More Related Content

PDF
pg_bigm(ピージーバイグラム)を用いた全文検索のしくみ 
PPTX
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF

PDF
pg_bigm(ピージー・バイグラム)を用いた全文検索のしくみ(後編) 
PDF

PDF
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料) 
PPTX
祝!PostgreSQLレプリケーション10周年!徹底紹介!! What's hot

PDF
Memoizeの仕組み(第41回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF
PGroonga – Make PostgreSQL fast full text search platform for all languages! 
PDF

PPTX
押さえておきたい、PostgreSQL 13 の新機能!!(Open Source Conference 2021 Online/Hokkaido 発表資料) 
PPTX
PostgreSQL 14 モニタリング新機能紹介(PostgreSQL カンファレンス #24、2021/06/08) 
PPTX
PostgreSQLの統計情報について(第26回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PPTX
9/14にリリースされたばかりの新LTS版Java 17、ここ3年間のJavaの変化を知ろう!(Open Source Conference 2021 O... 
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料) 
PPTX
PostgreSQL14の pg_stat_statements 改善(第23回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PPTX
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス... 
PDF
PostgreSQL16新機能紹介 - libpq接続ロード・バランシング(第41回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF
Inside vacuum - 第一回PostgreSQLプレ勉強会 
PDF
PGCon 2023 参加報告(第42回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF

PDF
PostgreSQL13でのレプリケーション関連の改善について(第14回PostgreSQLアンカンファレンス@オンライン) 
PPTX
VSCodeで作るPostgreSQL開発環境(第25回 PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF

PDF
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料) 
ODP
Goのサーバサイド実装におけるレイヤ設計とレイヤ内実装について考える 
PDF
Similar to pg_trgmと全文検索

PDF
PostgreSQL18新機能紹介(db tech showcase 2025 発表資料) 
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~ 
PDF
JPUGしくみ+アプリケーション勉強会(第20回) 
PPTX

PPT
20090107 Postgre Sqlチューニング(Sql編) 
PPTX
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料) 
PDF

PDF
YugabyteDBの実行計画を眺める(NewSQL/分散SQLデータベースよろず勉強会 #3 発表資料) 
PDF

PDF
データベースシステム論12 - 問い合わせ処理と最適化 
PDF
B-Treeのアーキテクチャ解説 (第49回PostgreSQLアンカンファレンス@東京 発表資料) 
PDF
Pgunconf 20121212-postgeres fdw 
PDF

PDF
2018年度 若手技術者向け講座 大量データの扱い・ストアド・メモリ管理 
PDF
アナリティクスをPostgreSQLで始めるべき10の理由@第6回 関西DB勉強会 
PDF
RailsエンジニアのためのSQLチューニング速習会 
PDF
PostgreSQL SQLチューニング入門 実践編(pgcon14j) 
PDF

PDF

PDF
More from NTT DATA OSS Professional Services

PDF
Global Top 5 を目指す NTT DATA の確かで意外な技術力 
PDF
Spark SQL - The internal - 
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~ 
PDF

PDF
HDFS Router-based federation 
PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント 
PDF
Apache Hadoopの新機能Ozoneの現状 
PDF
Distributed data stores in Hadoop ecosystem 
PDF
Structured Streaming - The Internal - 
PDF
Apache Hadoopの未来 3系になって何が変わるのか? 
PDF
Apache Hadoop and YARN, current development status 
PDF
HDFS basics from API perspective 
PDF
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~ 
PDF

