠ, Ⅱ, Ⅲ, Ⅳ, Ⅴ
・Deepでのロバスト性・汎用性を向上させる ”や”実用的な問題設定で使用する ”が印象としてある
・Online Learning of Object Representations by Appearance Space Feature Alignment
→ 認識のロバスト性を向上させる.複数視点間でも,認識に差が出ない, 認識結果の信頼性向上
・Single Shot 6D Object Pose Estimation
→ 汎用性を持たせるように考える.学習が簡単・速い,Novel・多品種な物体対応.
・Penaryでもあったが,自己教師x強化学習の例が出ている.もしくは, 学習コストの削減(学習をシンプル
にする)を目指した手法の提案
・把持状態の推定がモデルでは難しいところは深層学習で解決する. 6DOFピッキングに関しては FC-GQ-CNN
と比較して、それを上回ったら OKみたいな印象
・Motion2Vec: Semi-Supervised Representation Learning from Surgical Videos ( Deep Learning in Robotics and Automation )
→ ビデオ観測から深い埋め込み特徴空間を学習する
46.
From Session
46
・ GraspingⅠ,Ⅱ, Ⅲ, Ⅳ
・ Grippers and Other End-EffectorsⅠ, Ⅱ
・ Perception for Grasping and ManipulationⅠ, Ⅱ, Ⅲ, Ⅳ, Ⅴ
・アイデアはシンプルでも,システムとして確立しているもの は6DOFピッキングでもかなり出ている.
ex) 把持候補を生成する部分は既存のもの (4DOF把持の手法)を使用し,事前の画像の段階で工夫すること
で,6DOF把持に拡張する.
・Beyond Top-Grasps Through Scene Completion
→ One-shotのpoint cloudから3次元シーンを復元し,様々な方向から見たDepth画像を元に把持候補を決定する.
・Hierarchical 6-DoF Grasping with Approaching Direction Selection
→ サンプリングされたアプローチ方向を最適化することによって,4DOF把持から6DOF把持に拡張する.
・6DOF把持で問題となる把持候補が現実に適用可能かどうか (ロボットアームの手先が届くこと)
を考慮している.
・Learning to Generate 6-DoF Grasp Poses with Reachability Awareness
→ 6DOF把持候補生成の後に,アームの手先が到達可能かどうかをチェックしたうえで最適な候補を決定する.
47.
From Session
47
・ PathPlanning for Multiple Mobile Robots or AgentsⅠ, Ⅱ
・ Mobile ManipulatorⅠ
・ Industrial RobotsⅠ, Ⅱ
・リッチなフレームワークとして提案(認識 x 軌道計画 x 最適化 x 複数種類のタスク実行)
・A Mobile Manipulation System for One-Shot Teaching of Complex Tasks in Homes
→ 複雑で複数のタスクを1つのロボットで学習する
→ 学習コストを減らす為に,人間が装着したVRでの操作をTeachingとして使用する
・Industrial Robotsセッションでは、アプリケーション向けのシステムの完成度が高いと、コアが
すごく尖ってなくても(妥当な技術)通っている なあという印象
・Path Planning for Multiple Mobile Robots or Agentsでのロボットの数は,複数個 or 数十個みたいな感じ.
複数ロボットのナビゲーションに深層強化学習を使う手法も出ている. (単体のagentの最適化➔集団の
agentの最適化)
48.
From Session
48
・ ManipulationⅠ,Ⅱ
・ Dexterous ManipulationⅠ, Ⅱ
・ Manipulation PlanningⅠ, Ⅱ
・精度が必要な操作に対して,これまではモデル化を使うものが多かったが,学習系を使用し解決するものが
登場している(機械組立などの複雑なタスクへの応用が期待される)
・Learning Precise 3D Manipulation from Multiple Uncalibrated Cameras
→ 複数視点のカメラ画像のみを用いて,Insertionなどの精度が必要なタスクを行う.
・Surfing on an uncertain edge: Precision cutting of soft tissue using torque-based medium classification
→ 果物の皮と身を分けるカッティングのタスクに対して,デモンストレーションの力情報から軌道を作る.
