More Related Content

PDF

PPTX
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~ 
PDF
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料) 
PDF

PDF

PDF
PostgreSQL: XID周回問題に潜む別の問題 What's hot

PPTX
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料) 
PDF

PPTX
押さえておきたい、PostgreSQL 13 の新機能!!(Open Source Conference 2021 Online/Hokkaido 発表資料) 
PPTX

PDF
統計情報のリセットによるautovacuumへの影響について(第39回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PPTX
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス... 
PPTX
祝!PostgreSQLレプリケーション10周年!徹底紹介!! 
PPTX
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F... ![[B23] PostgreSQLのインデックス・チューニング by Tomonari Katsumata](https://cdn.slidesharecdn.com/ss_thumbnails/b23ntt-140624233630-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[B23] PostgreSQLのインデックス・チューニング by Tomonari Katsumata 
PDF

PPTX
VSCodeで作るPostgreSQL開発環境(第25回 PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF

PDF
Memoizeの仕組み(第41回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF
PostgreSQLの運用・監視にまつわるエトセトラ 
PDF
Inside vacuum - 第一回PostgreSQLプレ勉強会 
PDF
PostgreSQL SQLチューニング入門 実践編(pgcon14j) 
PDF
YugabyteDBを使ってみよう - part2 -(NewSQL/分散SQLデータベースよろず勉強会 #2 発表資料) 
PPTX

PDF
PostgreSQLのリカバリ超入門(もしくはWAL、CHECKPOINT、オンラインバックアップの仕組み) 
PDF
Viewers also liked

PDF
NTT DATA と PostgreSQL が挑んだ総力戦 
PDF

PDF
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012) 
PDF
JSONBはPostgreSQL9.5でいかに改善されたのか 
PDF
perfを使ったPostgreSQLの解析(後編) 
PDF

PDF

PDF

PDF
perfを使ったPostgreSQLの解析(前編) 
PDF

PDF

PDF

PDF
PGCon.jp 2014 jsonb-datatype-20141205 
PDF

PDF

PDF

PDF

PDF
データサイエンティスト協会 木曜勉強会 #09 『意志の力が拓くシステム~最適化の適用事例から見たデータ活用システムの現在と未来~』 
PDF

PDF
Similar to pg_bigmを用いた全文検索のしくみ(前編)

PDF
pg_bigm(ピージーバイグラム)を用いた全文検索のしくみ 
PDF

PDF
pg_bigm(ピージー・バイグラム)を用いた全文検索のしくみ(後編) 
PDF
PostgreSQL 13でのpg_stat_statementsの改善について(第12回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF

PDF

PDF
JPUGしくみ+アプリケーション勉強会(第20回) 
PDF
PostgreSQL18新機能紹介(db tech showcase 2025 発表資料) 
PDF
YugabyteDBの実行計画を眺める(NewSQL/分散SQLデータベースよろず勉強会 #3 発表資料) 
PDF

PDF

PDF
20140531 JPUGしくみ+アプリケーション分科会 勉強会資料 
PDF
Pgunconf 20121212-postgeres fdw 
PDF

PDF
アナリティクスをPostgreSQLで始めるべき10の理由@第6回 関西DB勉強会 
PDF

PPT
20090107 Postgre Sqlチューニング(Sql編) 
PDF

PDF
PostgreSQL 9.2 新機能 - 新潟オープンソースセミナー2012 
PDF
More from NTT DATA OSS Professional Services

PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント 
PDF
Apache Hadoopの未来 3系になって何が変わるのか? 
PDF
Spark SQL - The internal - 
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~ 
PDF
Apache Hadoopの新機能Ozoneの現状 
PDF
Structured Streaming - The Internal - 
PDF
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~ 
PDF
Global Top 5 を目指す NTT DATA の確かで意外な技術力 
PPTX

PDF
Application of postgre sql to large social infrastructure 
PDF
商用ミドルウェアのPuppet化で気を付けたい5つのこと 
PDF
データ活用をもっともっと円滑に!�~データ処理・分析基盤編を少しだけ~ 
PDF
HDFS Router-based federation 
PDF
HDFS basics from API perspective 
PDF
Application of postgre sql to large social infrastructure jp 
PDF