PPTX

PDF
Application of postgre sql to large social infrastructure jp 
PDF
Application of postgre sql to large social infrastructure 
PDF
Apache Hadoop 2.8.0 の新機能 (抜粋) 
PDF
データ活用をもっともっと円滑に!�~データ処理・分析基盤編を少しだけ~ 
PDF
商用ミドルウェアのPuppet化で気を付けたい5つのこと pg_trgmと全文検索
- 1.
Copyright © 2013NTT DATA Corporation
2013年2月16日
株式会社NTTデータ 基盤システム事業本部
澤田 雅彦
つかってみよう”pg_trgm” やってみよう”全文検索” - 2.
2
Copyright ©2013NTT DATA Corporation
INDEX
01 全文検索とは?
02 pg_trgmってなに?
03 pg_trgmの動きを見てみよう
04 まとめ - 3.
- 4.
4
Copyright ©2013 NTT DATA Corporation
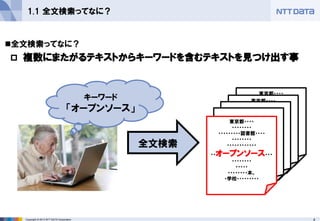
1.1 全文検索ってなに?
全文検索ってなに?
複数にまたがるテキストからキーワードを含むテキストを見つけ出す事
東京都・・・・
・・・・・・・・
・・・・・・・・・図書館・・・・
・・・・・・・・
・・・・・・・・・・・・
・・オープンソース・・・
・・・・・・・・
・・・・・
・・・・・・・・本。
・学校・・・・・・・・・
東京都・・・・
・・・・・・・・
・・・・・・・・・図書館・・・・
・・・・・・・・
・・・・・・
・・・・・・
・・オープンソース・・・
・・・・・・・・
・・・・・
・・・・・・・・本。
・学校・・・・・・・・・
東京都で・・・・
・・・・・・・・
・・・データベース・・・
・・・・・・・・
・・・・・・・・・・・・
・・・・・
・・・・・・・・
東京都・・・・
・・・・・・・・
・・・・・・・図書館・・・・
・・・・・・・・
・・・・・・・・・・・・
・・オープンソース・・・
・・・・・・・・
・・・・・
・・・・・・・・本。
・学校・・・・・・・・・
全文検索
キーワード
「オープンソース」 - 5.
5
Copyright ©2013 NTT DATA Corporation
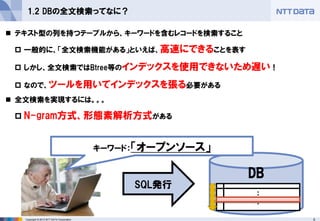
1.2 DBの全文検索ってなに?
SQL発行
DB
:
:
テキスト型の列を持つテーブルから、キーワードを含むレコードを検索すること
一般的に、「全文検索機能がある」といえば、高速にできることを表す
しかし、全文検索ではBtree等のインデックスを使用できないため遅い!
なので、ツールを用いてインデックスを張る必要がある
全文検索を実現するには。。。
N-gram方式、形態素解析方式がある
キーワード:「オープンソース」 - 6.
6
Copyright ©2013 NTT DATA Corporation
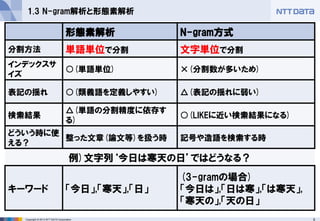
1.3 N-gram解析と形態素解析
形態素解析
N-gram方式
分割方法
単語単位で分割
文字単位で分割
インデックスサ イズ
○(単語単位)
×(分割数が多いため)
表記の揺れ
○(類義語を定義しやすい)
△(表記の揺れに弱い)
検索結果
△(単語の分割精度に依存す る)
○(LIKEに近い検索結果になる)
どういう時に使 える?
整った文章(論文等)を扱う時
記号や造語を検索する時
例)文字列‘今日は寒天の日’ではどうなる?
キーワード
「今日」,「寒天」,「日」
(3-gramの場合)
「今日は」,「日は寒」,「は寒天」, 「寒天の」,「天の日」 - 7.
7
Copyright ©2013 NTT DATA Corporation
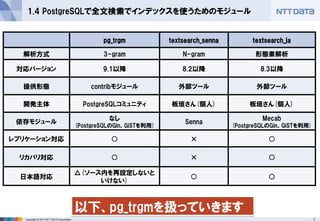
1.4 PostgreSQLで全文検索でインデックスを使うためのモジュール
pg_trgm
textsearch_senna
textsearch_ja
解析方式
3-gram
N-gram
形態素解析
対応バージョン
9.1以降
8.2以降
8.3以降
提供形態
contribモジュール
外部ツール
外部ツール
開発主体
PostgreSQLコミュニティ
板垣さん(個人)
板垣さん(個人)
依存モジュール
なし
(PostgreSQLのGin、GiSTを利用)
Senna
Mecab
(PostgreSQLのGin、GiSTを利用)
レプリケーション対応
○
×
○
リカバリ対応
○
×
○
日本語対応
△(ソース内を再設定しないと いけない)
○
○
以下、pg_trgmを扱っていきます - 8.
- 9.
9
Copyright ©2013 NTT DATA Corporation
2.1 pg_trgmとは
全文検索はPostgreSQL9.1から対応
contribモジュールとして提供
3-gram方式
GIN,GiSTインデックスに対応
レプリケーション・リカバリに対応
名前
検索
構築・更新
GIN
汎用転置インデックス
速い
遅い
GiST
汎用検索ツリー
遅い
速い - 10.
10