・しかし依然として,複雑な問題にはモデル化を中心にタスクを遂行している手法もたくさんあり,学習でし
か解決出来ないということは無い(適材適所で使用するか,モデルと学習を組み合わせるか)
・Tethered Tool Manipulation Planning with Cable Maneuvering
→ 双腕でケーブルがついたツールを使う時に,絡まりを防ぐようにケーブルを操作する.
・Where to relocate?: Object rearrangement inside cluttered and confined environments for robotic manipulation
→ 障害物なる物体を移動させる場所を決定する方法.移動回数を最小化する.
Towards Plan Transformationsfor Real-World Mobile Fetch and Place
Gayane Kazhoyan, Arthur Niedzwiecki and Michael Beetz
- 一般的に、ある動作がロボットおよび環境の空きリソースを未使用のままにしてしまう可能性がある理由は、オブジェクトのサイズ、重
量、正確な位置、空間内の他の障害物オブジェクトの位置など、動作の正確なパラメータの多くが、ロボット動作仕様が作成された時
点では未知であるからである . そのため、ロボットは実行中に行動を変更し、現在の状況に合わせて行動を適応させる必要がある.
- そこで,実行時にロボットの行動をコード置換を用いて自律的に変形させることで,実世界のロボットの計画実行を改善し,より良い
性能を実現するためのアプローチを提示する.
- ロボットの動作を解析し、あらゆるシナリオやコンテキストの範囲で変形させるために、前作 [11]で紹介したタスクツリーのデータ構造
を利用している.タスクツリーは実行された計画の実行時表現であり、計画が呼び出されたパラメータを含む計画に関連するすべて
の情報を含む。実行時には、実行されたアクションごとに、タスクツリー内にノードが自動的に作成され、プラン内で実行されたすべて
のサブプランの子ノードへの参照が含まれる.
まとめた人:souta hriose
https://arxiv.org/pdf/1812.08226.pdf
53.
Planning an Efficientand Robust Base Sequence for a Mobile
Manipulator Performing Multiple Pick-and-place Tasks
Jingren Xu, Kensuke Harada, Weiwei Wan, Toshio Ueshiba and Yukiyasu Domae
- 移動マニピュレータを用いて異なるトレイに配置された複数物体を効率良くPick-and-Placeする手法の提案
- 事前に計算されたreachability databaseに基づいて、衝突のないIKの解を探索するための決定論的手法を提案し、その
後、実現可能なbase位置集合を決定する.
- 複数のトレイにアクセス可能なbase位置は各トレイのbase位置の積集合として算出している.積集合をbase位置の目標とす
ることによって,base位置の移動を最小化することが可能.
- また,各トレイの物体にアクセスできるIKの解はクエリとして,内部に保持している為,高速な演算が可能になっている.
まとめた人:souta hriose
https://arxiv.org/abs/2001.08042
54.
Towards Mobile Multi-TaskManipulation in a Confined and Integrated
Environment with Irregular Objects
Zhao Hany, Jordan Allspaw, Gregory LeMasurier, Jenna Parrillo, Daniel Giger,
S. Reza Ahmadzadeh and Holly A. Yanco
- ICRA2019で開催されていたFetchを使ったCompetitionに参加した際の手法紹介(won 2nd place)
- Competitionでは,ギアボックスのassembleを,タスクとして設定していた.
- softwareにはROSのNavigation StackやPCLを用いて構築
- Assembly taskは,20回行い,13回成功.結果から,小さい部品ではPoint Cloudのノイズにより,上手く掴めない場合や大
きい部品でもOcclusionによりCollisionが発生してしまうことが分かった.
まとめた人:souta hriose
https://arxiv.org/abs/2003.01776
55.
A Mobile ManipulationSystem for One-Shot Teaching of Complex
Tasks in Homes
Max Bajracharya , James Borders , Dan Helmick , Thomas Kollar
Michael Laskey , John Leichty , Jeremy Ma , Umashankar Nagarajan , Akiyoshi Ochiai
Josh Petersen , Krishna Shankar , Kevin Stone , Yutaka Takaoka
- 家での複雑なタスクをこなす事を目的とした移動マニピュレータの提案.