PDF
Apache Hadoop 2.8.0 の新機能 (抜粋) 
PDF

PDF
Apache Hadoop and YARN, current development status 
PDF
Distributed data stores in Hadoop ecosystem pg_bigmを用いた全文検索のしくみ(前編)
- 1.
Copyright © 2013NTT DATA Corporation
2013年6月8日
株式会社NTTデータ 基盤システム事業本部
澤田 雅彦
pg_bigm(ピージーバイグラム)を用いた全文検索のしくみ(前編)
第26回しくみ勉強会 - 2.
2
Copyright ©2013NTT DATA Corporation
INDEX
1.全文検索とは?
2.pg_bigmとは?
3.pg_bigmの全文検索のしくみ
4.pg_bigmの性能測定(前編)
5.まとめ - 3.
- 4.
4
Copyright ©2013 NTT DATA Corporation
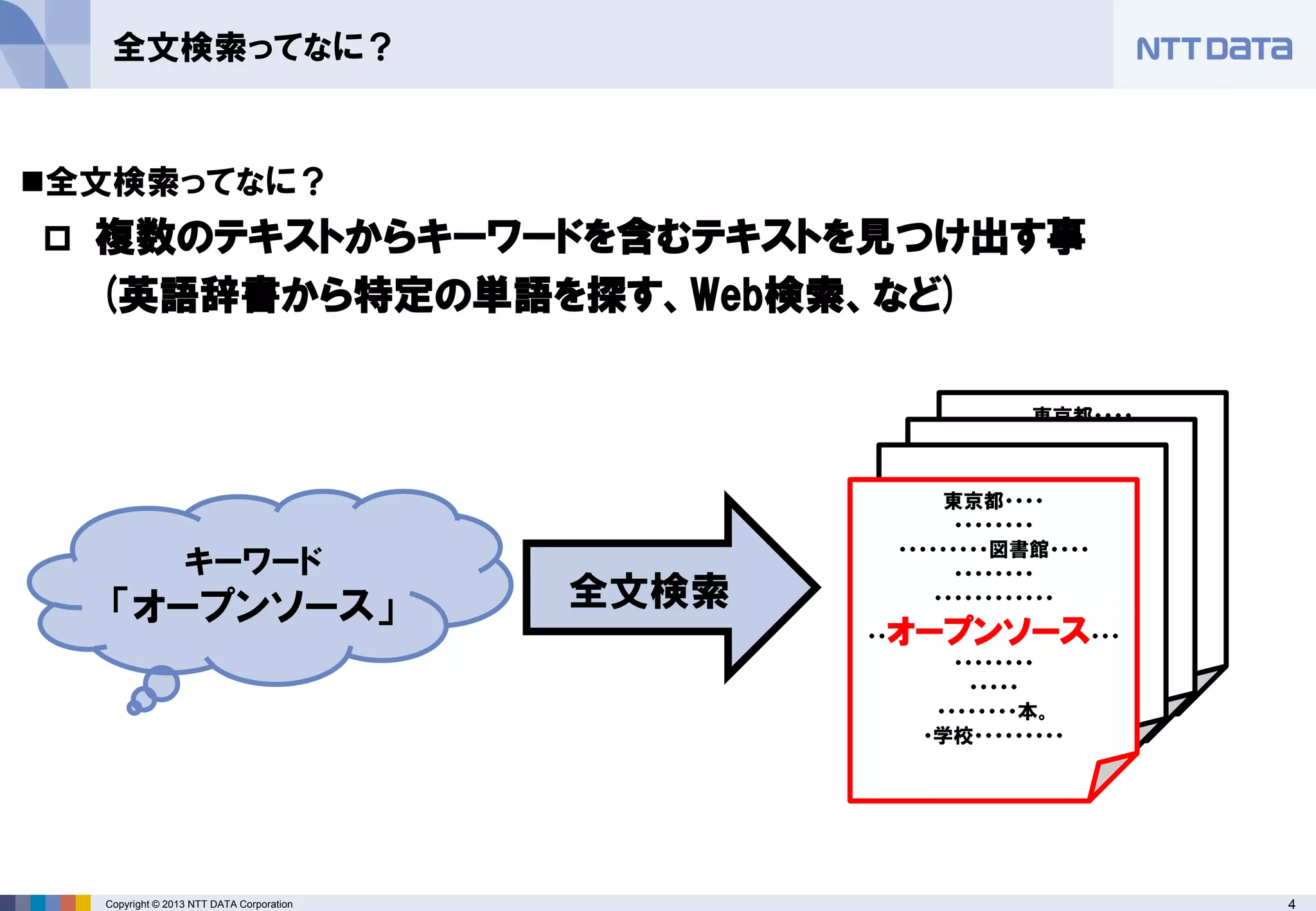
全文検索ってなに?
全文検索ってなに?
複数のテキストからキーワードを含むテキストを見つけ出す事
(英語辞書から特定の単語を探す、Web検索、など)
東京都・・・・
・・・・・・・・
・・・・・・・・・図書館・・・・
・・・・・・・・
・・・・・・
・・・・・・
・・オープンソース・・・
・・・・・・・・
・・・・・
・・・・・・・・本。
・学校・・・・・・・・・
東京都で・・・・
・・・・・・・・
・・・データベース・・・
・・・・・・・・
・・・・・・・・・・・・
・・・・・
・・・・・・・・
東京都・・・・
・・・・・・・・
・・・・・・・図書館・・・・
・・・・・・・・
・・・・・・・・・・・・
・・オープンソース・・・
・・・・・・・・
・・・・・
・・・・・・・・本。
・学校・・・・・・・・・
全文検索
キーワード
「オープンソース」 - 5.
5
Copyright ©2013 NTT DATA Corporation
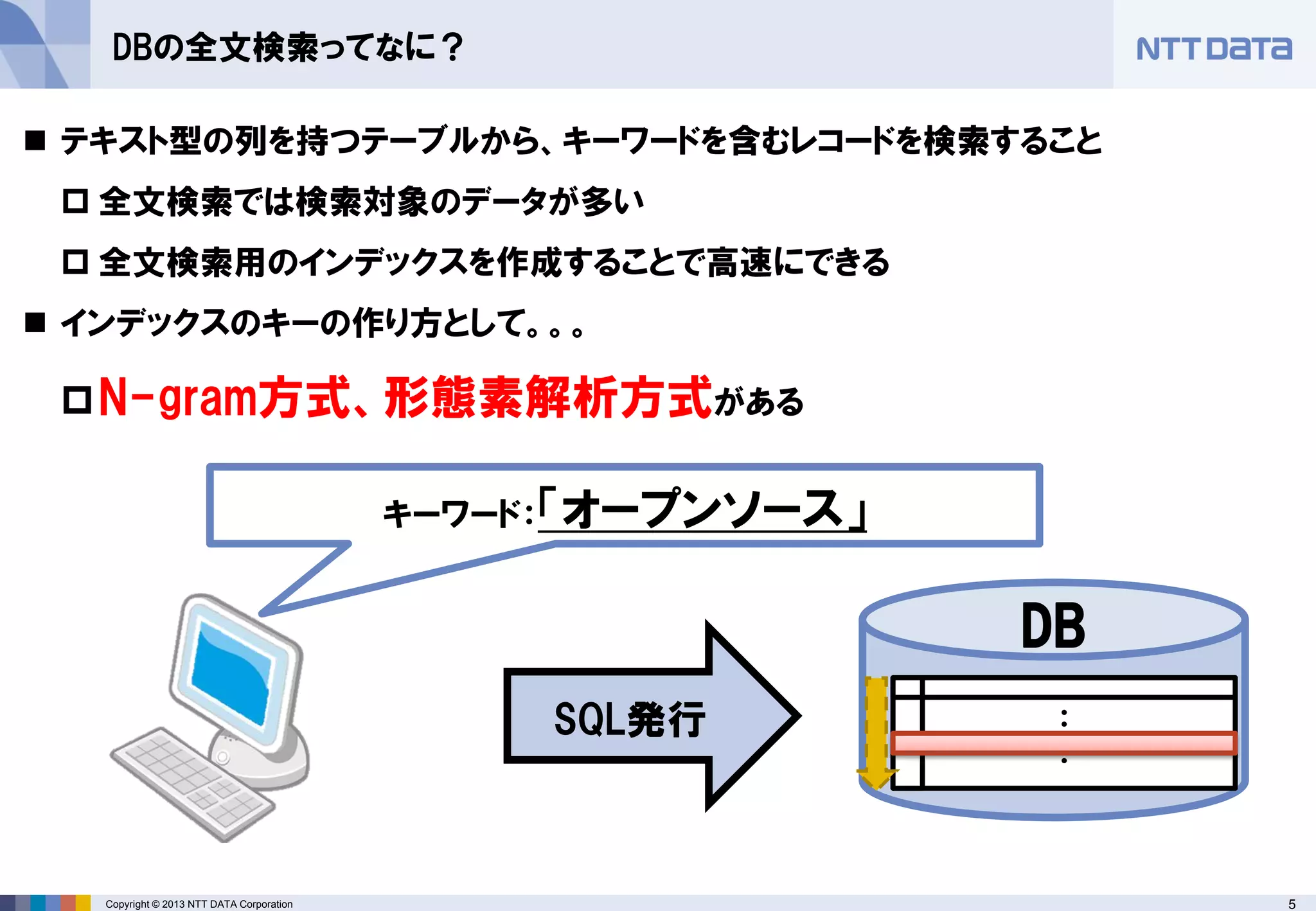
DBの全文検索ってなに?
SQL発行
DB
:
:
テキスト型の列を持つテーブルから、キーワードを含むレコードを検索すること
全文検索では検索対象のデータが多い
全文検索用のインデックスを作成することで高速にできる
インデックスのキーの作り方として。。。
N-gram方式、形態素解析方式がある
キーワード:「オープンソース」 - 6.
6
Copyright ©2013 NTT DATA Corporation
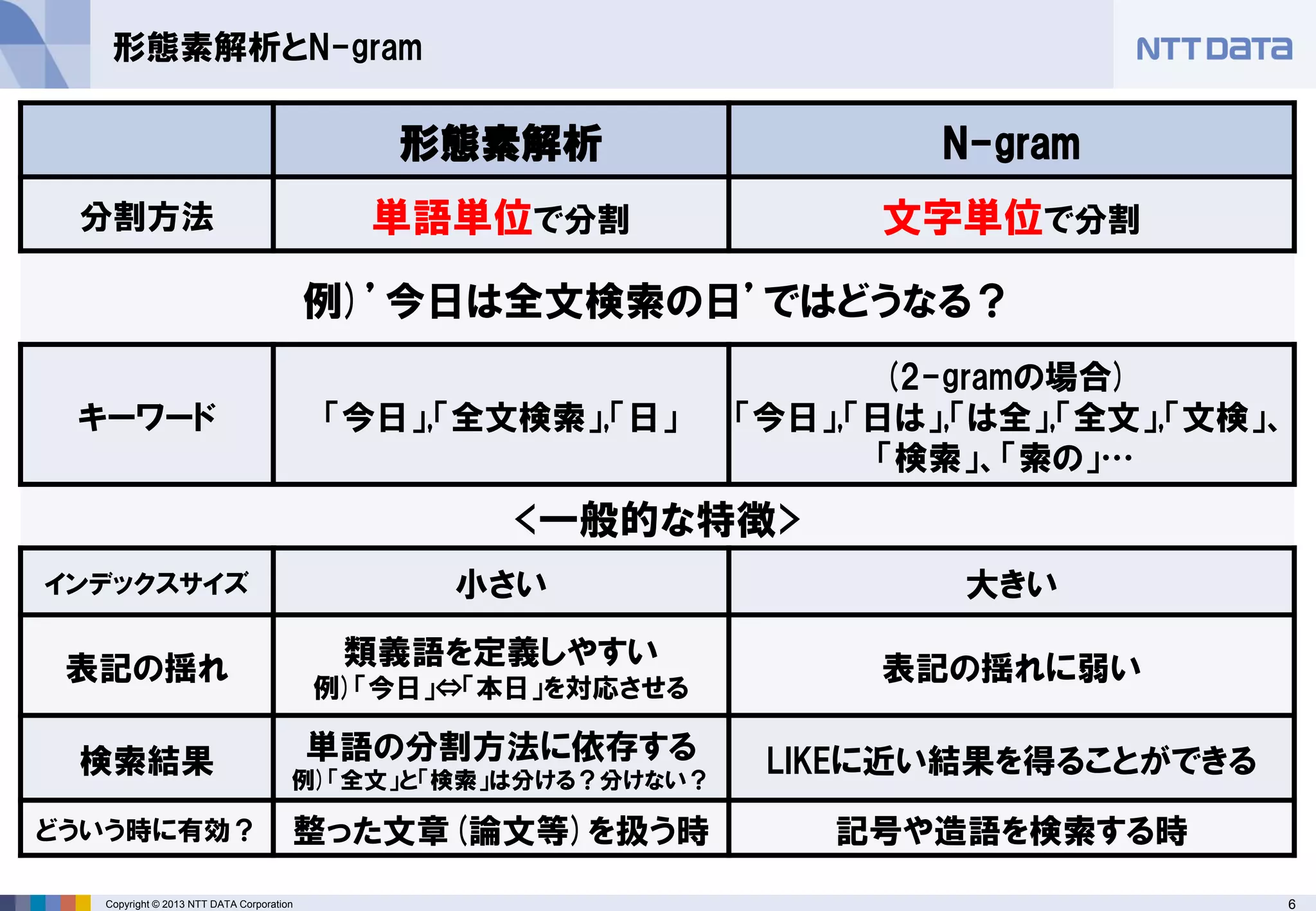
形態素解析とN-gram
形態素解析
N-gram
分割方法
単語単位で分割
文字単位で分割
例)’今日は全文検索の日’ではどうなる?
キーワード
「今日」,「全文検索」,「日」
(2-gramの場合)
「今日」,「日は」,「は全」,「全文」,「文検」、 「検索」、「索の」…
<一般的な特徴>