Copyright ©2013 NTT DATA Corporation
2.2 インストール方法
インストール方法
$ cd $PGSRC/contrib/pg_trgm
$ make
$ make install
【ビルド時の注意】
日本語対応させるためには。。。
trgm.hの #define KEEPONLYALNUM を必ずコメントアウトする! - 11.
11
Copyright ©2013 NTT DATA Corporation
2.3 動作確認
postgres=# CREATE EXTENSION pg_trgm;
postgres=# CREATE TABLE tbl (col1 text);
postgres=# CREATE INDEX idx on tbl USING gin (col1 gin_trgm_ops); ←INDEX作成
postgres=# INSERT INTO tbl VALUES ('test');
postgres=# EXPLAIN SELECT * FROM tbl WHERE col1 LIKE '%test%';
QUERY PLAN
----------------------------------------------------------- ---------
Bitmap Heap Scan on tbl (cost=16.16..26.43 rows=21 width=32)
Recheck Cond: (col1 ~~ '%test%'::text)
-> Bitmap Index Scan on idx (cost=0.00..16.16 rows=21 width=0)
Index Cond: (col1 ~~ '%test%'::text)
(4 rows) - 12.
12
Copyright ©2013 NTT DATA Corporation
2.4 インデックスを使ったとき、使わなかったとき
postgres=# EXPLAIN ANALYZE SELECT * FROM tbl WHERE col1 LIKE '%京都府%';
QUERY PLAN
---------------------------------------------------------------
Bitmap Heap Scan on tbl (cost=20.08..55.53 rows=10 width=32) (actual time=0.021..0.022 rows=3 loops=1)
Recheck Cond: (col1 ~~ '%京都府%'::text)
-> Bitmap Index Scan on idx (cost=0.00..20.07 rows=10 width=0) (actual time=0.013..0.013 rows=3 loops=1)
Index Cond: (col1 ~~ '%京都府%'::text)
Total runtime: 0.051 ms
インデックス使用
postgres=# EXPLAIN ANALYZE SELECT * FROM tbl WHERE col1 LIKE '%京都府%';
QUERY PLAN
---------------------------------------------------------------
Seq Scan on tbl (cost=0.00..1662.00 rows=10 width=32) (actual time=22.282..22.284 rows=3 loops=1)
Filter: (col1 ~~ '%京都府%'::text)
Total runtime: 22.303 ms
インデックス不使用
400倍以上の差
10万件のデータの中から、少量のデータを取り出すケースで検証。 - 13.
13
Copyright ©2013 NTT DATA Corporation
2.5 2文字以下の検索
pg_trgmは、3文字単位で区切るため、2文字以下の検索ではインデックスを効率的に使 えない。
逆にインデックスを使うと「Bitmapの全件アクセス」になるため、SeqScanより遅い。
英語の全文検索では1,2文字はストップワード(inやa)であることが多いので問題な
いのかも。。
しかし日本語では「本」、「学校」など1,2文字で全文検索をする可能性は十分ある!
postgres=# EXPLAIN ANALYZE SELECT * FROM tbl WHERE col1 LIKE '%京%';
QUERY PLAN
----------------------------------------------------------------------------------------------------- Bitmap Heap Scan on tbl (cost=938.92..2600.80 rows=99990 width=32) (actual time=96.956..139.761 rows=10000
3 loops=1)
Recheck Cond: (col1 ~~ '%京%'::text)
-> Bitmap Index Scan on idx (cost=0.00..913.92 rows=99990 width=0) (actual time=96.874..96.874 rows=1000
03 loops=1)
