Downloaded 176 times


















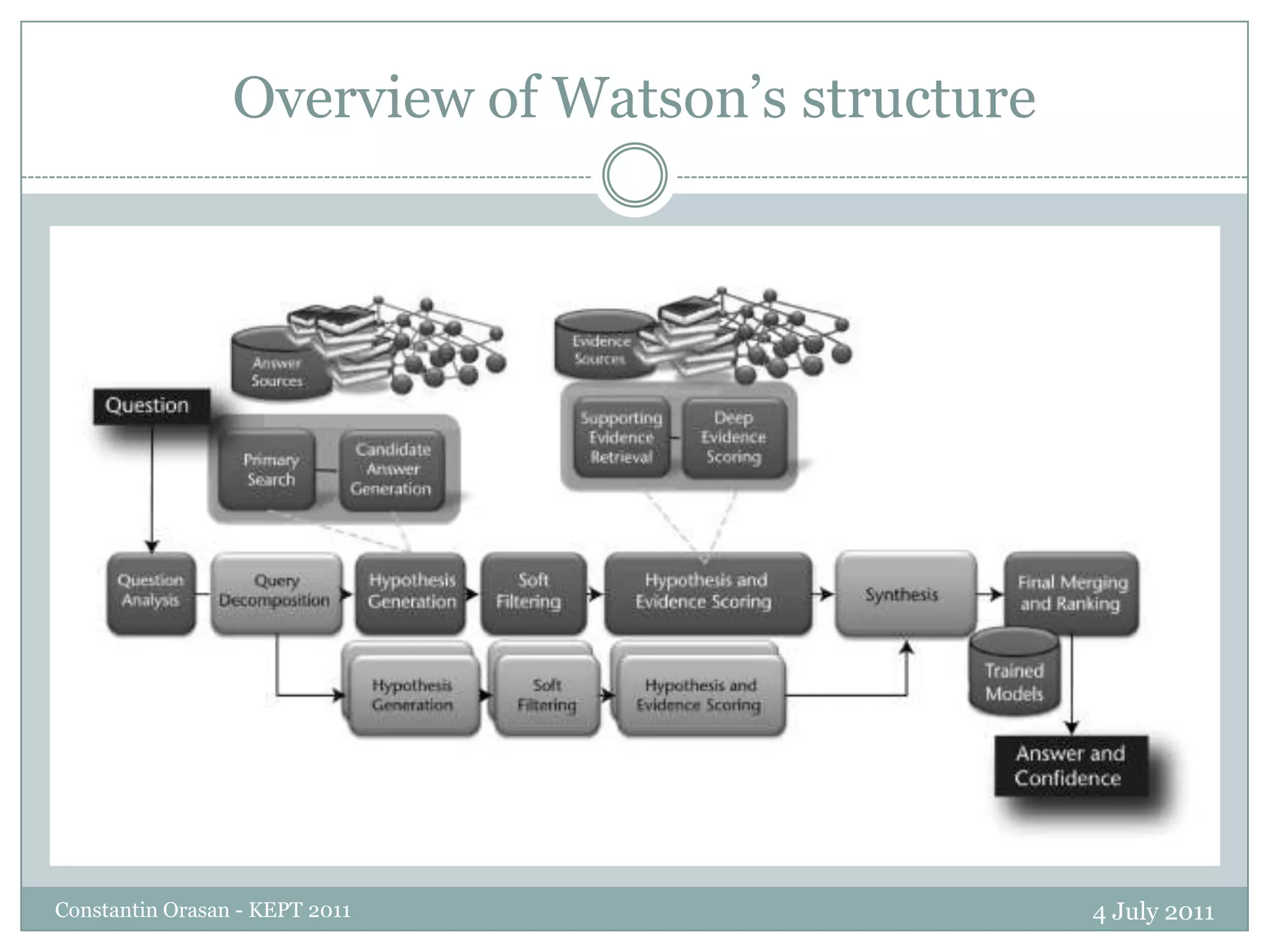








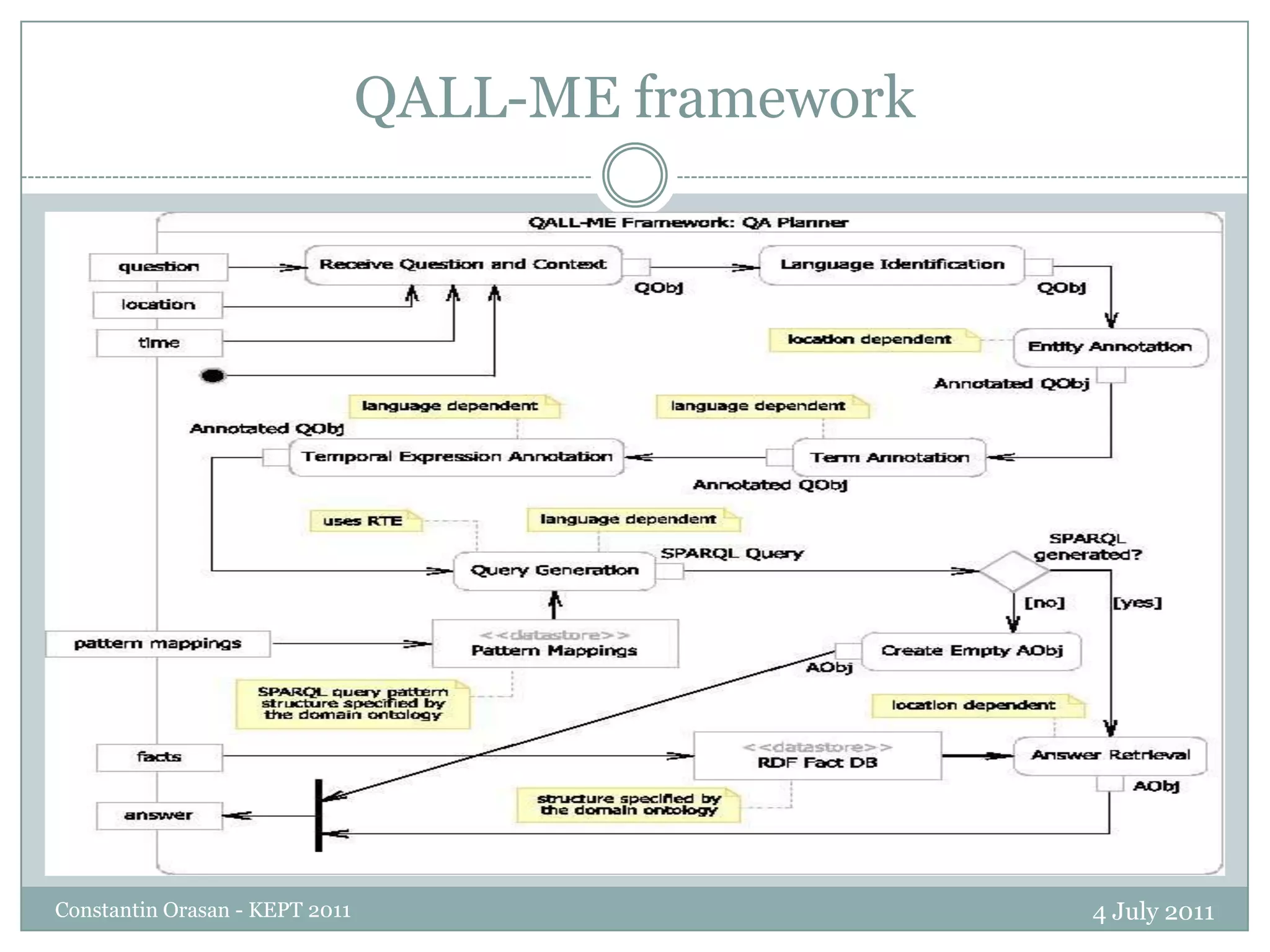

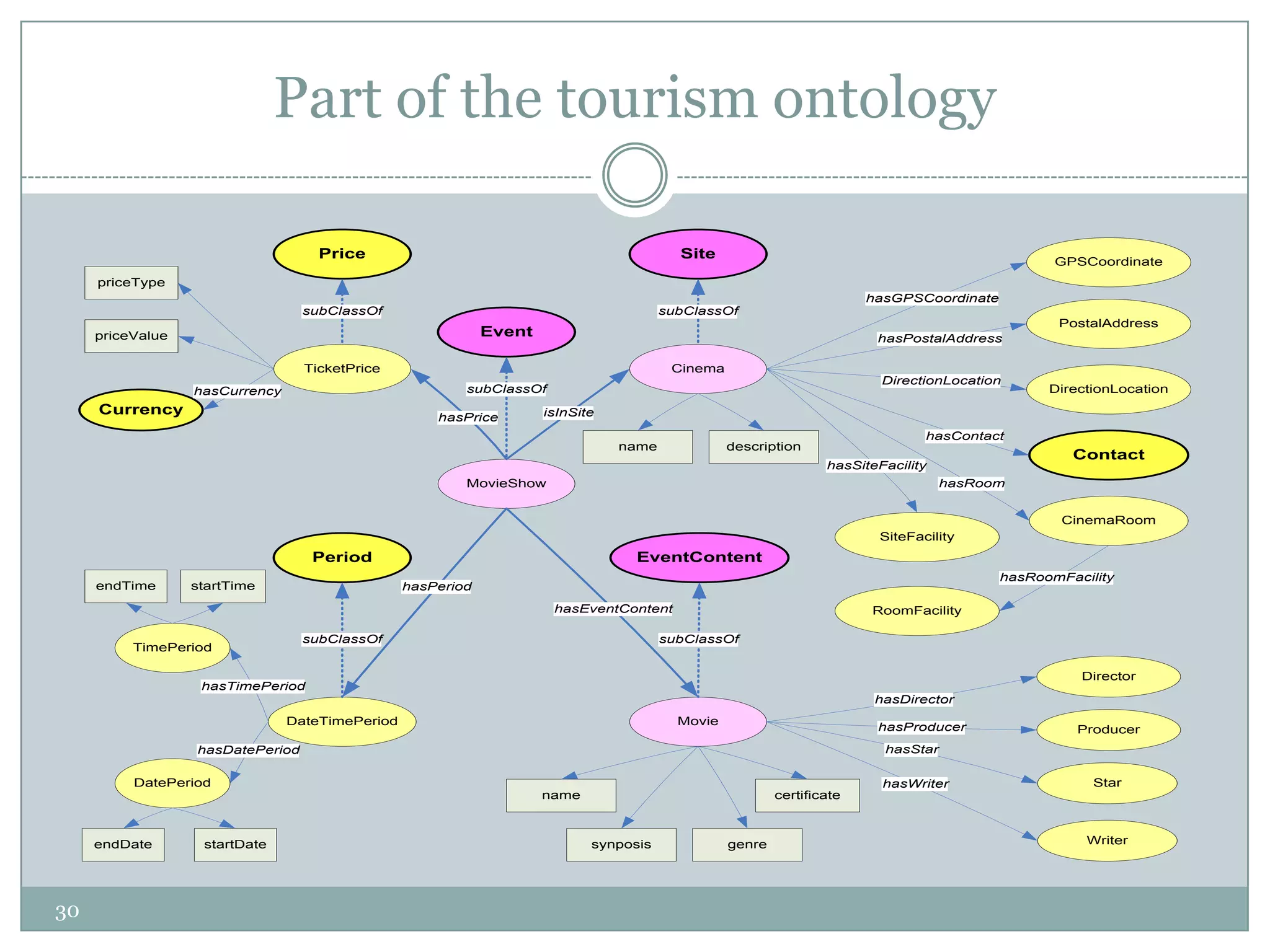








The document summarizes a presentation on question answering systems. It begins by providing context on information overload and defining question answering. It then discusses the evolution of QA systems from early databases to today's open-domain systems. The presentation focuses on IBM's Watson system, providing an overview of its unprecedented ability to answer open-domain questions as well as the massive resources required for its development. It concludes by arguing that open-domain QA remains unsolved and that closed-domain, interactive QA may be more practical for real-world applications.































































