インデックスサイズ
小さい
大きい
表記の揺れ
類義語を定義しやすい
例)「今日」⇔「本日」を対応させる
表記の揺れに弱い
検索結果
単語の分割方法に依存する
例)「全文」と「検索」は分ける?分けない?
LIKEに近い結果を得ることができる
どういう時に有効?
整った文章(論文等)を扱う時
記号や造語を検索する時 - 7.
7
Copyright ©2013 NTT DATA Corporation
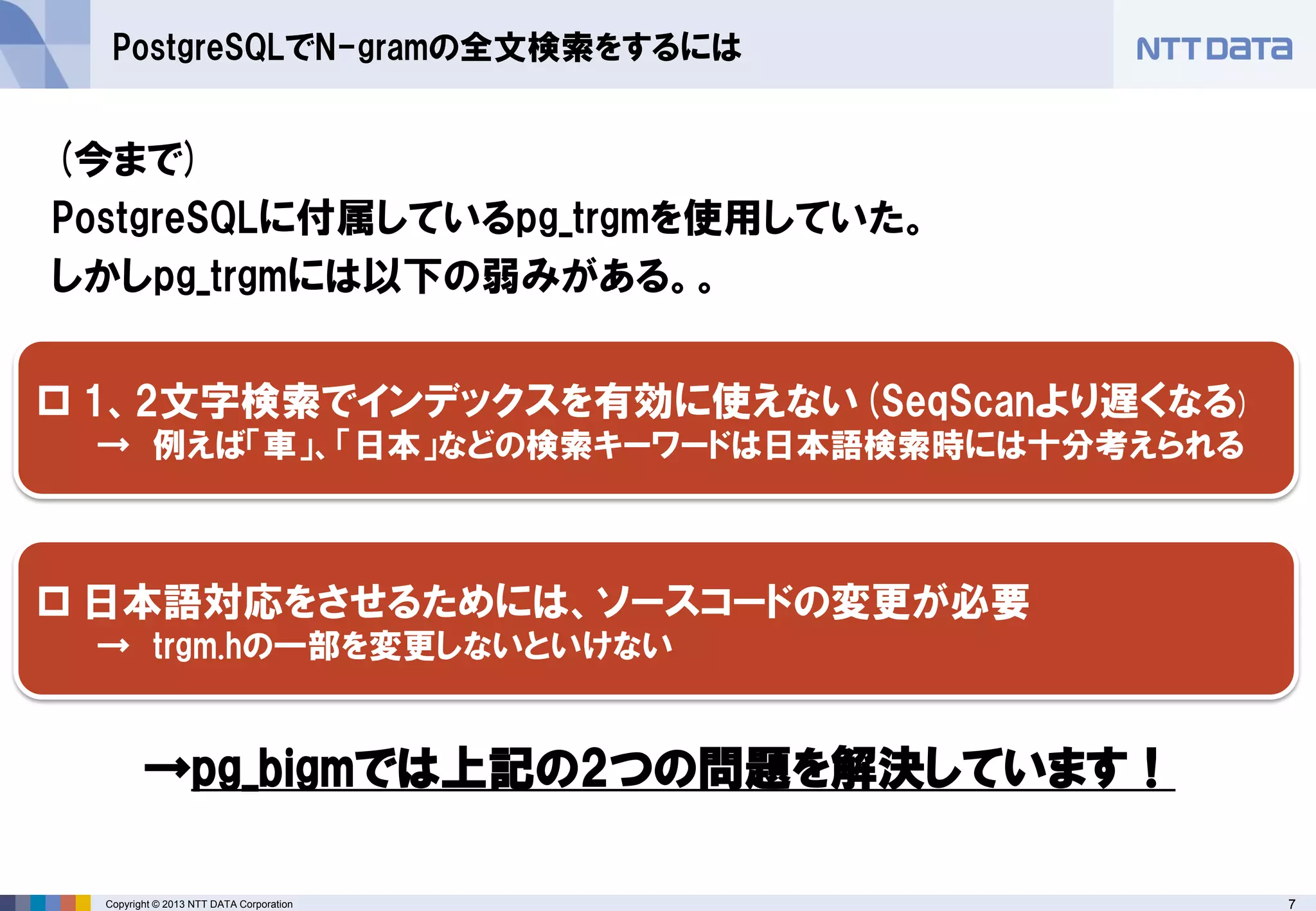
PostgreSQLでN-gramの全文検索をするには
(今まで)
PostgreSQLに付属しているpg_trgmを使用していた。
しかしpg_trgmには以下の弱みがある。。
→pg_bigmでは上記の2つの問題を解決しています!
1、2文字検索でインデックスを有効に使えない(SeqScanより遅くなる)
→ 例えば「車」、「日本」などの検索キーワードは日本語検索時には十分考えられる
日本語対応をさせるためには、ソースコードの変更が必要
→ trgm.hの一部を変更しないといけない - 8.
- 9.
9
Copyright ©2013 NTT DATA Corporation
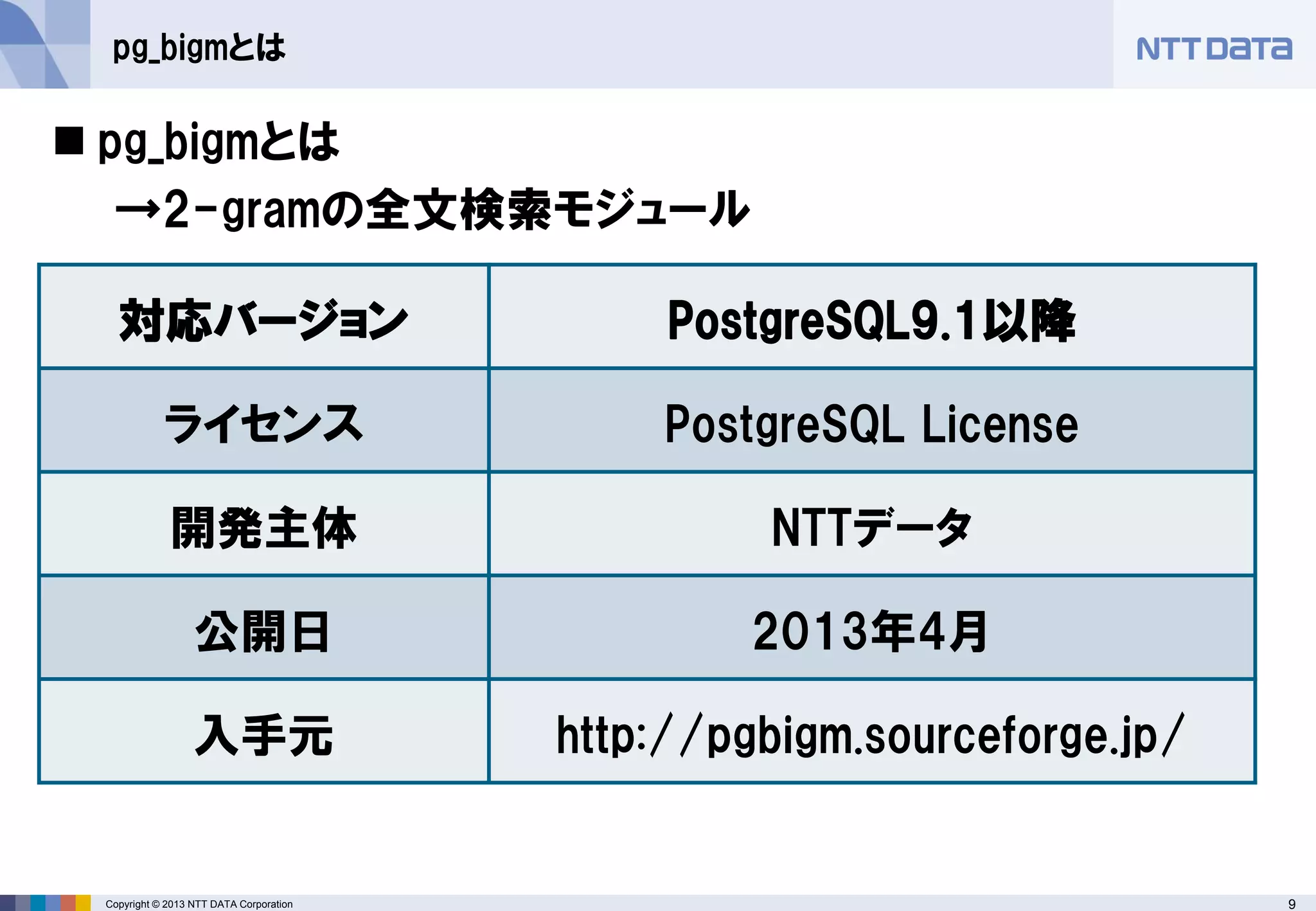
pg_bigmとは
pg_bigmとは
→2-gramの全文検索モジュール
対応バージョン
PostgreSQL9.1以降
ライセンス
PostgreSQL License
開発主体
NTTデータ
公開日
2013年4月
入手元
http://pgbigm.sourceforge.jp/ - 10.
10
Copyright ©2013 NTT DATA Corporation
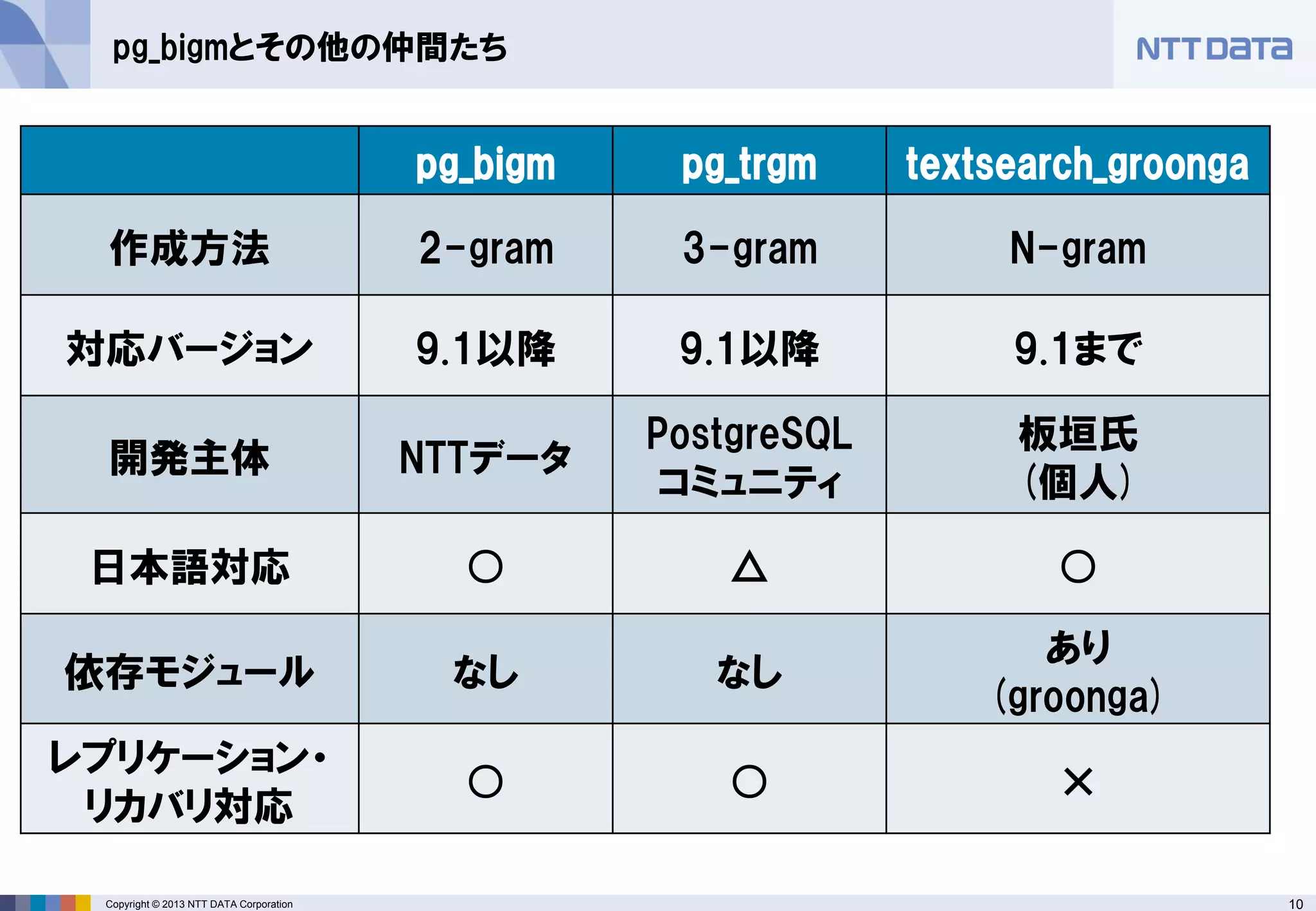
pg_bigmとその他の仲間たち
pg_bigm
pg_trgm
textsearch_groonga
作成方法
2-gram
3-gram
N-gram
対応バージョン
9.1以降
9.1以降
9.1まで
開発主体
NTTデータ
PostgreSQL
コミュニティ
板垣氏
(個人)
日本語対応
○
△
○
依存モジュール
なし
なし
あり
(groonga)
レプリケーション・
リカバリ対応
○
○
× - 11.
11
Copyright ©2013 NTT DATA Corporation
pg_bigmの特徴
2-gramの全文検索モジュール
PostgreSQL内部にインデックスを持つ(GINインデックス)
PostgreSQLのレプリケーション、リカバリ対応
1,2文字検索対応
日本語検索対応
データベースエンコーディングはUTF8、ロケールはCにのみ対応 - 12.
- 13.
13
Copyright ©2013 NTT DATA Corporation
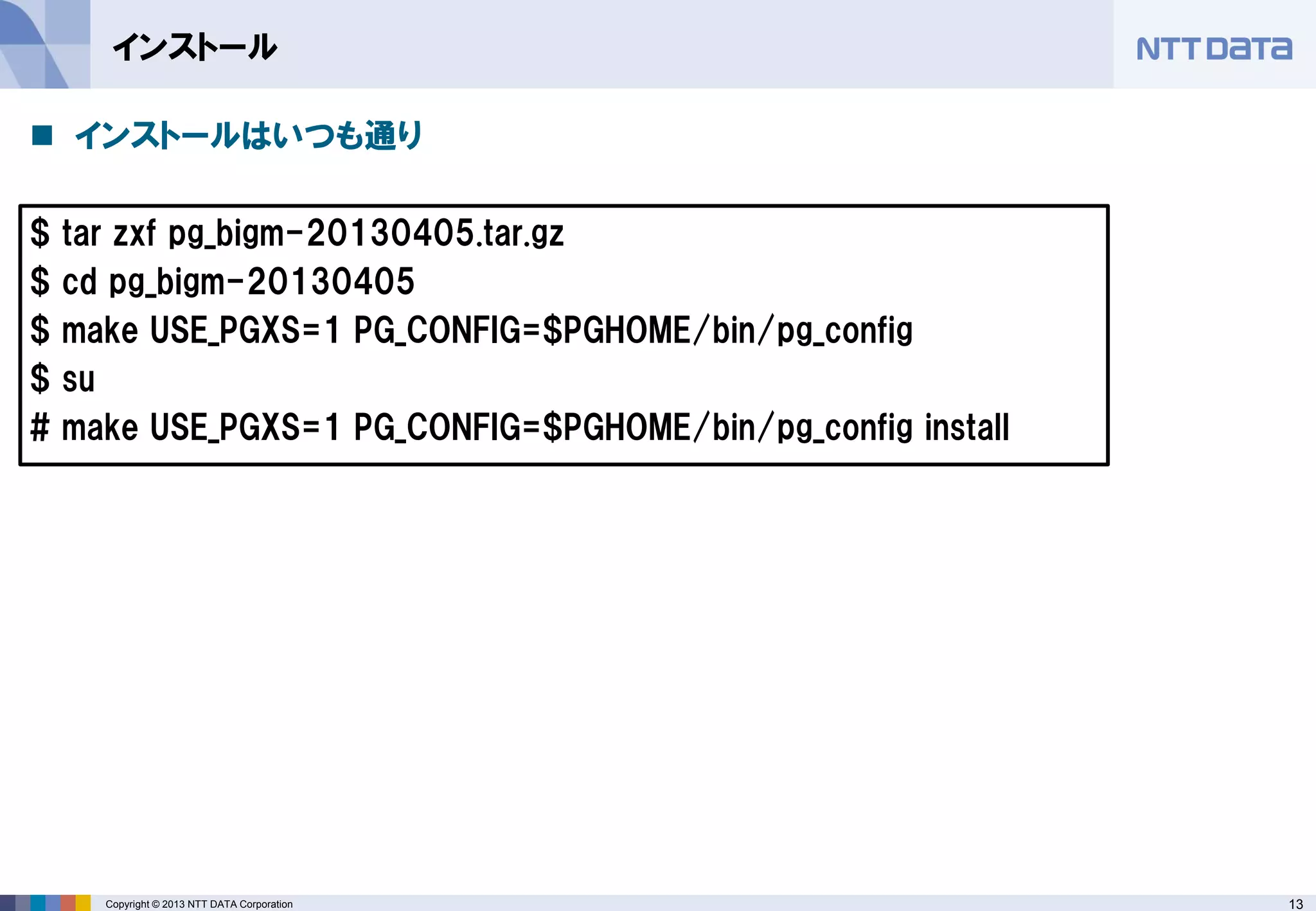
インストール
インストールはいつも通り
$ tar zxf pg_bigm-20130405.tar.gz