Index Cond: (col1 ~~ '%京%'::text)
Total runtime: 160.489 ms
(5 rows)
postgres=# EXPLAIN ANALYZE SELECT * tbl WHERE col1 LIKE '%京%';
QUERY PLAN
----------------------------------------------------------------------------------------------------
Seq Scan on tbl (cost=0.00..1662.00 rows=99990 width=32) (actual time=0.014..40.286 rows=100003 loops=1)
Filter: (col1 ~~ '%京%'::text)
Total runtime: 59.661 ms
(3 rows)
インデックスを使った方が遅い
インデックス不使用
インデックス使用 - 14.
- 15.
15
Copyright ©2013 NTT DATA Corporation
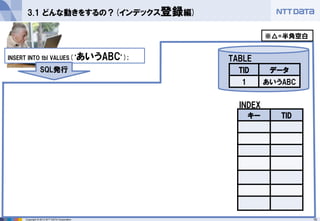
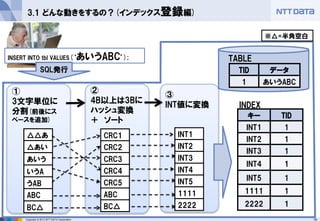
3.1 どんな動きをするの?(インデックス登録編)
INSERT INTO tbl VALUES(‘あいうABC’);
キー
TID
SQL発行
TID
データ
1
あいうABC
INDEX
TABLE
※△=半角空白 - 16.
16
Copyright ©2013 NTT DATA Corporation
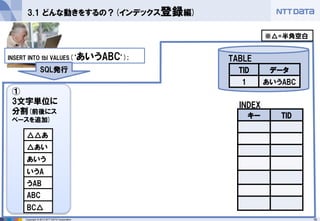
①
3文字単位に 分割(前後にス ペースを追加)
3.1 どんな動きをするの?(インデックス登録編)
INSERT INTO tbl VALUES(‘あいうABC’);
キー
TID
SQL発行
TID
データ
1
あいうABC
INDEX
TABLE
△△あ
△あい
あいう
いうA
うAB
ABC
BC△
※△=半角空白 - 17.
17
Copyright ©2013 NTT DATA Corporation
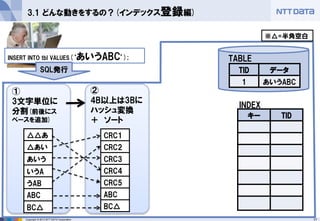
②
4B以上は3Bに ハッシュ変換
+ ソート
①
3文字単位に 分割(前後にス ペースを追加)
3.1 どんな動きをするの?(インデックス登録編)
INSERT INTO tbl VALUES(‘あいうABC’);
キー
TID
SQL発行
TID
データ
1
あいうABC
INDEX
TABLE
△△あ
△あい
あいう
いうA
うAB
ABC
BC△
CRC1
CRC2
CRC3
CRC4
CRC5
ABC
BC△
※△=半角空白 - 18.
18
Copyright ©2013 NTT DATA Corporation
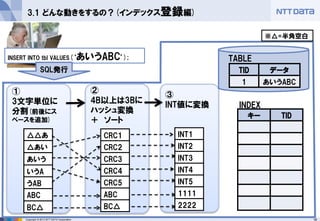
②
4B以上は3Bに ハッシュ変換
+ ソート
①
3文字単位に 分割(前後にス ペースを追加)
③
INT値に変換
3.1 どんな動きをするの?(インデックス登録編)
INSERT INTO tbl VALUES(‘あいうABC’);
キー
TID
SQL発行
TID
データ
1
あいうABC
INDEX
TABLE
△△あ
△あい
あいう
いうA
うAB
ABC
BC△
CRC1
CRC2
CRC3
CRC4
CRC5
ABC
BC△
INT1
INT2
INT3
INT4
INT5
1111
2222
※△=半角空白 - 19.
19
Copyright ©2013 NTT DATA Corporation
②
4B以上は3Bに ハッシュ変換
+ ソート
①
3文字単位に 分割(前後にス ペースを追加)
③
INT値に変換
3.1 どんな動きをするの?(インデックス登録編)
INSERT INTO tbl VALUES(‘あいうABC’);
キー
TID
INT1
1
INT2
1
INT3
1
INT4
1
INT5
1
1111
1
2222
1
SQL発行
TID
データ
1
あいうABC
INDEX
TABLE
△△あ
△あい
あいう
いうA
うAB
ABC
BC△
CRC1
CRC2
CRC3
CRC4
CRC5
ABC
BC△
INT1
INT2
INT3
INT4
INT5
1111
2222
※△=半角空白 - 20.
20
Copyright ©2013 NTT DATA Corporation
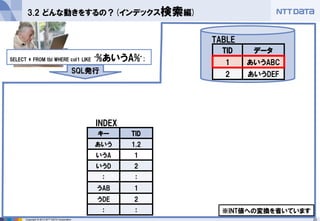
3.2 どんな動きをするの?(インデックス検索編)
SELECT * FROM tbl WHERE col1 LIKE ‘%あいうA%’;
SQL発行
TID
データ
1
あいうABC
2
あいうDEF
TABLE
※INT値への変換を省いています
キー
TID
あいう
1,2
いうA
1
いうD
2
:
:
うAB
1
うDE
2
:
:
INDEX - 21.
21
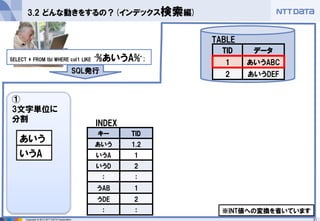
Copyright ©2013 NTT DATA Corporation
①
3文字単位に 分割
3.2 どんな動きをするの?(インデックス検索編)
