Downloaded 35 times













![EXAMPLE:-
"Recharge your mobile by visiting this link"
After tokenization:-
['Recharge', 'your', 'mobile', 'by', 'visiting', 'this', 'link']](https://image.slidesharecdn.com/onedriveonedriveautomatedhd1-161214093224/85/Deep-Learning-Automated-Helpdesk-17-320.jpg)


![EXAMPLE :-
FromTokenization
['Recharge', 'your', 'mobile', 'by', 'visiting', 'this', 'link']
After Stop Words removal
['Recharge', 'mobile', 'visiting', 'link']](https://image.slidesharecdn.com/onedriveonedriveautomatedhd1-161214093224/85/Deep-Learning-Automated-Helpdesk-20-320.jpg)

![EXAMPLE :-
From Stop words removal :-
['Recharge', 'mobile', 'visiting', 'link']
After Stemming :-
['Recharge', 'mobile', 'visit', 'link'] // input for clustering is
generated](https://image.slidesharecdn.com/onedriveonedriveautomatedhd1-161214093224/85/Deep-Learning-Automated-Helpdesk-22-320.jpg)

![EXAMPLE :-
From Stemming:-
['Recharge', 'mobile', 'visit', 'link']
After POS Tagging:-
[('Recharge', 'NN')]
[('mobile', 'NN')]
[('visit', 'VBG')]
[('link', 'NN')]](https://image.slidesharecdn.com/onedriveonedriveautomatedhd1-161214093224/85/Deep-Learning-Automated-Helpdesk-24-320.jpg)
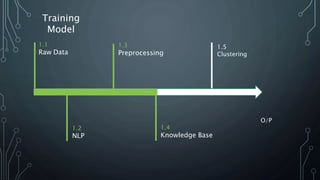


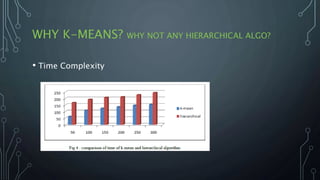




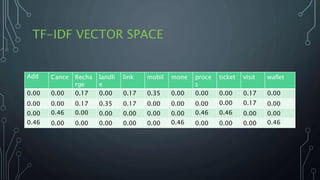
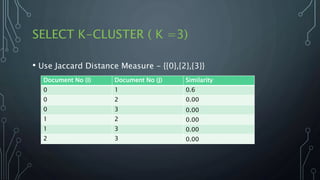


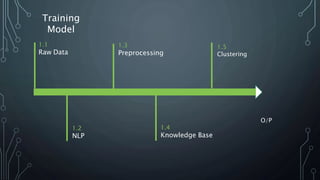


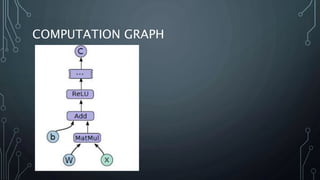

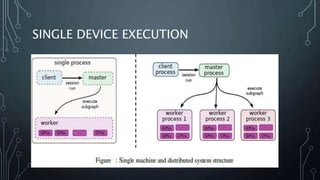


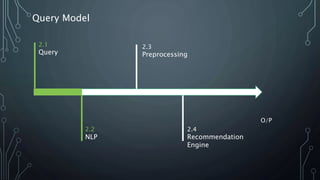
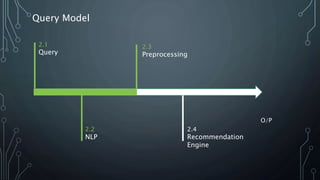
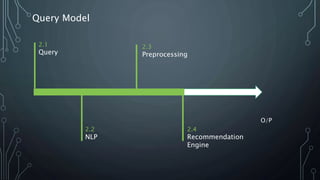







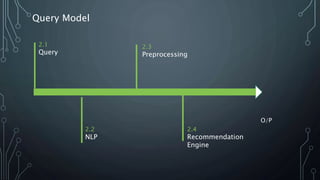


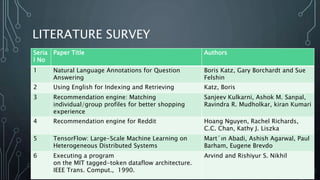




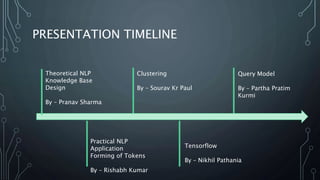
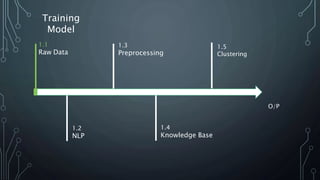
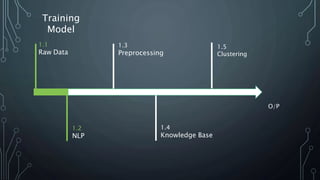
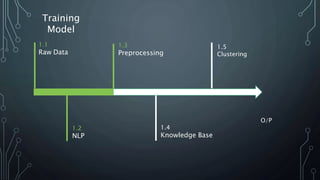
The document outlines a final year project on an automated helpdesk system designed to assist customers with common queries using Natural Language Processing (NLP). It includes details on project components such as data preprocessing, clustering, and the use of TensorFlow for model execution, aiming to create an efficient question-answering platform. The project timeline, methodologies, and literature survey are also highlighted, emphasizing the goal of developing a user-friendly system to reduce manpower in customer service.















































