Downloaded 43 times




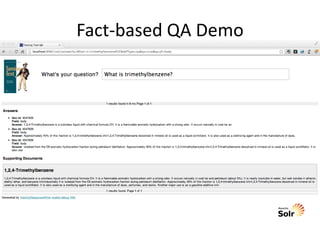







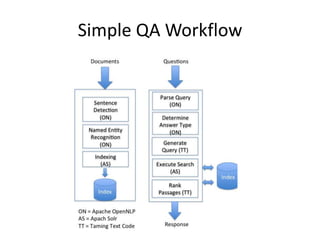
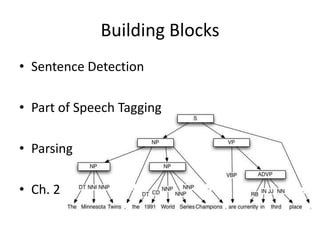









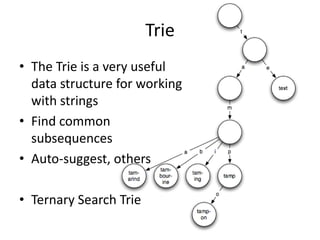





The document outlines the book 'Taming Text,' which serves as an engineering guide to search, natural language processing (NLP), and machine learning primarily using Java examples. It covers topics such as question answering, text indexing, and various NLP techniques, emphasizing the importance of preprocessing and feature selection. It also highlights resources for building question-answering systems and discusses advanced topics like clustering and fuzzy string matching.