SELECT * FROM tbl WHERE col1 LIKE ‘%あいうA%’;
SQL発行
TID
データ
1
あいうABC
2
あいうDEF
TABLE
あいう
いうA
※INT値への変換を省いています
INDEX
キー
TID
あいう
1,2
いうA
1
いうD
2
:
:
うAB
1
うDE
2
:
: - 22.
22
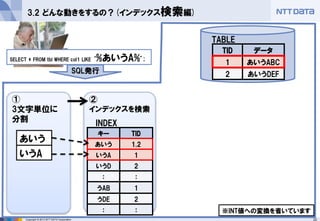
Copyright ©2013 NTT DATA Corporation
②
インデックスを検索
①
3文字単位に 分割
3.2 どんな動きをするの?(インデックス検索編)
SELECT * FROM tbl WHERE col1 LIKE ‘%あいうA%’;
キー
TID
あいう
1,2
いうA
1
いうD
2
:
:
うAB
1
うDE
2
:
:
SQL発行
TID
データ
1
あいうABC
2
あいうDEF
INDEX
TABLE
あいう
いうA
※INT値への変換を省いています - 23.
23
Copyright ©2013 NTT DATA Corporation
③
TID決定
②
インデックスを検索
①
3文字単位に 分割
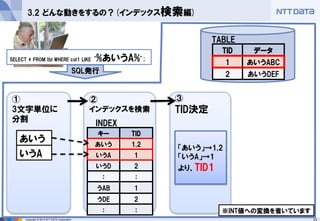
3.2 どんな動きをするの?(インデックス検索編)
SELECT * FROM tbl WHERE col1 LIKE ‘%あいうA%’;
キー
TID
あいう
1,2
いうA
1
いうD
2
:
:
うAB
1
うDE
2
:
:
SQL発行
TID
データ
1
あいうABC
2
あいうDEF
INDEX
TABLE
あいう
いうA
「あいう」→1,2
「いうA」→1
より、TID1
※INT値への変換を省いています - 24.
24
Copyright ©2013 NTT DATA Corporation
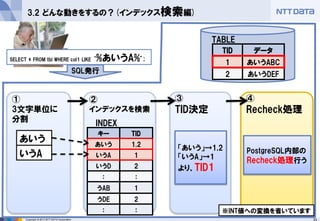
④
Recheck処理
③
TID決定
②
インデックスを検索
①
3文字単位に 分割
3.2 どんな動きをするの?(インデックス検索編)
SELECT * FROM tbl WHERE col1 LIKE ‘%あいうA%’;
キー
TID
あいう
1,2
いうA
1
いうD
2
:
:
うAB
1
うDE
2
:
:
SQL発行
TID
データ
1
あいうABC
2
あいうDEF
INDEX
TABLE
あいう
いうA
「あいう」→1,2
「いうA」→1
より、TID1
PostgreSQL内部の
Recheck処理行う
※INT値への変換を省いています - 25.
25
Copyright ©2013 NTT DATA Corporation
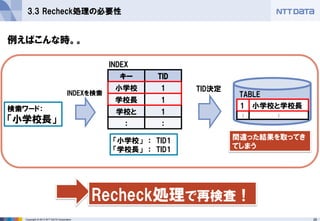
3.3 Recheck処理の必要性
キー
TID
小学校
1
学校長
1
学校と
1
:
:
検索ワード:
「小学校長」
TABLE
INDEX
Recheck処理で再検査!
例えばこんな時。。
1
小学校と学校長
:
: - 26.
26
Copyright ©2013 NTT DATA Corporation
3.3 Recheck処理の必要性
キー
TID
小学校
1
学校長
1
学校と
1
:
:
検索ワード:
「小学校長」
「小学校」 : TID1
「学校長」 : TID1
TABLE
INDEX
間違った結果を取ってき てしまう
INDEXを検索
TID決定
Recheck処理で再検査!
例えばこんな時。。
1
小学校と学校長
:
: - 27.
27
Copyright ©2013 NTT DATA Corporation
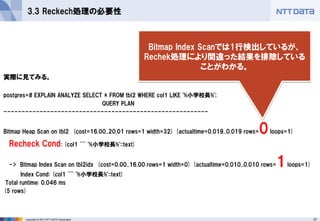
3.3 Reckech処理の必要性
実際に見てみる。
postgres=# EXPLAIN ANALYZE SELECT * FROM tbl2 WHERE col1 LIKE '%小学校長%';
QUERY PLAN
---------------------------------------------------------
Bitmap Heap Scan on tbl2 (cost=16.00..20.01 rows=1 width=32) (actualtime=0.019..0.019 rows=0 loops=1)
Recheck Cond: (col1 ~~ '%小学校長%'::text)
-> Bitmap Index Scan on tbl2idx (cost=0.00..16.00 rows=1 width=0) (actualtime=0.010..0.010 rows=1 loops=1)
Index Cond: (col1 ~~ '%小学校長%'::text)
Total runtime: 0.046 ms
(5 rows)
Bitmap Index Scanでは1行検出しているが、
Rechek処理により間違った結果を排除している ことがわかる。 - 28.
- 29.
29
Copyright ©2013 NTT DATA Corporation
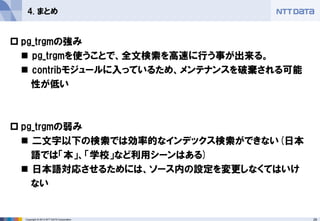
4. まとめ
pg_trgmの強み
pg_trgmを使うことで、全文検索を高速に行う事が出来る。