$ cd pg_bigm-20130405
$ make USE_PGXS=1 PG_CONFIG=$PGHOME/bin/pg_config
$ su
# make USE_PGXS=1 PG_CONFIG=$PGHOME/bin/pg_config install
- 14.
14
Copyright ©2013 NTT DATA Corporation
pg_bigmの登録
pg_bigmの登録
$ initdb –D $PGDATA --locale=C --encoding=UTF8
$ vi $PGDATA/postgresql.conf
shared_preload_libraries = 'pg_bigm'
custom_variable_classes = ‘pg_bigm‘ (custom_variable_classesは9.2以降では 廃止)
$ pg_ctl start -D PGDATA
$ psql -d <データベース名>
=# CREATE EXTENSION pg_bigm;
=# ¥dx
List of installed extensions
Name | Version | Schema | Description
--------+------+------+--------------------------------
pg_bigm | 1.0 | public | text index searching based on bigrams
- 15.
15
Copyright ©2013 NTT DATA Corporation
インデックス作成まで
テーブル定義作成
=# CREATE TABLE pg_tools (tool text, description text);
データ投入
=# INSERT INTO pg_tools VALUES ('pg_hint_plan', 'HINT句を使えるようにするツール');
=# INSERT INTO pg_tools VALUES ('pg_dbms_stats', '統計情報を固定化するツール');
=# INSERT INTO pg_tools VALUES ('pg_bigm', '2-gramの全文検索を使えるようにするツール');
=# INSERT INTO pg_tools VALUES ('pg_trgm', '3-gramの全文検索を使えるようにするツール');
インデックス作成
=# CREATE INDEX pg_tools_idx ON hoge USING gin (description gin_bigm_ops);
マルチカラムインデックス作成
=# CREATE INDEX pg_tools_multi_idx ON pg_tools USING gin( tool gin_bigm_ops, description gin_bigm_ops);
GINインデックス(転置インデックス)の詳細は
後程説明します - 16.
16
Copyright ©2013 NTT DATA Corporation
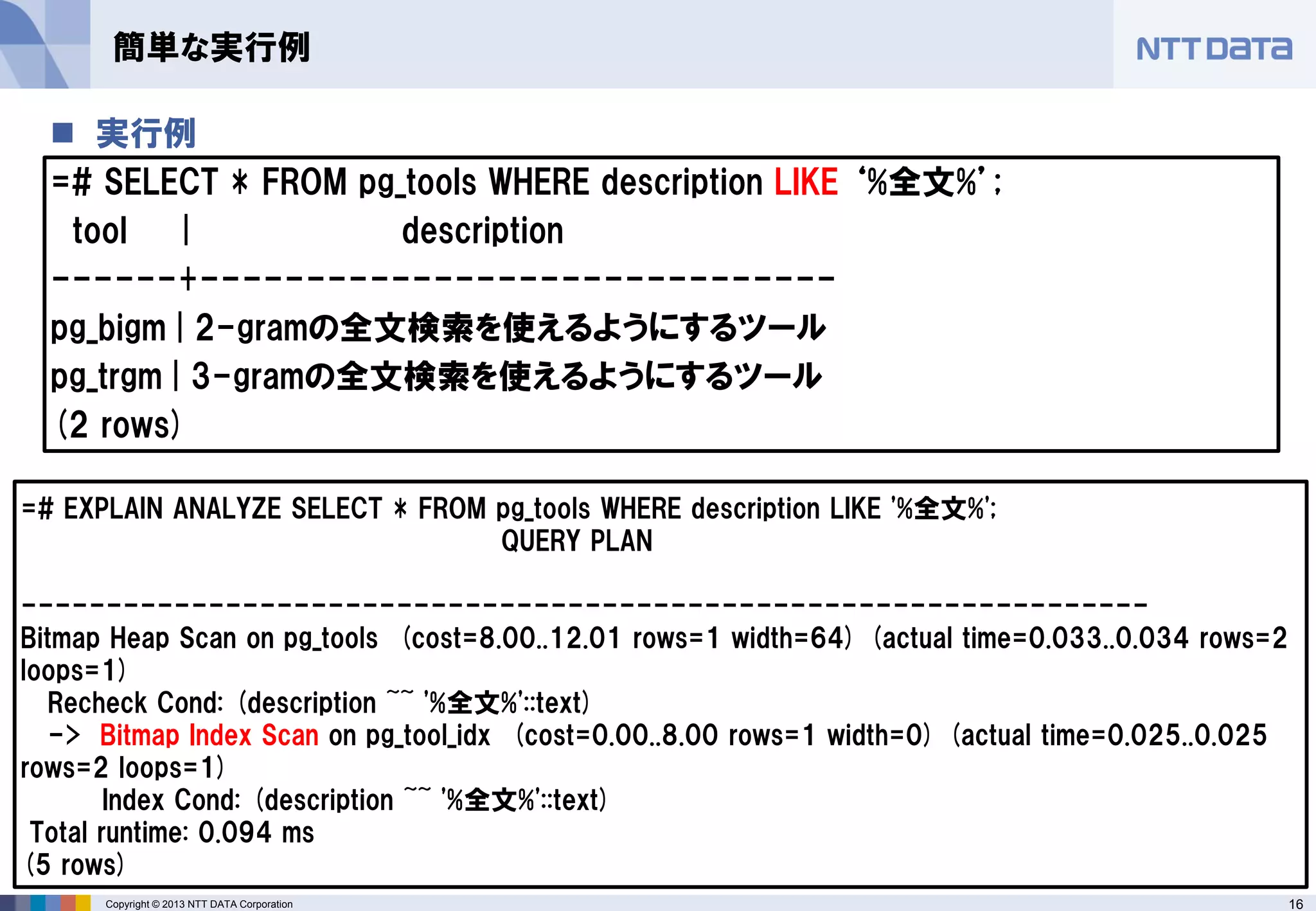