- 提案する移動マニピュレータでは, 31自由度(頭で2,腕がそれぞれ 7で2本,胴体が5,グリッパーが2,baseの移動で8)になってい
る.計算リソースには, 18coreのi9とTitan Vが搭載されている.
- Primitive actionはパラメータ化されており, grasp, lift, place, pull, retract, wipe , joint-move, direct-controlが含まれている
- タスクにおけるTeachingでは,操作者がVRを使用して行っている.
- 検証では,冷蔵庫からボトルの取り出し,洗浄機からカップの取り出し,複数物体の placeを2つの家それぞれ 10回試行した.60回の
試行を行い,85%の成功率だった. https://arxiv.org/abs/1910.00127
まとめた人:souta hriose
UBAT: On JointlyOptimizing UAV Trajectories and Placement of
Battery Swap Stations
Myounggyu Won
- UAVの軌道と充電ステーションの配置を最適化するフレームワークの提案.
- 配置問題がNP困難なtravelling salesperson problemであるとし,提案手法では ant colony optimization (ACO) を使用している.
- シミュレーションでは、提案手法が UAVの軌道生成の多目的最適化を効果的に実行し,軌道と配置をそれぞれ真の最適解の 8.3%と
7.3%以内にすることを実現した.
まとめた人:souta hriose
https://arxiv.org/abs/1910.06089
58.
Efficient Multi-Agent TrajectoryPlanning with Feasibility Guarantee
using Relative Bernstein Polynomial
Jungwon Park, Junha Kim, Inkyu Jang and H. Jin Kim
- グリッドベースと最適化ベースの利点を組み合わせた、障害物環境下での複数ドローン(クアッドローター)の効率的な軌道計画アル
ゴリズムを提示.
- 提案手法では,スケーラビリティ向上の為に、ダミーエージェントを用いた逐次最適化手法を採用し、バーンスタインの凸包特性と相
対バーンスタイン多項式を利用して、非凸型の衝突回避制約を凸型に置き換えている.
- シミュレーションでは i7@ 3.60GHzのCPUと16GのRAMを用いて,64エージェントに対して平均 6.36秒で軌道計算を行い,筆者らの
先行研究と比較して目的コストを 50%以上削減した.
- project code : https://github.com/qwerty35/swarm_simulator
まとめた人:souta hriose
https://arxiv.org/abs/1909.10219
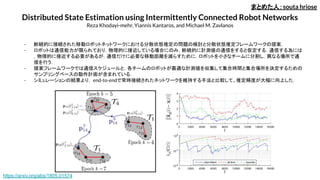
Distributed State Estimationusing Intermittently Connected Robot Networks
Reza Khodayi-mehr, Yiannis Kantaros, and Michael M. Zavlanos
まとめた人:souta hriose
- 断続的に接続された移動ロボットネットワークにおける分散状態推定の問題の検討と分散状態推定フレームワークの提案.
- ロボットは通信能力が限られており,物理的に接近している場合にのみ,断続的に計測値の通信をすると仮定する.通信する為には
,物理的に接近する必要があるが,通信だけに必要な移動距離を減らすために,ロボットを小さなチームに分割し,異なる場所で通
信を行う.
- 提案フレームワークでは通信スケジュールと,各チームのロボットが最適な計測値を収集して集合時間と集合場所を決定するための
サンプリングベースの動作計画が含まれている.
- シミュレーションの結果より, end-to-endで常時接続されたネットワークを維持する手法と比較して、推定精度が大幅に向上した.
https://arxiv.org/abs/1805.01574
61.