contribモジュールに入っているため、メンテナンスを破棄される可能
性が低い
pg_trgmの弱み
二文字以下の検索では効率的なインデックス検索ができない(日本
語では「本」、「学校」など利用シーンはある)
日本語対応させるためには、ソース内の設定を変更しなくてはいけ
ない
- 30.
- 31.
31
Copyright ©2013 NTT DATA Corporation
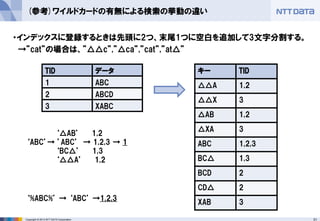
(参考)ワイルドカードの有無による検索の挙動の違い
・インデックスに登録するときは先頭に2つ、末尾1つに空白を追加して3文字分割する。
→”cat”の場合は、”△△c”,”△ca”,”cat”,”at△”
キー
TID
△△A
1,2
△△X
3
△AB
1,2
△XA
3
ABC
1,2,3
BC△
1,3
BCD
2
CD△
2
XAB
3
‘△AB’ 1,2
‘ABC’→ ’ABC’ → 1,2,3 → 1
‘BC△’ 1,3
‘△△A’ 1,2
‘%ABC%’ → ‘ABC’ →1,2,3
TID
データ
1
ABC
2
ABCD
3
XABC - 32.
32
Copyright ©2013 NTT DATA Corporation
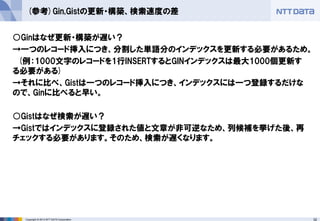
(参考)Gin,Gistの更新・構築、検索速度の差
○Ginはなぜ更新・構築が遅い?
→一つのレコード挿入につき、分割した単語分のインデックスを更新する必要があるため。
(例:1000文字のレコードを1行INSERTするとGINインデックスは最大1000個更新す る必要がある)
→それに比べ、Gistは一つのレコード挿入につき、インデックスには一つ登録するだけな ので、Ginに比べると早い。
○Gistはなぜ検索が遅い?
→Gistではインデックスに登録された値と文章が非可逆なため、列候補を挙げた後、再 チェックする必要があります。そのため、検索が遅くなります。
- 33.
33
Copyright ©2013 NTT DATA Corporation
(参考)CRC処理のソース
CRC処理のソース部分。
static void
cnt_trigram(trgm *tptr, char *str, int bytelen)
{
if (bytelen == 3)
{
CPTRGM(tptr, str);
}
else
{
pg_crc32 crc;
INIT_CRC32(crc);
COMP_CRC32(crc, str, bytelen);
FIN_CRC32(crc);
/*
* use only 3 upper bytes from crc, hope, it's good enough hashing
*/
CPTRGM(tptr, &crc);
}
}
#define INIT_CRC32(crc) ((crc) = 0xFFFFFFFF)
#define FIN_CRC32(crc) ((crc) ^= 0xFFFFFFFF)
#define COMP_CRC32(crc, data, len)¥
do { ¥
const unsigned char *__data = (const unsigned char *)(data); ¥
uint32 __len = (len); ¥
¥
while (__len-- > 0) ¥
{ ¥
int __tab_index = ((int) ((crc) >> 24) ^ *__data++) & 0xFF; ¥
(crc) = pg_crc32_table[__tab_index] ^ ((crc) << 8); ¥
} ¥
} while (0) - 34.
34
Copyright ©2013 NTT DATA Corporation
(参考)KEEPONLYALNUMをコメントアウトしなかったら
○trgm_op.cのソースの一部
#ifdef KEEPONLYALNUM
#define iswordchr(c) (t_isalpha(c) || t_isdigit(c)) ←英数字の時にTrue
#else
#define iswordchr(c) (!t_isspace(c)) ←スペースでないときにTrue
#endif
static char *
○trgm_gin.cのソースの一部(データから空白を除いて文字の塊を見つけるところ。例:’today is sunny’→’today’,’is’,’sunny’)
find_word(char *str, int lenstr, char **endword, int *charlen)
{
char *beginword = str;
while (beginword - str < lenstr && !iswordchr(beginword))
beginword += pg_mblen(beginword);
if (beginword - str >= lenstr)
return NULL;
*endword = beginword;
*charlen = 0;
while (*endword - str < lenstr && iswordchr(*endword))
{
*endword += pg_mblen(*endword);
(*charlen)++;
}
return beginword;
}