実行例
=# SELECT * FROM pg_tools WHERE description LIKE ‘%全文%’;
tool | description
------+------------------------------
pg_bigm | 2-gramの全文検索を使えるようにするツール
pg_trgm | 3-gramの全文検索を使えるようにするツール
(2 rows)
簡単な実行例
=# EXPLAIN ANALYZE SELECT * FROM pg_tools WHERE description LIKE '%全文%';
QUERY PLAN
------------------------------------------------------------------
Bitmap Heap Scan on pg_tools (cost=8.00..12.01 rows=1 width=64) (actual time=0.033..0.034 rows=2 loops=1)
Recheck Cond: (description ~~ '%全文%'::text)
-> Bitmap Index Scan on pg_tool_idx (cost=0.00..8.00 rows=1 width=0) (actual time=0.025..0.025 rows=2 loops=1)
Index Cond: (description ~~ '%全文%'::text)
Total runtime: 0.094 ms
(5 rows) - 17.
- 18.
18
Copyright ©2013 NTT DATA Corporation
GINインデックスとは
GINインデックス(Generalized Inverted Index)とは?
(Wikipediaより)
全文検索を行う対象からなる文章分から位置情報を格納するための索引構造。
転置索引、逆引き索引などとも呼ばれる
(PostgreSQLマニュアルより)
GINインデックスは(キー、投稿されたリスト)の組み合わせの集合を格納します。
ここで"投稿されたリスト"はキーに合う行IDの集合です。
→「キー」と、「そのキーが出現するTID」の組み合わせを格納するインデックス - 19.
19
Copyright ©2013 NTT DATA Corporation
GINインデックスとは
検索キーワード:「accelerometers compensation」
「accelerometers」
5, 10, 25 ,28, 30, 36, 58, 59, 61, 73, 74
「compensation」
30, 68
「accelerometers compensation 」
→30ページにある - 20.
20
Copyright ©2013 NTT DATA Corporation
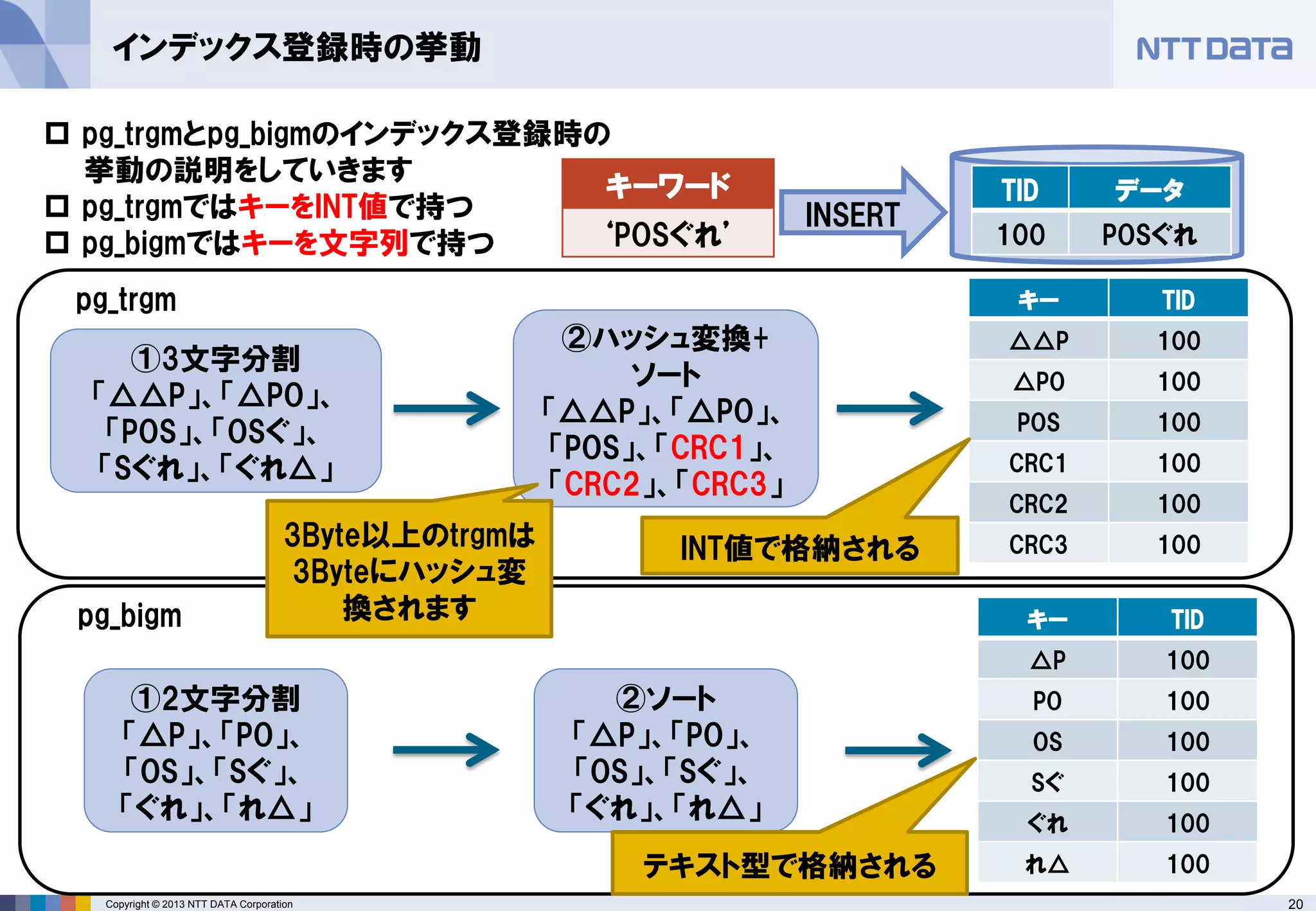
pg_trgmとpg_bigmのインデックス登録時の 挙動の説明をしていきます
