Download to read offline









![Inductive types
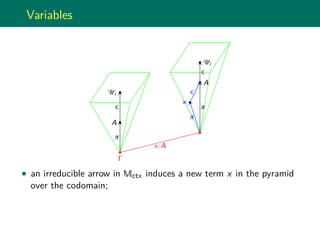
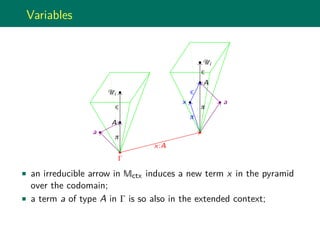
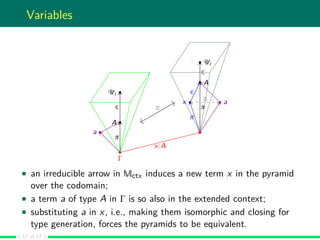
An inductive type is the minimal collection of terms closed under the
interpretation of its introduction rules.
Semantically, this means an inductive type is the colimit of the
diagram composed by the terms-in-context which are the result of the
closure of the transformation associated to the introduction rules.
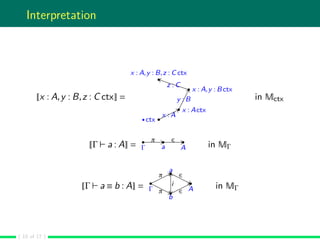
For example, the dependent sum has the following introduction rule:
Γ b : B[a/x] Γ a : A Γ,x : A B : Ui Γ A : Ui
Σ−I
Γ (a,b) : Σx : A.B
The associated semantic transformation θ maps each pair of objects
α and β in MΓ such that there are ∈: α → A Γ and ∈: β → B[a/x] Γ
in an object θ(α,β) of MΓ.
( 13 of 17 )](https://image.slidesharecdn.com/main-171206055421/85/Point-free-semantics-of-dependent-type-theories-16-320.jpg)





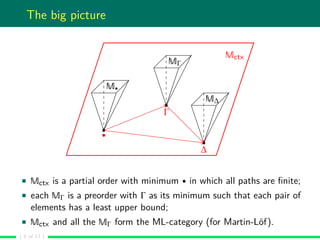
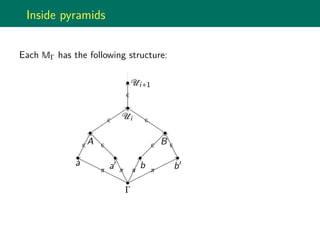
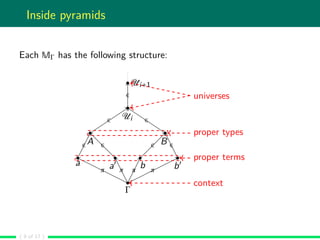
The document discusses the point-free semantics of dependent type theories, particularly highlighting issues with existing complex models and proposing that simpler categorical models can adequately explain these theories. It outlines the need for a clear definition of inductive theory and its extension to higher-inductive types, along with the challenges of polishing soundness and completeness proofs. The authors are in the process of formalizing their findings and refining the semantics of inductive types within the framework they are developing.










![[Slfm 118] theory of relations roland fraisse (nh 1986)(t)](https://cdn.slidesharecdn.com/ss_thumbnails/slfm118theoryofrelations-rolandfraissenh1986t-140808170208-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Emnlp] what is glo ve part i - towards data science](https://cdn.slidesharecdn.com/ss_thumbnails/emnlpwhatisgloveparti-towardsdatascience-200228052054-thumbnail.jpg?width=640&height=640&fit=bounds)











































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)


