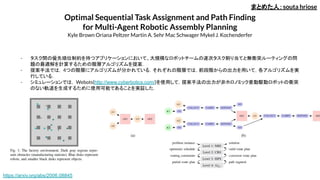
Optimal Sequential TaskAssignment and Path Finding
for Multi-Agent Robotic Assembly Planning
Kyle Brown Oriana Peltzer Martin A. Sehr Mac Schwager Mykel J. Kochenderfer
- タスク間の優先順位制約を持つアプリケーションにおいて、大規模なロボットチームの逐次タスク割り当てと無衝突ルーティングの問
題の最適解を計算するための階層アルゴリズムを提案.
- 提案手法では,4つの階層にアルゴリズムが分かれている.それぞれの階層では,前段階からの出力を用いて,各アルゴリズムを実
行している.
- シミュレーションでは, Webots(http://www.cyberbotics.com/)を使用して,提案手法の出力が非ホロノミック差動駆動ロボットの衝突
のない軌道を生成するために使用可能であることを実証した.
まとめた人:souta hriose
https://arxiv.org/abs/2006.08845
Online Trajectory Generationwith Distributed Model Predictive
Control for Multi-Robot Motion Planning
Carlos E. Luis, Marijan Vukosavljev and Angela P. Schoellig
- 分散モデル予測制御 (DMPC)に基づいたマルチロボットオンライン軌道生成のフレームワークを提案.
- 遷移タスクでの非衝突軌道を効率的に計算するために,オンデマンド衝突回避法を採用している.また,外乱を考慮したイベントトリ
ガー型の再計画法をフレークワークに含めている.
- シミュレーションでは,バッファード・ボロノイ・セル( BVC)法と比較し、マルチエージェントの point-to-point移行に必要な移動時間を
平均で約50%短縮できることが示された . さらに、18m^3のアリーナに30台の手のひらサイズのクアッドローターで 90%以上の成功
率が得られた.
- RA-L Accepted
まとめた人:souta hriose
https://arxiv.org/abs/1909.05150
64.
One-Shot Multi-Path Planningfor Robotic Applications Using Fully
Convolutional Networks
Tomas Kulvicius, Sebastian Herzog, Timo L¨uddecke, Minija Tamosiunaite and Florentin W¨org¨otter
- 完全畳み込みネットワークを用いて one-shot予測で単一パスだけでなく複数パスを生成する手法を提案.
- 提案手法では,ネットワークの入力に 3つの2次元画像(Environment, Start, Goal)を指定している.また,ネットワークの出力には入
力画像と同様のスケール内で予測した経路が表現される.
- 2Dおよび3D環境における単一パス予測の 99%以上のケースにおいて、最適または最適に近いパス( 10%未満)を生成することに成
功したことを実証した.ネットワークは、 2つのパスの場合には 96%、3つのパスを同時に生成した場合には 84%で、最適な(最適に
近い)パスを生成した.
まとめた人:souta hriose
https://arxiv.org/pdf/2004.00568.pdf
65.
DDM: Fast Near-OptimalMulti-Robot Path Planning using Diversified-Path
and Optimal Sub-Problem Solution Database Heuristics
Shuai D. Han Jingjin Yu
- オンデマンドで自動化された倉庫を対象とした、グリッドグラフ上でのマルチロボットの経路計画問題を解く集中化・分離アルゴリズム
の提案.
- グラフ頂点の使用のバランスを考慮した経路多様化と,高速かつ最適な局所衝突回避の為のサブ問題解決データベースの採用に
より,単発的な問題でも動的な問題でも,大幅な高速化と高品質な解の生成が実現することを実証的に示している.
- 検証では,複数のグリッドのパターンにおいて,提案手法と Enhanced Conflict-Based Search,整数線形計画法との比較を行い、有
効性を評価した.
- video : https://www.youtube.com/watch?v=0MUGrg5CphM&feature=youtu.be
- this paper is accepted as RA-L
まとめた人:souta hriose
66.
Efficient Iterative Linear-QuadraticApproximations
for Nonlinear Multi-Player General-Sum Differential Games
David Fridovich-Keil, Ellis Ratner, Lasse Peters, Anca D. Dragan, and Claire J. Tomlin
- multi-player general-sum differential gamesにおける局所解を見つけるためのアルゴリズムの提案.