pg_trgmではキーをINT値で持つ
pg_bigmではキーを文字列で持つ
インデックス登録時の挙動
キー
TID
△△P
100
△PO
100
POS
100
CRC1
100
CRC2
100
CRC3
100
①3文字分割
「△△P」、「△PO」、
「POS」、「OSぐ」、
「Sぐれ」、「ぐれ△」
②ハッシュ変換+
ソート
「△△P」、「△PO」、 「POS」、「CRC1」、 「CRC2」、「CRC3」
①2文字分割
「△P」、「PO」、 「OS」、「Sぐ」、
「ぐれ」、「れ△」
②ソート
「△P」、「PO」、
「OS」、「Sぐ」、
「ぐれ」、「れ△」
pg_bigm
キー
TID
△P
100
PO
100
OS
100
Sぐ
100
ぐれ
100
れ△
100
TID
データ
100
POSぐれ
pg_trgm
キーワード
‘POSぐれ’
INSERT
3Byte以上のtrgmは 3Byteにハッシュ変 換されます
INT値で格納される
テキスト型で格納される - 21.
21
Copyright ©2013 NTT DATA Corporation
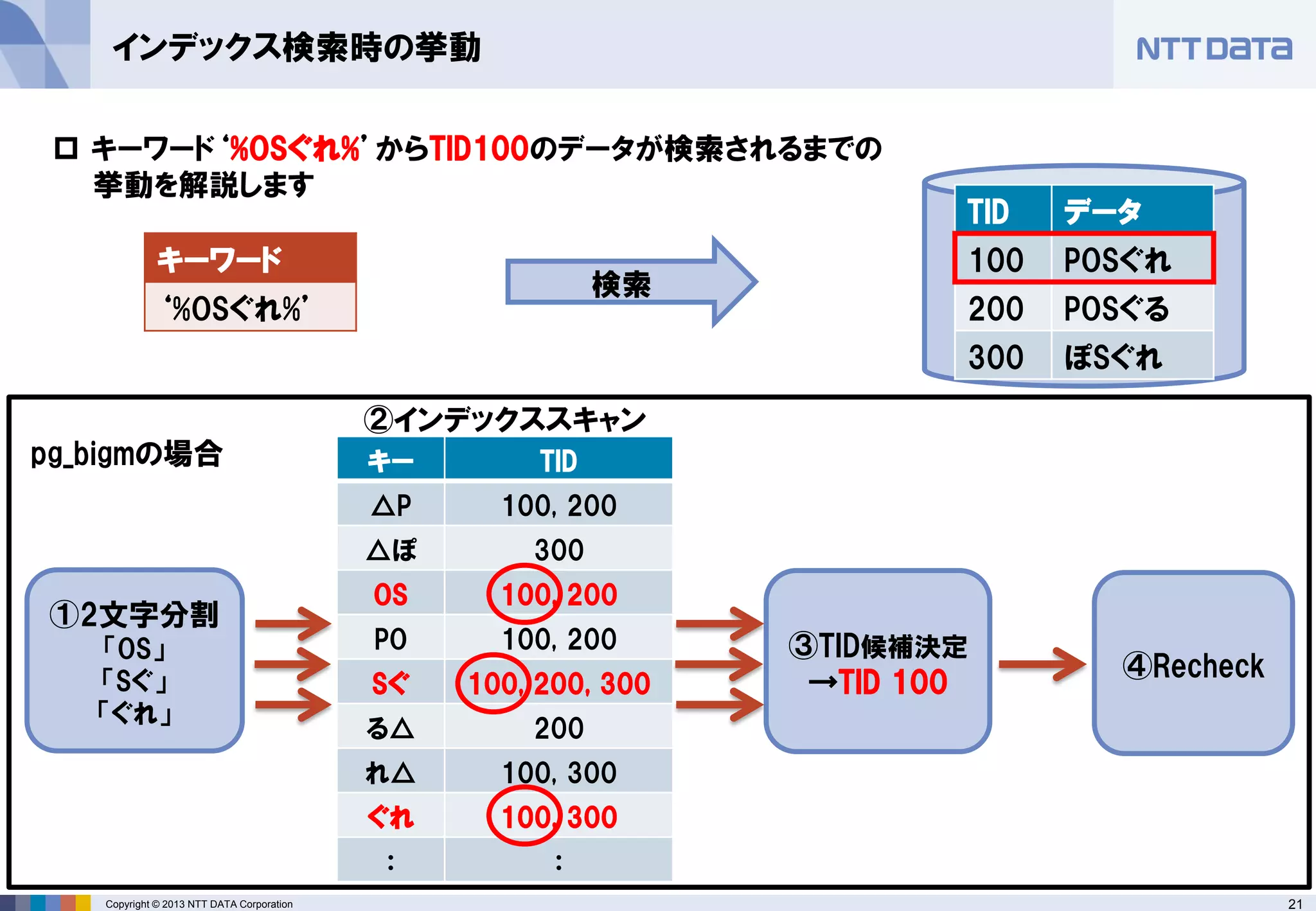
インデックス検索時の挙動
①2文字分割
「OS」
「Sぐ」
「ぐれ」
キーワード‘%OSぐれ%’からTID100のデータが検索されるまでの 挙動を解説します
②インデックススキャン
TID
データ
100
POSぐれ
200
POSぐる
300
ぽSぐれ
キー
TID
△P
100, 200
△ぽ
300
OS
100, 200
PO
100, 200
Sぐ
100, 200, 300
る△
200
れ△
100, 300
ぐれ
100, 300
:
:
③TID候補決定
→TID 100
④Recheck
検索
キーワード
‘%OSぐれ%’
pg_bigmの場合 - 22.
22
Copyright ©2013 NTT DATA Corporation
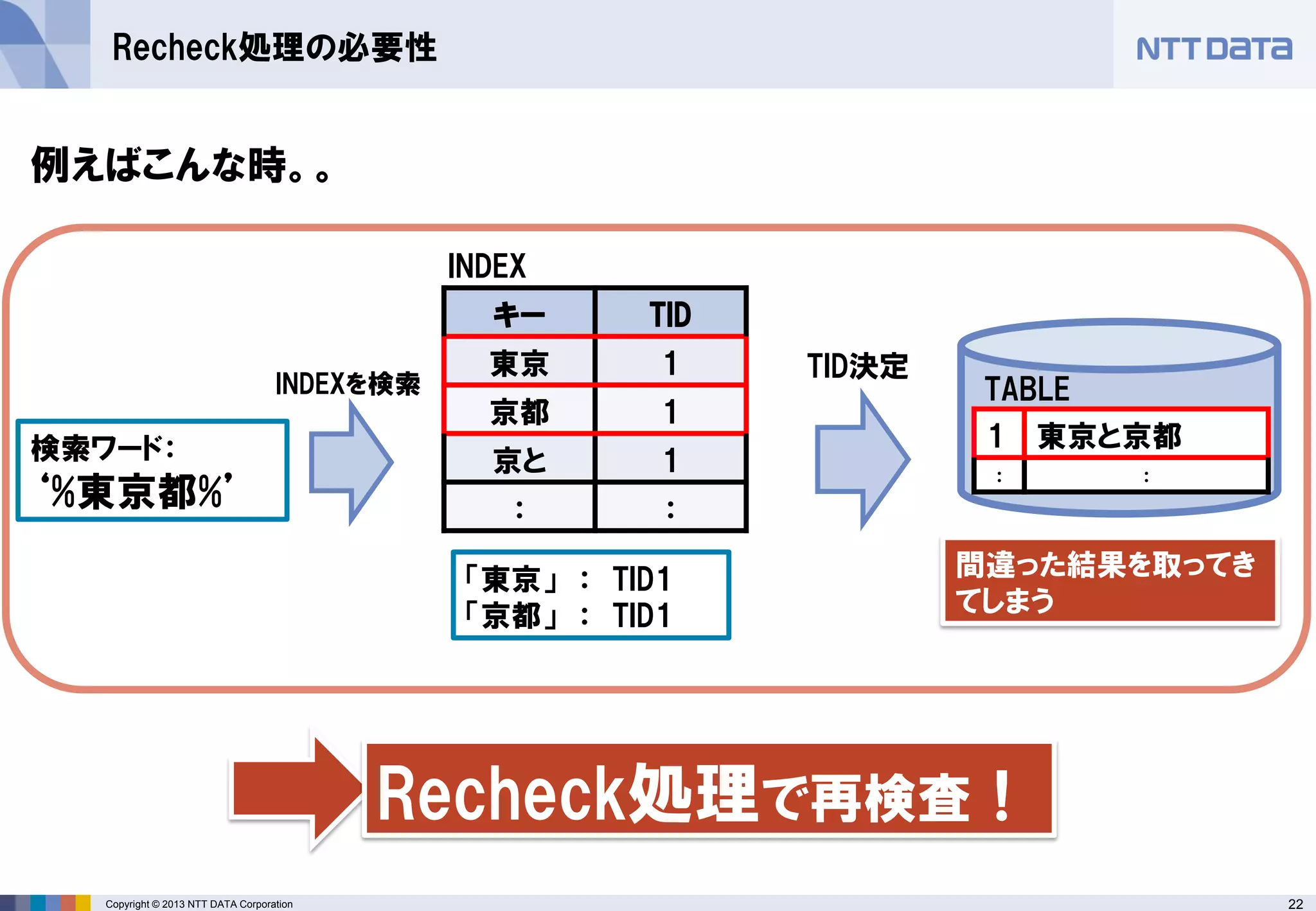
Recheck処理の必要性
キー
TID
東京
1
京都
1
京と
1
:
:
検索ワード:
‘%東京都%’
「東京」 : TID1
「京都」 : TID1
TABLE
INDEX
間違った結果を取ってき てしまう
INDEXを検索
TID決定
Recheck処理で再検査!
例えばこんな時。。
1
東京と京都
:
: - 23.
23
Copyright ©2013 NTT DATA Corporation
Recheck処理の必要性
実際に見てみる。
postgres=# EXPLAIN ANALYZE SELECT * FROM hoge WHERE col1 LIKE ‘%東京都%';
QUERY PLAN
---------------------------------------------------------
Bitmap Heap Scan on hoge (cost=16.00..20.01 rows=1 width=32) (actualtime=0.019..0.019 rows=0 loops=1)