![33
Copyright © 2013 NTT DATA Corporation
(参考)CRC処理のソース
CRC処理のソース部分。
static void
cnt_trigram(trgm *tptr, char *str, int bytelen)
{
if (bytelen == 3)
{
CPTRGM(tptr, str);
}
else
{
pg_crc32 crc;
INIT_CRC32(crc);
COMP_CRC32(crc, str, bytelen);
FIN_CRC32(crc);
/*
* use only 3 upper bytes from crc, hope, it's good enough hashing
*/
CPTRGM(tptr, &crc);
}
}
#define INIT_CRC32(crc) ((crc) = 0xFFFFFFFF)
#define FIN_CRC32(crc) ((crc) ^= 0xFFFFFFFF)
#define COMP_CRC32(crc, data, len)¥
do { ¥
const unsigned char *__data = (const unsigned char *)(data); ¥
uint32 __len = (len); ¥
¥
while (__len-- > 0) ¥
{ ¥
int __tab_index = ((int) ((crc) >> 24) ^ *__data++) & 0xFF; ¥
(crc) = pg_crc32_table[__tab_index] ^ ((crc) << 8); ¥
} ¥
} while (0)](https://image.slidesharecdn.com/pgtrgm-141001030605-phpapp02/85/pg_trgm-33-320.jpg)