- 提案手法は最適制御問題で使用される局所的な手法である反復線形二次レギュレータ (ILQR)をベースに構築されている. ILQRは、
線形力学と二次コストを用いて近似を効率的に解くことで、初期制御戦略を繰り返し改良する。この解を利用して連続的な LQ近似を
解くことで、リアルタイムに元のゲームの局所解を見つけている.
- シミュレーションでは, 3人プレイ、14状態の交点問題において初期状態から 0.25秒未満で収束することを実現した.
- Project Code : https://github.com/HJReachability/ilqgames
まとめた人:souta hriose
https://arxiv.org/abs/1909.04694
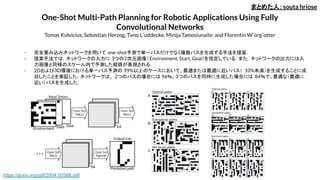
Learning to combineprimitive skills: A step towards versatile robotic manipulation
Robin Strudel, Alexander Pashevich, Igor Kalevatykh, Ivan Laptev, Josef Sivic, Cordelia Schmid
- 強化学習を使ってプリミティブな操作を統合して複雑なタスクを実行する物体操作手法の提案.
- Behavioral Cloning(BC)を使って,シミュレーションで合成されたデモンストレーションの軌道から個々の操
作を学習する.
- 学習された個々の操作を入力の深度画像から使用すべき動作を選択して実行する.
- 100のデモンストレーションで高い成功率を出すことができている.環境の動的な変化や,オクルージョンに
対しても手順を間違えることなく動作を選択することができる.
まとめた人:makihara
https://arxiv.org/abs/1908.00722
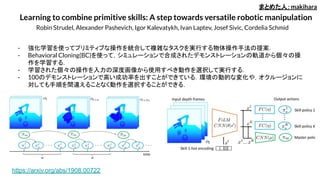
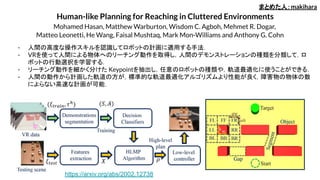
Human-like Planning forReaching in Cluttered Environments
Mohamed Hasan, Matthew Warburton, Wisdom C. Agboh, Mehmet R. Dogar,
Matteo Leonetti, He Wang, Faisal Mushtaq, Mark Mon-Williams and Anthony G. Cohn
- 人間の高度な操作スキルを認識してロボットの計画に適用する手法.
- VRを使って人間による物体へのリーチング動作を取得し,人間のデモンストレーションの種類を分類して,ロ
ボットの行動選択を学習する.
- リーチング動作を細かく分けた Keypointを抽出し,任意のロボットの種類や,軌道最適化に使うことができる.
- 人間の動作から計画した軌道の方が,標準的な軌道最適化アルゴリズムより性能が良く,障害物の物体の数
によらない高速な計画が可能.
まとめた人:makihara
https://arxiv.org/abs/2002.12738
74.
Where to relocate?:Object rearrangement inside cluttered and confined
environments for robotic manipulation
Sang Hun Cheong, Brian Y. Cho, Jinhwi Lee, ChangHwan Kim, and Changjoo Nam
- 作業空間の中で,障害となる物体をどこに移動させるかを計画する手法.
- 物の配置を考えるとき,それぞれの物体が一回のみの移動させる場合と,複数回移動させる場合に対して
,空いた場所を使って配置手順を構築していく.
- 移動の回数とその時間を最小化するように動作手順を設計している.障害物が多くなると既存手法では成
功率が低くなるが,90%以上の成功率を維持している.
まとめた人:makihara
https://arxiv.org/abs/2003.10863
75.
Autonomous Modification ofUnstructured Environments with Found Material
Vivek Thangavelu , Ma´ıra Saboia da Silva , Jiwon Choi and Nils Napp
- 瓦礫がある状況なとに対して踏破を可能するために,未知の物体を積み上げることによって踏破しやすい
構造を作るシステム.