Recheck Cond: (col1 ~~ ‘%東京都%'::text)
Rows Removed by Index Recheck: 1
-> Bitmap Index Scan on hoge_idx (cost=0.00..16.00 rows=1 width=0) (actualtime=0.011..0.011 rows=1 loops=1)
Index Cond: (col1 ~~ ‘%東京都%'::text)
Total runtime: 0.046 ms
(5 rows)
Bitmap Index Scanでは1行検出しているが、
Rechek処理により間違った結果を排除している ことがわかる。 - 24.
24
Copyright ©2013 NTT DATA Corporation
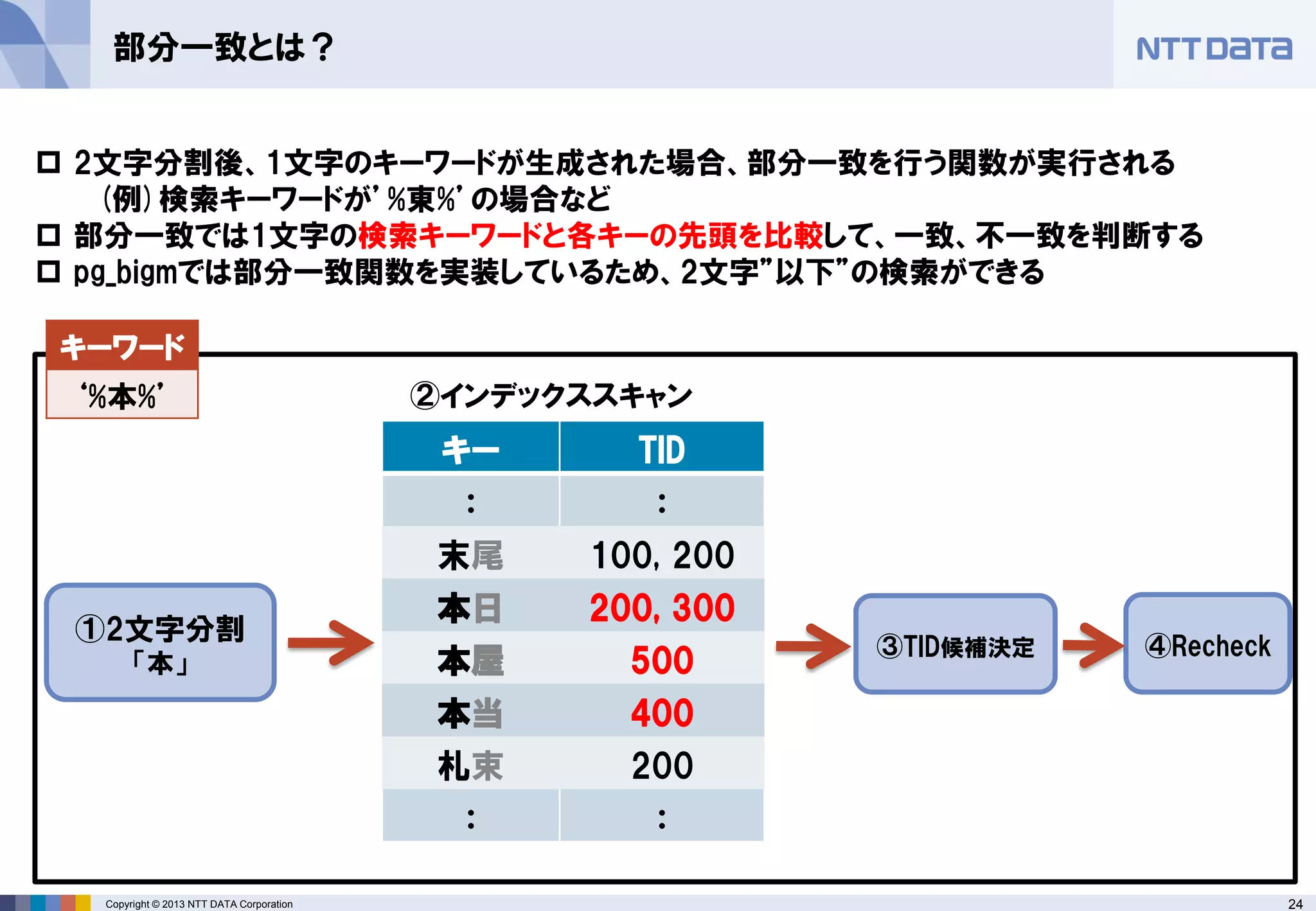
部分一致とは?
①2文字分割
「本」
②インデックススキャン
キー
TID
:
:
末尾
100, 200
本日
200, 300
本屋
500
本当
400
札束
200
:
:
③TID候補決定
④Recheck
キーワード
‘%本%’
2文字分割後、1文字のキーワードが生成された場合、部分一致を行う関数が実行される (例)検索キーワードが’%東%’の場合など
部分一致では1文字の検索キーワードと各キーの先頭を比較して、一致、不一致を判断する
pg_bigmでは部分一致関数を実装しているため、2文字”以下”の検索ができる - 25.
- 26.
26
Copyright ©2013 NTT DATA Corporation
性能測定の概要①
pg_bigmとpg_trgmを比較
pg_bigm
→2013年4月に新しく公開されたモジュール。
pg_trgm
→おなじみのPostgreSQL付属のモジュール。日本語対応を有効にして参加。
以下の項目の順番に検証を実施
1.
インデックスサイズ
→
1、2を前編で実施
2.
インデックス作成時間
3.
検索時間
→
3、4を後編で実施
4.
インデックス更新時間 - 27.
27
Copyright ©2013 NTT DATA Corporation
性能測定の概要②
テストデータ
日本語と英語が混在したテキスト
日本語 : 青空文庫より
英語 : Project Gutenbergより (単語の途中で区切られないようにしてある)
テーブル定義
CREATE TABLE hoge (col1 text);
テーブル行数
約85万行 (日本語60万行、英語25万行)
一行あたりのデータサイズ
約600Byte(日本語:200文字/行、英語:600文字/行)
テーブルサイズ
約612MB
- 28.
28
Copyright ©2013 NTT DATA Corporation
マシンスペック・ソフトウェア関連情報
項目
詳細
OS
Red Hat Enterprise Linux 6.3(64bit)
DBMS
PostgreSQL 9.2.4
項目
詳細
メーカー
DELL
モデル
PowerEdge C8220X
CPU
Xeon(R) E5-2660 2.20GHz ×2
メモリ
24GB
ディスク
HDD1本(RAID構成なし)
回転数:7200rpm、容量:1TB - 29.
29
Copyright ©2013 NTT DATA Corporation
インデックスサイズと作成時間の比較 概要
データCOPY→インデックス作成の流れで、インデックスのサイズと作成にかかる時間 を計測
全てGINインデックスを使用
それぞれ10回計測を行い、その平均値を結果とする
対象
インデックス作成クエリ
pg_bigm
CREATE INDEX hoge_idx ON hoge USING gin (col1 gin_bigm_ops);
pg_trgm
CREATE INDEX hoge_idx ON hoge USING gin (col1 gin_trgm_ops); - 30.
30
Copyright ©2013 NTT DATA Corporation
インデックスサイズの比較
今回の測定条件ではpg_bigmの方がインデックスサイズが小さいという結果になった
2文字分割の方が分割後のデータが重複する確率が高い
→重複したデータは削除される
(参考) 一つのインデックスキーの大きさの比較
pg_bigm : 英語は「3byte」 ←(データ2byte+TEXT型のヘッダ1Byte)
日本語は「(2文字のバイト数の合計)+(TEXT型のヘッダ1Byte)」
pg_trgm : 4byte(INT値で格納するため。日本語はハッシュ変換される)
(例) 「this」→インデックスキーが5つできる(pg_bigm、pg_trgm共通)
pg_bigm : 3Byte×5個 = 15Byte、 pg_trgm : 4Byte×5個 = 20Byte
対象
テーブルサイズ
インデックスサイズ
pg_bigm
612MB
1523MB
pg_trgm
2154MB - 31.
31
Copyright ©2013 NTT DATA Corporation
インデックス作成時間の比較
対象
COPY
CREATE INDEX
Total
pg_bigm
15秒
589秒
604秒
pg_trgm
785秒
800秒
今回の測定条件ではpg_bigmの方がインデックス作成時間が短いという結果になった
pg_trgmの方が書き込むサイズが大きいため (インデックスサイズ結果参照)
pg_trgmはハッシュ変換のオーバーヘッドがある - 32.
- 33.
33
Copyright ©2013 NTT DATA Corporation
まとめ
まとめ
pg_bigmでは日本語に対応している
1、2文字検索に対応している
(今回の測定条件では)pg_bigmの方がpg_trgmと比べてインデックスサ イズが小さく、作成時間も短かった
日本語2文字以下の検索をする要件 → pg_bigm一択か?
次回予定
pg_bigmの性能測定(後半)
様々な長さの検索キーワード(英語、日本語)での検索性能
インデックスの更新性能
pg_bigm独自機能やpg_bigmが提供しているパラメータの紹介
- 34.