- 取得したポイントクラウド をメッシュ化し,踏破が可能な凹凸が最小限になる構造を表す MInimal
Addaptive Ramp Structure(MARS)を推定する.MARSに基づいて積み上げて埋めていく空間を推定する.
- 様々な形状を持つ石の形状を認識して,不確実性を考慮して3次元形状を復元する.積み上げる場所をロ
ボットがアクセス可能なことを考慮して特定する.
- ロバストに把持が可能なハンドを使って石を把持して,目的の場所に配置する.
まとめた人:makihara
https://www.researchgate.net/publication/339848687_Autonomous_Modification_of_Unst
ructured_Environments_with_Found_Material
76.
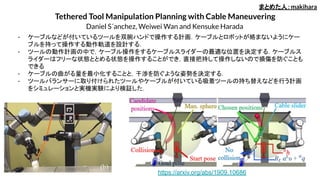
Tethered Tool ManipulationPlanning with Cable Maneuvering
Daniel S´anchez, Weiwei Wan and Kensuke Harada
- ケーブルなどが付いているツールを双腕ハンドで操作する計画.ケーブルとロボットが絡まないようにケー
ブルを持って操作する動作軌道を設計する.
- ツールの動作計画の中で,ケーブル操作をするケーブルスライダーの最適な位置を決定する.ケーブルス
ライダーはフリーな状態ととめる状態を操作することができ,直接把持して操作しないので損傷を防ぐことも
できる
- ケーブルの曲がる量を最小化することと,干渉を防ぐような姿勢を決定する.
- ツールバランサーに取り付けられたツールやケーブルが付いている吸着ツールの持ち替えなどを行う計画
をシミュレーションと実機実験により検証した.
まとめた人:makihara
https://arxiv.org/abs/1909.10686













![From Keywords in Proceedings
・IROS2019, ICRA2019,2020におけるProceedingで使用されているKeywordを集計
・集計した結果より、傾向を考察する
・Top Keywordの表のPercentageには次の式を使用
Percentage =
14
Number of Proceeding including Each Keyword
Number of Total Proceedings
x 100 [%]](https://image.slidesharecdn.com/icra2020v2-200629220736/85/Icra2020-v2-14-320.jpg)































![Towards Plan Transformations for Real-World Mobile Fetch and Place
Gayane Kazhoyan, Arthur Niedzwiecki and Michael Beetz
- 一般的に、ある動作がロボットおよび環境の空きリソースを未使用のままにしてしまう可能性がある理由は、オブジェクトのサイズ、重
量、正確な位置、空間内の他の障害物オブジェクトの位置など、動作の正確なパラメータの多くが、ロボット動作仕様が作成された時
点では未知であるからである . そのため、ロボットは実行中に行動を変更し、現在の状況に合わせて行動を適応させる必要がある.
- そこで,実行時にロボットの行動をコード置換を用いて自律的に変形させることで,実世界のロボットの計画実行を改善し,より良い
性能を実現するためのアプローチを提示する.
- ロボットの動作を解析し、あらゆるシナリオやコンテキストの範囲で変形させるために、前作 [11]で紹介したタスクツリーのデータ構造
を利用している.タスクツリーは実行された計画の実行時表現であり、計画が呼び出されたパラメータを含む計画に関連するすべて
の情報を含む。実行時には、実行されたアクションごとに、タスクツリー内にノードが自動的に作成され、プラン内で実行されたすべて
のサブプランの子ノードへの参照が含まれる.
まとめた人:souta hriose
https://arxiv.org/pdf/1812.08226.pdf](https://image.slidesharecdn.com/icra2020v2-200629220736/85/Icra2020-v2-52-320.jpg)























![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)





![-SSIIの技術マップ- 過去•現在, そして未来 [領域]認識](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2014-os-recognition-140612-140611032253-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















